Migician —— 北交大联合清华、华中科大推出的多模态视觉定位模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Migician 介绍
Migician是北交大联合清华NLP孙茂松团队、华中科大共同推出的多模态视觉定位模型,旨在解决传统视觉定位任务局限于单张图像的问题,将视觉定位能力拓展至多图像应用场景。


功能特点
-
多模态视觉定位:
- Migician支持任意形式的多图定位(Multi-image Grounding, MIG),能够处理包含文本描述和多张图像的任务,精准定位目标物体。
-
大规模训练数据集:
- 设计了大规模训练数据集MGrounding-630k,用于训练和优化Migician模型,提升其在多模态视觉定位任务上的表现。
-
端到端的解决方案:
- 提供了从输入查询(文本描述和多张图像)到输出目标物体位置的端到端解决方案,简化了多模态视觉定位任务的流程。
-
灵活性与泛化性:
- 通过高质量的MIG指令微调数据训练,Migician模型具备较高的灵活性和泛化性,能够处理不同形式的多模态视觉定位任务。
优缺点
优点:
-
多图定位能力:
- 突破了传统视觉定位任务局限于单张图像的限制,实现了对多张图像中目标物体的精准定位。
-
大规模数据集支持:
- 设计了大规模训练数据集MGrounding-630k,为模型的训练和优化提供了丰富的数据支持。
-
端到端解决方案:
- 提供了从输入到输出的端到端解决方案,简化了任务流程,提高了效率。
-
高灵活性与泛化性:
- 通过高质量的MIG指令微调数据训练,模型具备较高的灵活性和泛化性,能够处理不同形式的多模态视觉定位任务。
缺点:
-
计算复杂度:
- 处理多张图像和多模态信息可能增加计算复杂度,对硬件资源要求较高。
-
数据依赖性:
- 模型的性能依赖于训练数据集的质量和规模,需要不断收集和优化训练数据。
如何使用
由于Migician是一个专业的多模态视觉定位模型,其使用通常涉及较复杂的技术流程和算法实现。一般来说,使用Migician模型进行多模态视觉定位任务可能包括以下几个步骤:
-
数据准备:
- 准备包含文本描述和多张图像的数据集,用于模型的训练和测试。
-
模型训练:
- 使用MGrounding-630k等大规模训练数据集对Migician模型进行训练,优化模型参数。
-
任务执行:
- 输入查询(文本描述和多张图像),利用训练好的Migician模型进行多模态视觉定位任务,输出目标物体的位置信息。
-
结果评估:
- 使用评估基准(如MIG-Bench)对模型的表现进行评估,验证模型的性能和可靠性。

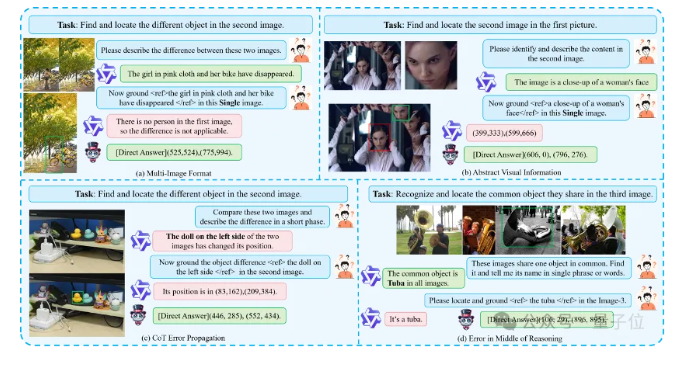
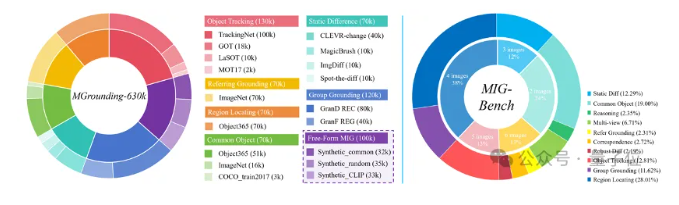
框架结构
Migician模型的框架结构包括以下几个部分:
-
输入层:
- 接收文本描述和多张图像作为输入。
-
特征提取层:
- 对文本描述进行自然语言处理,提取语义特征;对图像进行视觉处理,提取视觉特征。
-
多模态融合层:
- 将提取的语义特征和视觉特征进行融合,形成多模态特征表示。
-
定位层:
- 利用融合后的多模态特征表示,在图像中精准定位目标物体。
-
输出层:
- 输出目标物体的位置信息。
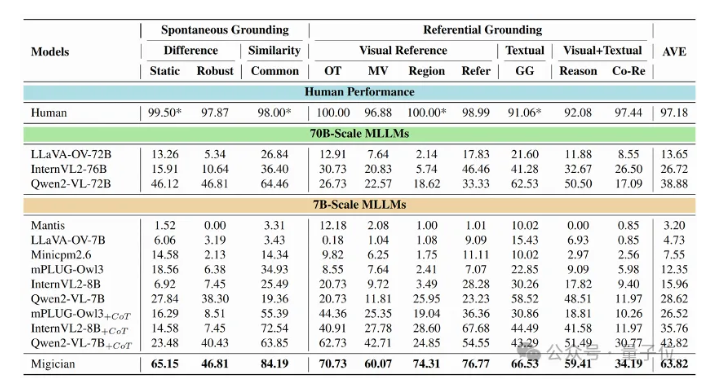

创新点
-
多图定位新范式:
- 提出了多模态视觉定位的新范式,将视觉定位能力拓展至多图像应用场景。
-
大规模训练数据集:
- 设计了大规模训练数据集MGrounding-630k,为模型的训练和优化提供了丰富的数据支持。
-
端到端的解决方案:
- 提供了从输入到输出的端到端解决方案,简化了多模态视觉定位任务的流程。
-
灵活性与泛化性:
- 通过高质量的MIG指令微调数据训练,模型具备较高的灵活性和泛化性,能够处理不同形式的多模态视觉定位任务。
评估标准
评估Migician模型在多模态视觉定位任务上的表现时,可以采用以下标准:
-
定位准确率:
- 评估模型在测试数据集上的定位准确率,即正确定位目标物体的比例。
-
召回率与精确率:
- 评估模型在测试数据集上的召回率和精确率,以全面衡量模型的性能。
-
处理速度:
- 评估模型在处理多模态视觉定位任务时的速度,包括特征提取、多模态融合和定位等步骤的时间消耗。
-
鲁棒性:
- 评估模型在不同场景和条件下的鲁棒性,包括对噪声、遮挡和光照变化等因素的敏感性。
应用领域
Migician模型可以应用于多个领域,包括但不限于:
-
机器人导航与抓取:
- 在机器人导航和抓取任务中,利用Migician模型对多张图像中的目标物体进行精准定位,提高机器人的自主性和效率。
-
智能监控与安防:
- 在智能监控和安防领域,利用Migician模型对多张监控图像中的目标物体进行识别与定位,提高监控系统的智能化水平。
-
医疗影像分析:
- 在医疗影像分析领域,利用Migician模型对多张医学图像中的病变区域进行定位与识别,辅助医生进行诊断和治疗。
项目地址
论文地址:https://arxiv.org/abs/2501.05767
项目代码:https://github.com/thunlp/Migician
项目页面:https://migician-vg.github.io/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
