Qwen2.5-Omni —— 阿里开源的端到端多模态模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
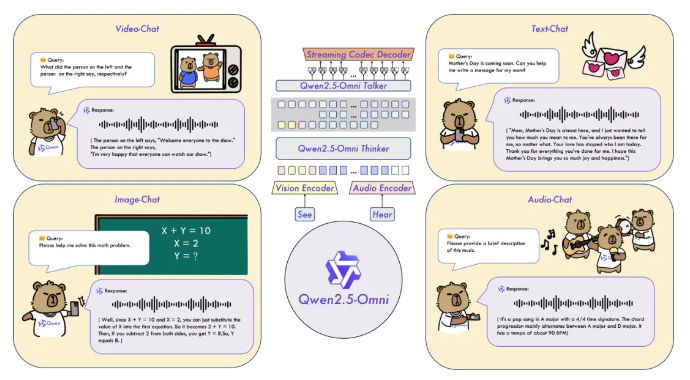
Qwen2.5-Omni是阿里巴巴发布并开源的端到端多模态大模型,属于通义千问系列。它能够同时处理文本、图像、音频和视频等多种输入形式,并实时生成文本与自然语音合成输出。Qwen2.5-Omni以接近人类的多感官方式“立体”认知世界,实现了全模态智能交互。
功能特点
- 多模态处理能力:支持文本、图像、音频和视频等多种输入,能够跨模态理解并生成相应的输出。
- 实时生成能力:通过流式处理方式,实时生成文本与自然语音响应,实现高效的多模态交互。
- 情绪识别功能:能够通过音视频识别情绪,为复杂任务提供更智能、更自然的反馈与决策。
- 小尺寸高性能:以7B的参数规模实现了全球最强的全模态优异性能,大幅降低全模态大模型的产业应用门槛。
优缺点
优点:
- 创新架构:采用Thinker-Talker双核架构,实现了实时语义理解与语音生成的高效协同。
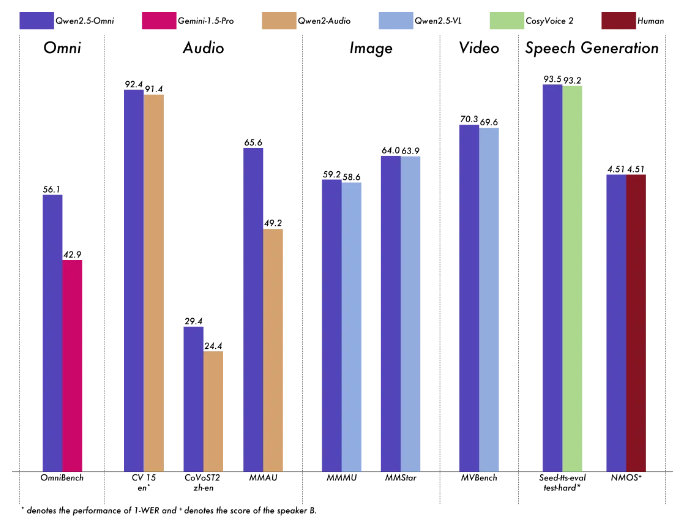
- 卓越性能:在权威的多模态融合任务OmniBench等测评中刷新业界纪录,远超同类模型。
- 广泛应用:支持手机等终端智能硬件部署,适用于多种应用场景。
缺点:
- 技术门槛:尽管模型已开源,但实现高效的多模态交互仍需要一定的技术实力。
- 数据依赖:模型性能依赖于训练数据的质量和数量,需要不断收集和标注新的数据集。
如何使用
- 下载模型:从阿里官方或开源社区(如Hugging Face、ModelScope、DashScope和GitHub)下载Qwen2.5-Omni的预训练模型和相关代码。
- 准备数据:根据任务需求准备文本、图像、音频和视频数据,并进行预处理。
- 模型推理:使用准备好的数据输入模型进行推理,生成相应的输出。
- 部署应用:将模型部署到目标设备上,如手机、服务器等,实现实时多模态交互。
框架结构
Qwen2.5-Omni采用Thinker-Talker双核架构:
- Thinker模块:如同大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应文本内容。
- Talker模块:类似发声器官,以流式方式接收Thinker实时输出的语义表征与文本,流畅合成离散语音单元。
创新点
- Thinker-Talker双核架构:模拟了人类大脑与发声器官的工作机制,实现了端到端的统一模型架构。
- TMRoPE位置编码算法:通过时间轴对齐实现视频与音频输入的精准同步,提升了多模态融合效果。
- 情绪识别功能:通过音视频识别情绪,为复杂任务提供更智能、更自然的反馈与决策支持。
评估标准
- 多模态融合效果:评估模型在跨模态任务中的表现,如OmniBench等测评。
- 实时生成能力:测试模型的实时生成速度和流畅度。
- 情绪识别准确率:评估模型在音视频情绪识别任务中的表现。
应用领域
Qwen2.5-Omni适用于多种应用场景,如智能客服、教育科技、医疗健康等。在智能客服领域,全模态交互能力将大幅提升服务体验;在教育科技中,同时理解语音、图像和文本的能力可以创造更丰富的学习场景;医疗健康领域则可利用其多模态分析能力进行更全面的诊断辅助。
项目地址
- GitHub:https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
- DashScope:https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
- Qwen Chat体验:https://chat.qwenlm.ai
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
