Instella——AMD开源的30亿参数系列语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
模型介绍
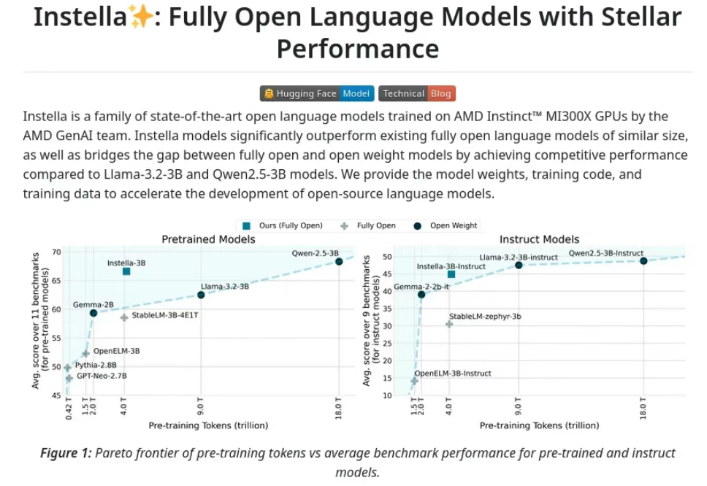
Instella是AMD推出的系列30亿参数的开源语言模型。模型完全从零开始在AMD Instinct™ MI300X GPU上训练而成,基于自回归Transformer架构,包含36个解码器层和32个注意力头,支持最长4096个标记的序列。Instella经过多阶段训练,包括大规模预训练、监督微调和偏好优化,提升自然语言理解、指令跟随和对话能力。Instella在多个基准测试中超越现有的开源模型,与最先进的开源权重模型具有竞争力。AMD完全开源Instella的模型权重、训练配置、数据集和代码,促进AI社区的合作与创新。

功能特点
- 自然语言理解:Instella能够理解复杂的自然语言文本,处理各种语言任务,如问答、文本生成和语义分析。
- 指令跟随:基于监督微调(SFT)和直接偏好优化(DPO),Instella能够准确理解和执行用户指令,生成符合人类偏好的回答。
- 多轮对话能力:支持多轮交互,根据上下文进行连贯的对话。
- 问题解决能力:在数学问题、逻辑推理和知识问答等任务上表现出色。
- 多领域适应性:基于多样化的训练数据,适应多种领域,如学术、编程、数学和日常对话等。
优缺点
优点:
- 高性能:在多个基准测试中超越现有的开源模型,与最先进的开源权重模型具有竞争力。
- 完全开源:模型权重、训练配置、数据集和代码全部公开,促进AI社区的合作与创新。
- 高效训练:采用FlashAttention-2、Torch Compile和bfloat16混合精度训练,优化内存使用和计算效率。
- 低成本:基于AMD Instinct MI300X GPU集群,训练成本仅为同类闭源模型的20%。
缺点:
目前尚未发现Instella模型明显的缺点,但随着技术的发展和应用场景的拓展,未来可能会有新的挑战和改进空间。
如何使用
-
安装依赖:
- 根据操作系统安装PyTorch。
- 对于AMD GPU,可以从rocm/pytorchdocker开始。
-
从源码安装:
bash复制代码git clone https://github.com/AMD-AIG-AIMA/Instella.git cd Instella # 在MI300X上安装Flash-Attention GPU_ARCH=gfx942 MAX_JOBS=$(nproc) pip install git+https://github.com/Dao-AILab/flash-attention.git -v # 安装其他依赖 pip install -e .[all] -
示例用法:
python复制代码from transformers import AutoModelForCausalLM, AutoTokenizer checkpoint = “amd/Instella-3B-Instruct” tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map=“auto”, trust_remote_code=True) prompt = [{“role”: “user”, “content”: “What are the benefits of open-source AI research?”}] inputs = tokenizer.apply_chat_template(prompt, add_generation_prompt=True, return_tensors=‘pt’) tokens = model.generate(inputs.to(model.device), max_new_tokens=1024, temperature=0.8, do_sample=True) print(tokenizer.decode(tokens[0], skip_special_tokens=False)) -
使用TRL进行聊天:
bash复制代码pip install trl trl chat –model_name_or_path amd/Instella-3B-Instruct –trust_remote_code –max_new_tokens 1024
框架结构
-
Transformer架构:Instella基于自回归Transformer架构,包含36个解码器层,每层有32个注意力头,支持最长4096个标记的序列长度。
-
多阶段训练:
- 大规模预训练:使用4.065万亿标记的数据,建立基础语言理解能力。
- 监督微调(SFT):使用高质量的指令-响应对数据进行微调,提升指令跟随能力。
- 直接偏好优化(DPO):基于人类偏好数据对模型进行优化,使输出更符合人类价值观。
创新点
- 完全开源:Instella是首个完全开源的30亿参数级语言模型,包括模型权重、训练配置、数据集和代码,推动AI社区的合作与创新。
- 高效训练技术:采用FlashAttention-2、Torch Compile和bfloat16混合精度训练,优化内存使用和计算效率,提高训练速度。
- 分布式训练:基于完全分片数据并行(FSDP)技术,实现大规模集群训练,提升训练效率。
评估标准
Instella的性能评估主要基于多个基准测试,如MMLU数学推理测试、GSM8K数学题测试等。在这些测试中,Instella表现出色,超越了现有的开源模型,与最先进的开源权重模型具有竞争力。
应用领域
Instella适用于智能客服、内容创作、教育辅导等多个领域,能够为用户提供自然、流畅的语言交互体验。
项目地址
Instella的开源项目地址如下:
- GitHub:https://github.com/AMD-AIG-AIMA/Instella
- Hugging Face:https://huggingface.co/amd/Instella-3B
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
