Video-XL —— 智源联合多所高校推出的开源超长视觉理解模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Video-XL主要介绍
Video-XL是由智源研究院联合上海交通大学、中国人民大学、北京大学等多所高校开发的一款超长视频理解大模型。该模型旨在处理小时级长视频,并凭借其高达95%的准确率,标志着长视频理解技术的新纪元。

Video-XL功能特点
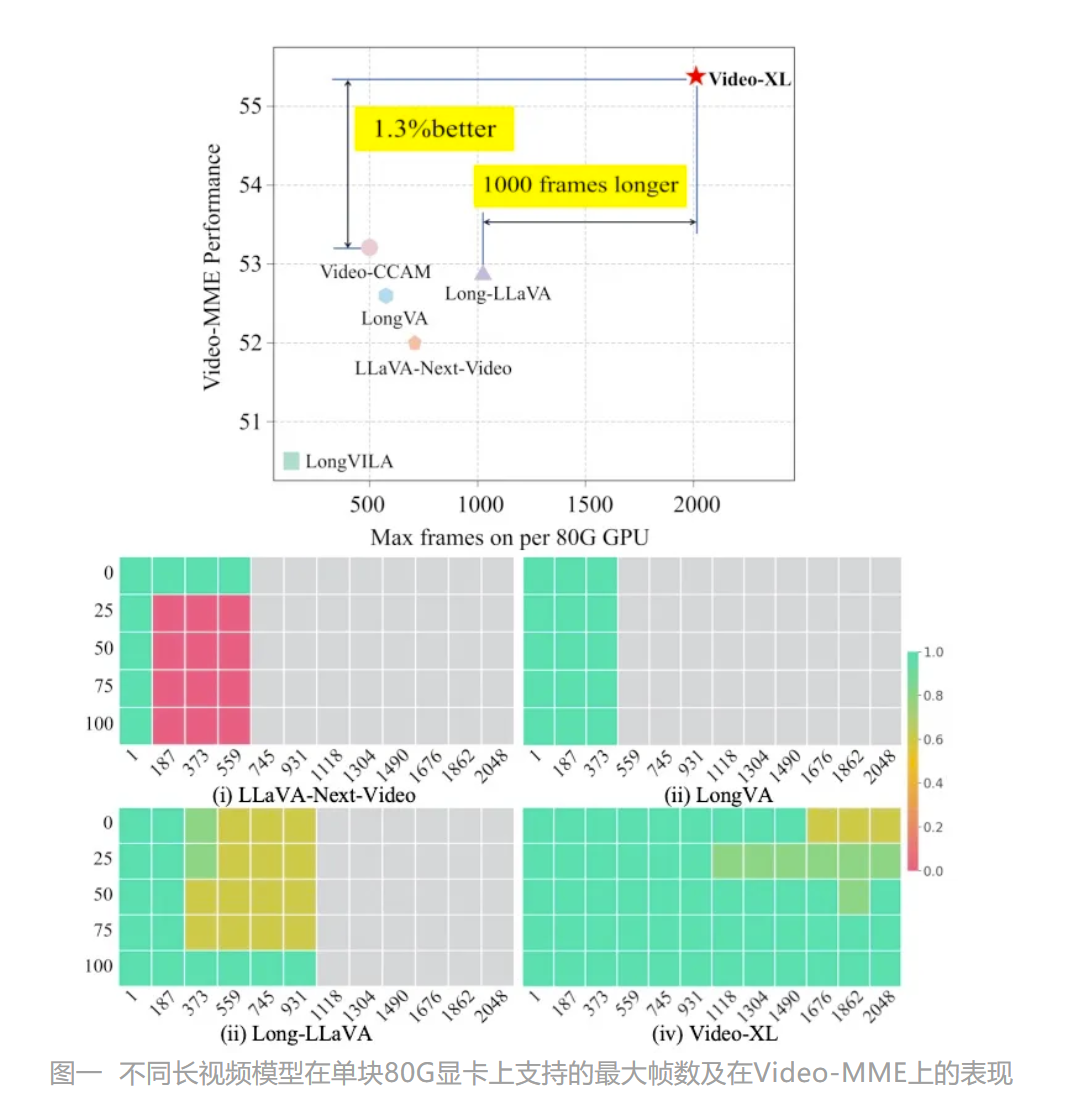
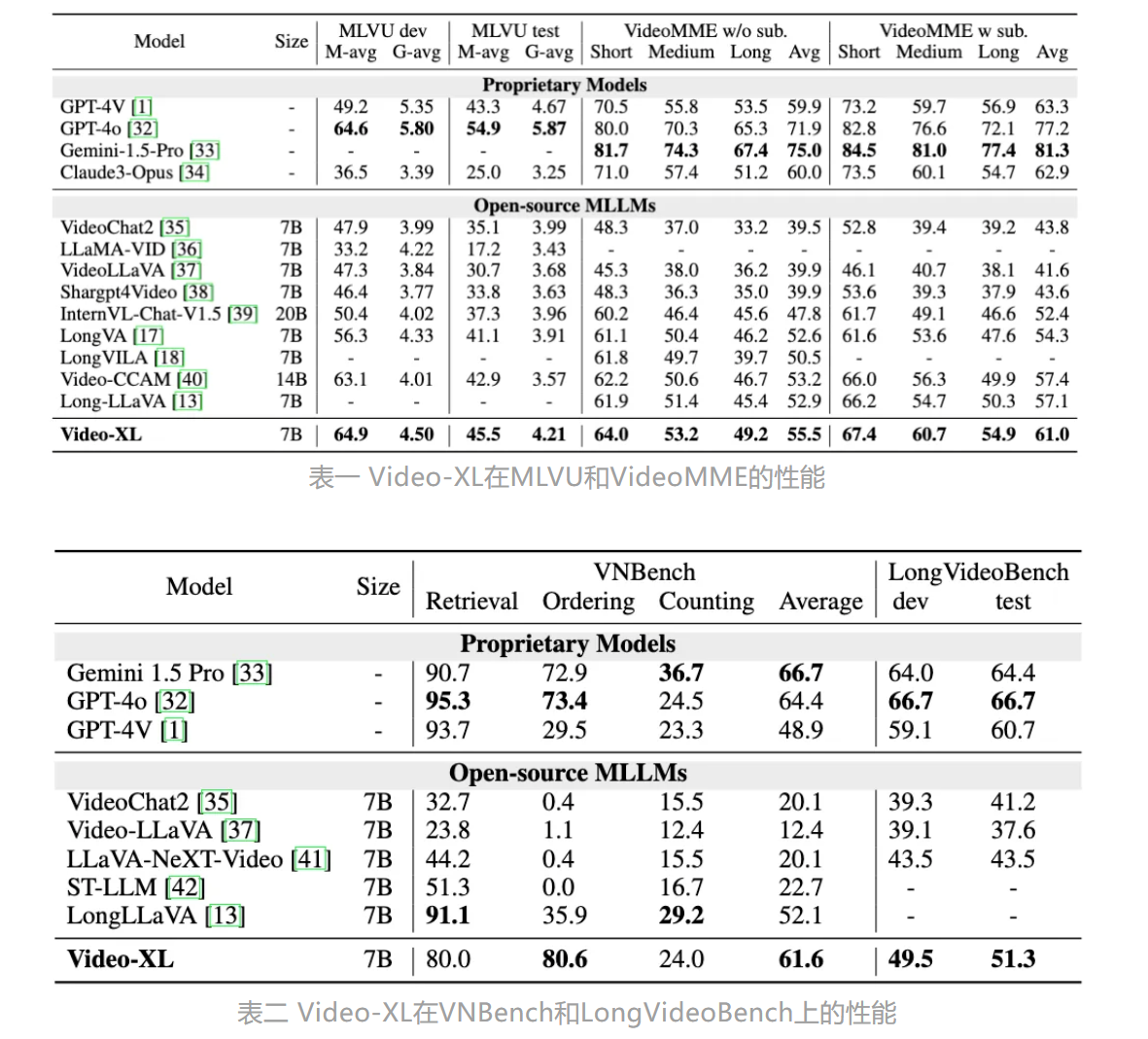
- 全面的长视频理解能力:在MLVU、VideoMME、VNBench和LongVideoBench等数据集上取得了7B模型中的领先性能。
- 高效的长视觉上下文处理:在单个80G GPU上处理2048帧的视频,并在“针堆中找针”的评估中达到了近95%的准确率。
- 适应复杂场景:在电影总结、监控异常检测和广告放置识别等实际应用场景中表现出色。
Video-XL优缺点
-
优点:
- 高效处理长视频:仅需一块80G显存的显卡即可处理2048帧输入,对小时级长度视频进行采样。
- 准确率高:在视频“海中捞针”任务中取得了接近95%的准确率。
- 广泛的应用场景:适用于电影摘要、监控异常检测和广告投放识别等实际应用场景。
-
缺点:
- 目前尚未发现明显的缺点,但随着技术的不断发展,可能会有新的挑战和限制出现。
如何使用Video-XL
使用Video-XL需要先进行安装和配置。安装指南通常包括创建新的conda环境、安装必要的Python包等步骤。此外,Video-XL通过Hugging Face平台提供了示例代码,用户可以使用这些代码进行预训练和微调。对于评估模型性能,可以使用特定的评估工具和脚本。
Video-XL训练方法
Video-XL在训练过程中使用了大量高质量多模态数据集,包括单图像数据、多图像数据和视频数据。通过预训练和微调阶段,模型能够处理各种格式的多模态数据,并实现对长视频的高效理解。
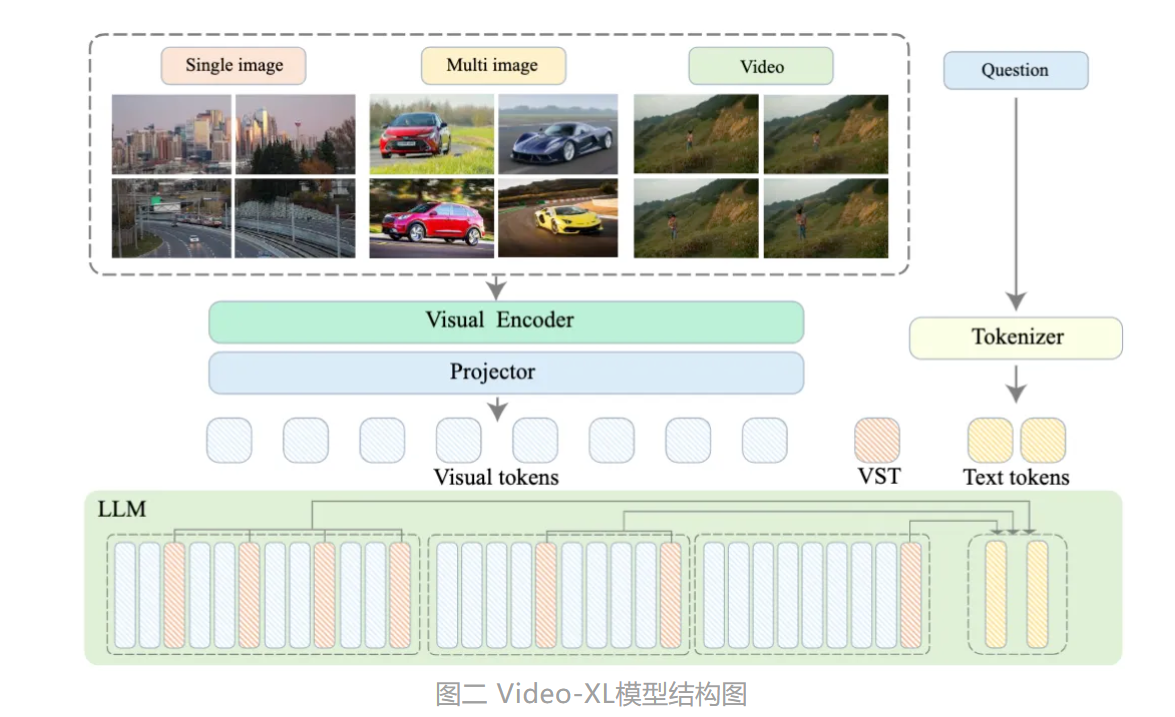
Video-XL框架结构
Video-XL的整体模型结构和主流的MLLMs结构相似,主要由视觉编码器(如CLIP)、视觉-语言映射器(如2-layer MLP)以及语言模型(如Qwen-7B)构成。特别之处在于,为了处理各种格式的多模态数据(单图、多图和视频),Video-XL建立了一个统一的视觉编码机制。
Video-XL创新点
- 视觉上下文隐空间压缩机制:通过引入视觉摘要标记(VST),Video-XL实现了对长视觉序列的无损压缩,提高了处理效率和准确性。
- 多模态数据融合:成功地将视觉和语言信息进行有效融合,提升了模型对复杂场景的理解能力。
Video-XL评估标准
Video-XL在多个主流长视频理解基准评测的多项任务中均排名第一,包括MLVU、VideoMME、VNBench和LongVideoBench等数据集。此外,还通过视频“海中捞针”任务等实际应用场景来评估其处理超长上下文的能力。
Video-XL影响
Video-XL的推出不仅标志着长视频理解技术的重大突破,也为未来AI在影视、广告等领域的应用铺平了道路。其开源代码促进了全球多模态视频理解研究社区的合作和技术共享。
Video-XL项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
