1月30日·DeepSeek陷“数据偷窃”风波,美国各界反应强烈
1月30日·周四 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在[图片]这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
DeepSeek陷“数据偷窃”风波,美国各界反应强烈
美国科技界与政府近期对DeepSeek的指控与行动引发关注。特朗普的AI事务主管David Sacks声称DeepSeek利用OpenAI模型输出数据开发自身技术,微软研究人员也表示与DeepSeek相关人物曾大规模提取OpenAI数据。美国海军提醒人员禁用DeepSeek模型,意大利下架其APP。微软和OpenAI正调查DeepSeek是否未经授权获取数据。Anthropic CEO Dario Amodei更是呼吁加强芯片出口管制,认为DeepSeek的进展凸显了美国对中国芯片管制的必要性。DeepSeek以较低成本开发出高性能模型,引发美国对自身AI领先地位的担忧。来源:微信公众号【新智元】
五角大楼启动90天AI计划,加速军事应用落地
美国五角大楼正式启动90天AI计划,旨在通过实验评估生成式AI在现实军事场景中的作战潜力,特别是针对高科技对手(如中国)的战略应用。该计划由美国印太司令部主导,重点聚焦海军应用,目标是开发能够彻底改变军事指挥官处理战场信息、了解环境和发布命令的AI作战原型。五角大楼与Anduril、Palantir等科技公司合作,利用其先进AI解决方案提升军事决策效率。然而,AI在军事系统中的应用也面临算力不足、潜在风险和军方文化转变等挑战。此次计划标志着美国在军事领域对AI的深度依赖,未来可能进一步拓展AI应用范围并迭代流程。来源:微信公众号【新智元】

清华大学计算机系长聘教授翟季冬在《智者访谈》中深入剖析了 DeepSeek 实现百倍算力效能提升的关键因素。翟季冬指出,DeepSeek 的成功主要归功于算法层面的创新,如采用新的 MoE 架构,通过共享专家和细粒度路由专家的组合,提高参数效率并优化负载均衡。在系统软件层面,DeepSeek 通过精细化的系统工程优化,如双向流水并行机制、混合精度计算和低精度通信策略,显著降低了训练成本。翟季冬强调,在中国面临算力资源挑战的背景下,系统软件创新是产业突围的关键。他呼吁建立完整的基础软件体系,以充分挖掘硬件的极致性能。此外,他还探讨了中美硬件差异下的软件适配策略,以及如何通过系统软件优化应对未来大模型训练中的挑战。来源:微信公众号【机器之心】
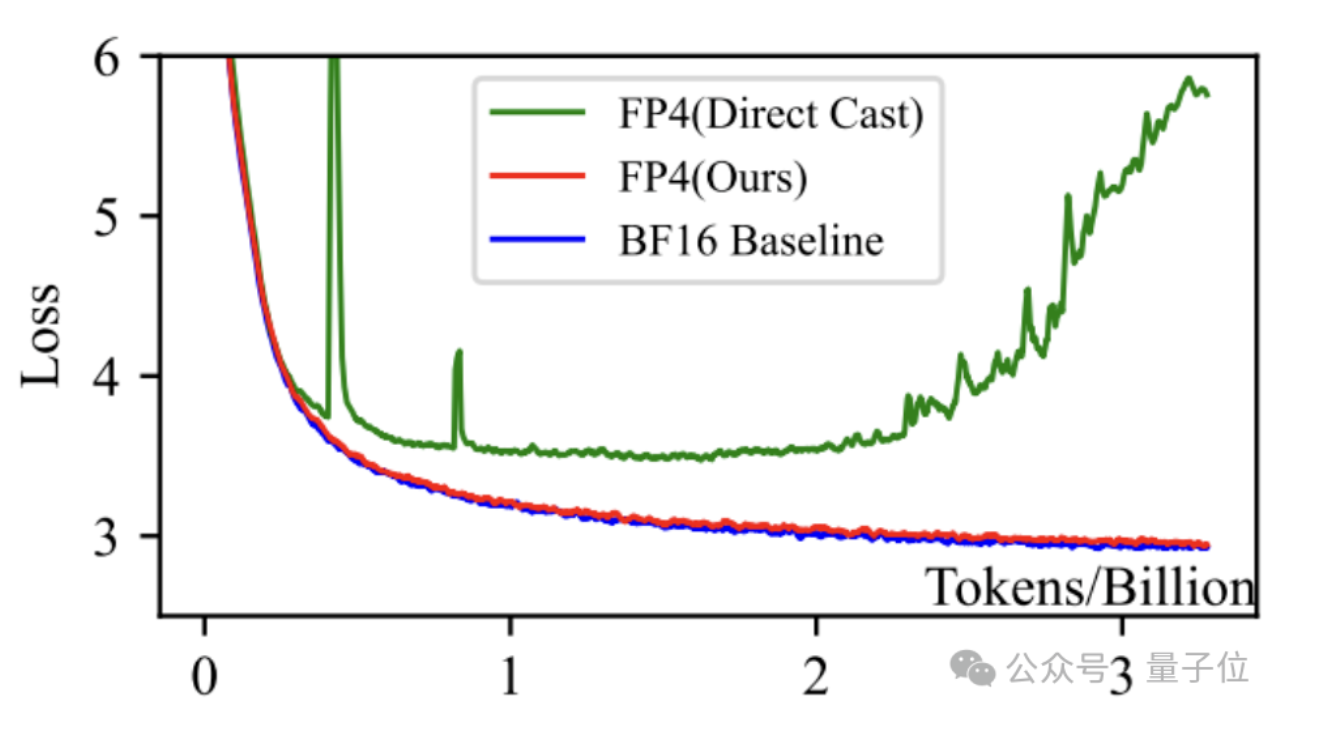
微软推出首个FP4训练框架,大模型训练成本大幅降低
微软研究院推出了首个FP4精度的大模型训练框架,能够在相同超参数设置下达到与FP8及BF16相当的训练效果。该框架通过在FP8 TensorCore上模拟实现FP4精度,支持最高130亿参数规模的模型训练,训练Tokens数量可达千亿级别。该框架采用定制化的FP4矩阵乘法CUDA内核,使用E2M1的FP4格式,并针对权重矩阵和激活矩阵采取不同粒度的量化策略。此外,还提出了可微分梯度估计方法和离群点削峰补偿策略,以解决量化训练中的问题。该框架由微软亚洲研究院和SIGMA团队打造,第一作者为中科大博士生Ruizhe Wang。这一成果有望进一步降低大模型训练的存储和计算资源需求,推动AI技术的发展。来源:微信公众号【量子位】
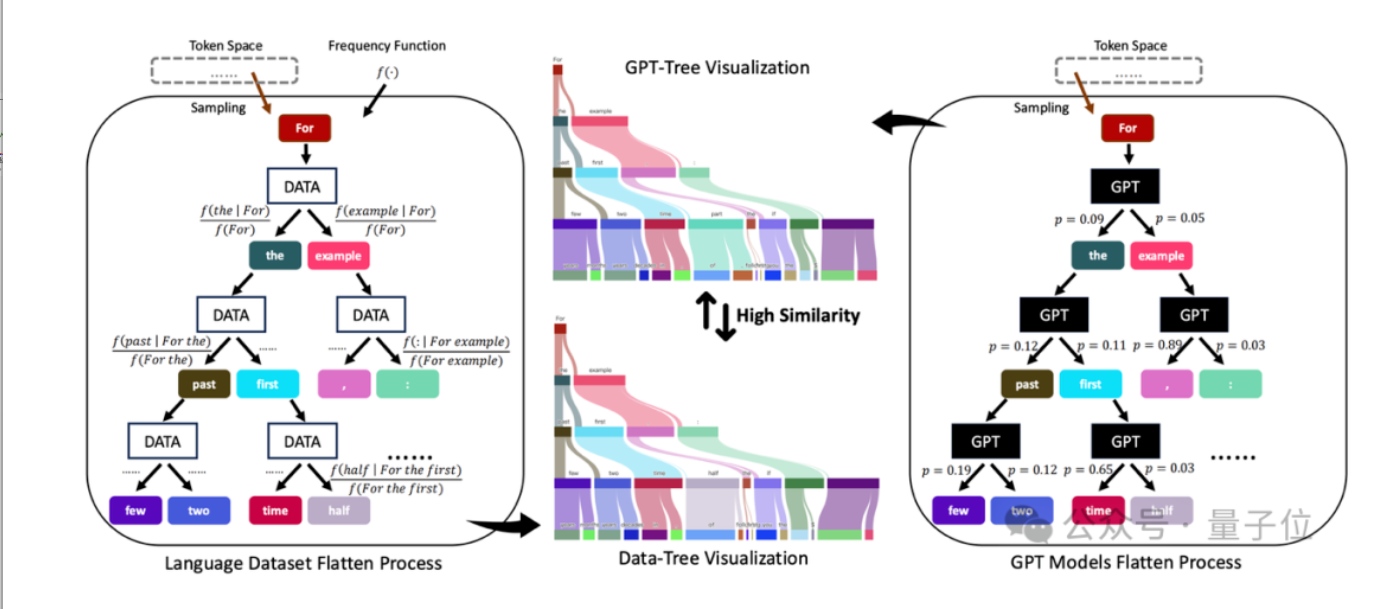
北大团队用蒙特卡洛语言树解读GPT,揭示大模型推理新机制
北京大学课题组提出了一种新的视角来分析大模型的推理机制,将语言数据集和GPT模型分别展开为“Data-Tree”和“GPT-Tree”。研究发现,大模型拟合训练数据的本质是寻求更有效的数据树近似方法,且推理过程更可能是概率模式匹配而非形式推理。通过可视化不同GPT模型的树形结构,研究人员发现模型规模越大,其结构越接近数据树,超过87%的GPT输出token可被数据树召回。此外,该视角还能解释token-bias现象和模型幻觉问题,以及思维链提升模型表现的原理。这一研究为理解大模型的内部机制提供了新的理论基础,也为优化模型设计提供了方向。来源:微信公众号【量子位】
相关文章
