SWEET-RL:Meta推出的多轮强化学习框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
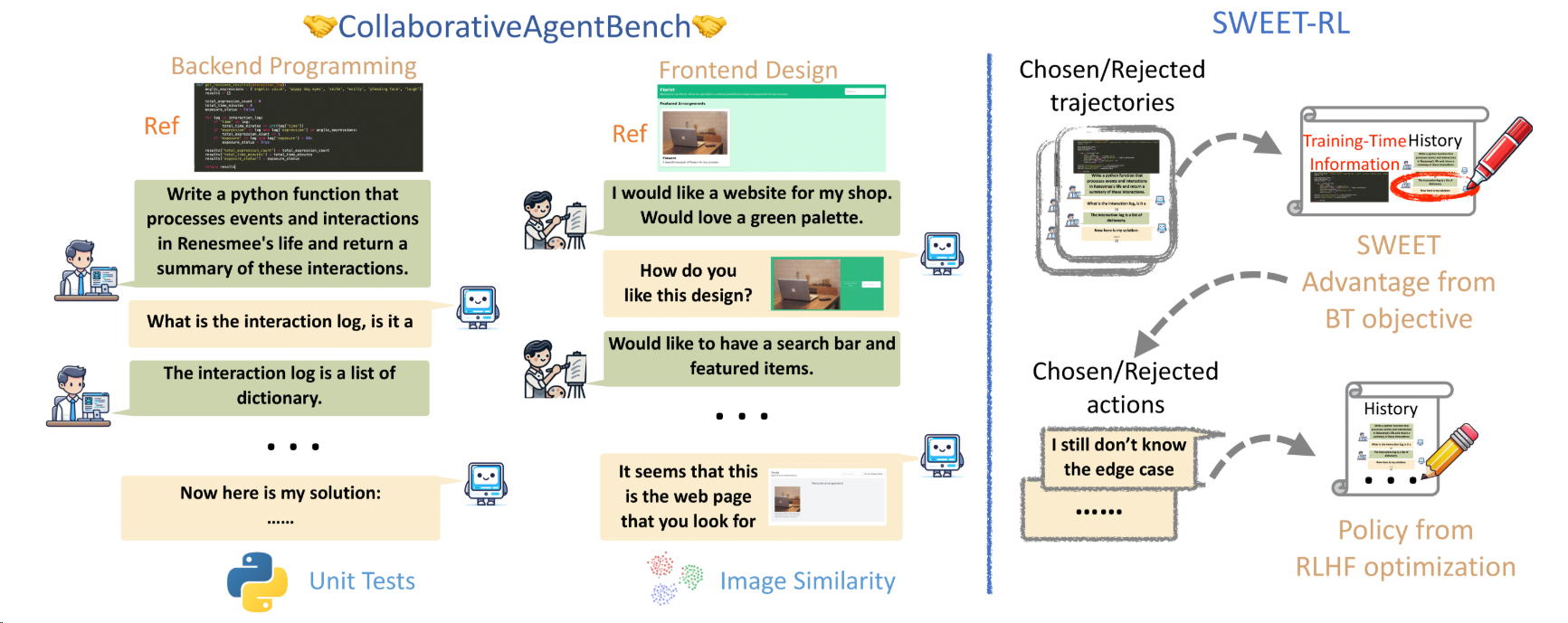
SWEET-RL(Step-WisE Evaluation from Training-time information)是Meta AI与加州大学伯克利分校联合推出的多轮强化学习框架,旨在解决大型语言模型(LLM)在多轮人机协作任务中的信用分配难题。该框架通过非对称的“演员-评论家”结构和Bradley-Terry目标函数,显著提升了模型在复杂任务中的表现,特别是在后端编程和前端设计领域。
功能特点
- 多轮交互优化:专门针对需要持续协作的复杂任务设计,如前后端开发协作。
- 精准信用分配:基于参考解决方案生成步骤级奖励,解决长期依赖问题。
- 跨任务泛化:在编程、设计等不同领域均展现出色适应性。
- 非对称信息架构:批评者模型掌握参考答案,演员模型专注交互历史,提升评估准确性。
优缺点
- 优点:
- 性能提升显著:在ColBench基准测试中,Llama-3.1-8B模型的成功率提升6%,部分场景超越GPT-4。
- 资源高效:通过训练时额外信息的利用,减少了对大量标注数据的需求。
- 架构灵活:非对称的“演员-评论家”结构使模型能够平衡探索与利用。
- 缺点:
- 技术门槛较高:框架基于复杂的强化学习技术,对使用者技术能力要求较高。
- 计算资源需求:训练过程需要较高的算力支持,可能限制低配置设备的使用。
如何使用
- 环境配置:通过
pip install -e .安装依赖。 - 数据准备:使用ColBench基准测试数据集,包含超过10,000个训练任务和1,000个测试案例。
- 模型训练:利用SWEET-RL框架进行多轮强化学习训练,优化模型策略。
- 性能评估:通过单元测试通过率和余弦相似度等指标评估模型表现。
框架技术原理
- 非对称演员-评论家架构:
- 批评者模型:访问参考解决方案等额外信息,生成更准确的步骤奖励。
- 演员模型:仅依赖交互历史,保持部署场景的一致性。
- Bradley-Terry目标函数:直接优化优势函数,避免价值函数估计偏差,与LLM预训练目标对齐。
- 参数化优势函数:将优势函数参数化为每个动作的平均对数概率,基于轨迹级别的Bradley-Terry目标进行训练。
创新点
- 动态信用分配:通过步骤级奖励优化,显著提升LLM在多轮协作任务中的表现。
- 非对称信息结构:批评者掌握参考答案,演员专注交互历史,提升评估准确性。
- 参数化优势函数:与LLM预训练目标对齐,提升知识迁移效率。
评估标准
- 任务成功率:在后端编程任务中,通过率提升至48.0%。
- 设计相似度:在前端设计任务中,余弦相似度达到76.9%。
- 跨任务泛化能力:模型在不同任务中的表现一致性。
- 计算效率:训练过程中的资源消耗和收敛速度。
应用领域
- 后端编程:如Python函数编写,通过多轮交互优化代码生成。
- 前端设计:如HTML代码生成,提升设计的一致性和美观性。
- 智能助手:在多轮对话中提供更精准的回答和建议。
- 复杂任务规划:如旅行规划、项目管理等,通过多轮协作优化解决方案。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
