OThink-MR1:OPPO联合港科大推出的多模态语言模型优化框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
OThink-MR1是由OPPO研究院与香港科技大学(广州)联合研发的多模态语言模型优化框架,旨在通过动态强化学习技术提升模型在复杂任务中的泛化推理能力。该框架基于动态KL散度策略(GRPO-D)和奖励模型,显著增强多模态模型在视觉计数、几何推理等任务中的表现,为通用推理能力发展开辟新路径。
功能特点
- 动态强化学习优化:通过动态调整KL散度权重,平衡模型在训练过程中的探索与利用,提升全局优化能力。
- 跨任务泛化能力:模型在单一任务训练后,可迁移至不同类型任务,减少对特定任务数据的依赖。
- 奖励模型引导:结合验证准确性奖励和格式奖励,确保输出准确且符合特定格式要求。
- 高性能推理:在视觉计数任务中错误率降低37%,几何推理准确率提升29%。
优缺点
- 优点:
- 高效泛化:跨任务泛化实验展现强大适应性,数据需求减少60%。
- 精准推理:在复杂任务中显著提升准确性和泛化能力。
- 动态平衡:实时调整探索/利用权重,避免陷入局部最优解。
- 缺点:
- 技术门槛:框架基于动态强化学习,对使用者技术能力要求较高。
- 资源需求:训练过程需较高算力支持,可能限制低配置设备的使用。
如何使用
目前,OThink-MR1主要作为研究框架发布,尚未提供直接的用户端应用。研究者可通过以下方式参与:
- 技术论文研究:访问arXiv平台获取详细技术文档(arXiv论文地址)。
- 代码开源:关注OPPO研究院或香港科技大学的开源项目更新。
- 学术合作:与研发团队联系,参与相关学术研究或项目合作。
框架技术原理
- 动态KL散度策略(GRPO-D):
- 受经典强化学习中的ϵ-greedy策略启发,遵循“早期探索,后期利用”原则。
- 训练初期权重较小,鼓励模型广泛探索;随着训练进行,权重逐渐增加,引导模型利用积累的经验。
- 奖励模型:
- 评估模型输出的准确性,例如在视觉计数任务中,匹配模型输出与真实计数。
- 确保输出符合特定格式要求,例如几何推理任务的格式正确性。
- 强化学习优化:
- 基于最大化奖励函数,优化模型的策略。
- 在每个训练步骤中,模型根据当前策略生成输出,奖励模型评估输出质量,模型根据奖励信号调整策略。

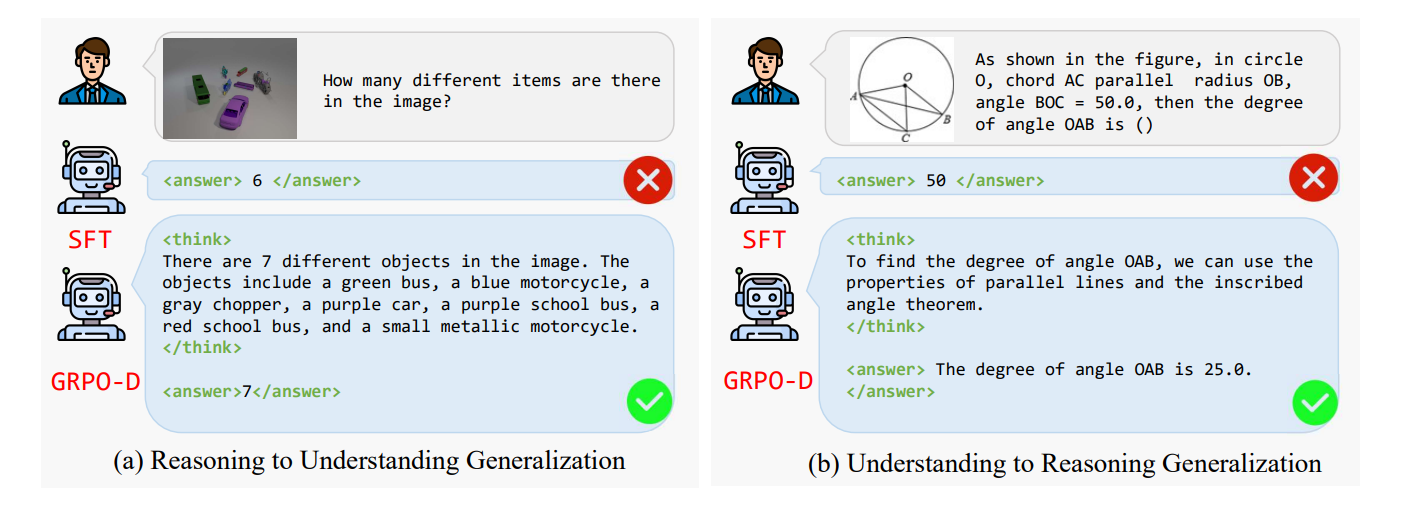
创新点
- 动态平衡探索与利用:通过GRPO-D策略,实现训练过程中探索与利用的动态平衡,避免模型陷入局部最优解。
- 双维度奖励机制:结合验证准确性奖励和格式奖励,为模型提供更全面的反馈,提升整体推理能力。
- 跨任务泛化能力:让模型在一种多模态任务上训练后,有效迁移到其他不同类型的多模态任务。
评估标准
- 任务准确性:在视觉计数、几何推理等任务中的准确率。
- 泛化能力:模型在跨任务实验中的表现,例如从推理任务到理解任务的迁移能力。
- 训练效率:模型在训练过程中的收敛速度和资源消耗。
- 输出质量:模型生成结果的格式正确性和内容准确性。
应用领域
- 智能视觉问答:准确理解图像内容并生成答案,如识别复杂场景中的物体数量。
- 图像描述生成:生成丰富且准确的图像描述,提供更详细的视觉信息。
- 几何问题求解:分析图像中的几何图形,计算角度、长度等几何属性。
- 虚拟现实与增强现实:为用户提供智能交互体验,如实时场景解读和导航建议。
项目地址
- 技术论文:arXiv论文地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
