FantasyTalking:阿里联合北邮推出静态肖像生成可控数字人的框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
FantasyTalking是由阿里巴巴AMAP团队与北京邮电大学联合研发的基于视频扩散变换器的新型数字人生成框架。该框架通过创新视听对齐机制实现静态肖像的动态化生成,支持从单张静态图像到动态视频的跨模态转换,解决了传统虚拟形象生成在动作自然度与身份保持方面的瓶颈,推动数字人技术向“数字永生”迈进。

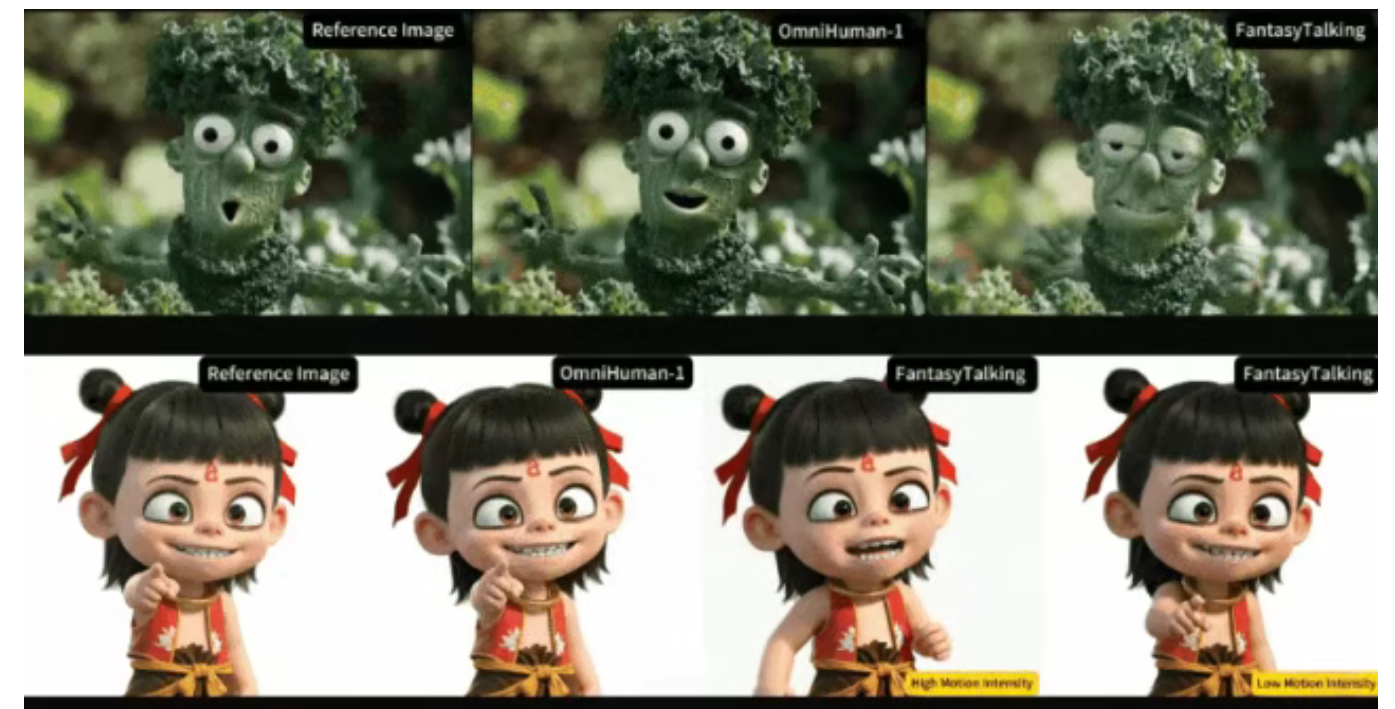
功能特点
- 精准口型同步
唇部运动与音频信号时间对齐误差小于40毫秒,口型同步误差仅0.03秒,实现高度逼真的语音驱动效果。 - 多维表情控制
支持22组面部肌肉群的独立强度调节,从微蹙眉头到开怀大笑均可量化控制,表情强度调节范围覆盖22种面部肌肉运动。 - 多姿态支持
证件照可秒变360°动态形象,支持特写、半身、全身等视角的动态输出,侧面说话时下颌线依旧清晰。 - 全身动作生成
实现自然头部转动、肩部摆动等非语言动作,支持全身动作与面部表情的协同生成。
优缺点
优点
- 高保真度:生成视频质量高,动作自然流畅,身份特征保持稳定。
- 可控性强:支持表情强度、运动幅度的显式调节,满足多样化需求。
- 多模态支持:兼容写实、卡通等多种风格,适应不同应用场景。
缺点
- 计算成本高:依赖扩散模型的迭代采样过程,实时应用效率较低。
- 数据依赖性强:性能高度依赖于高质量的训练数据,数据获取和标注成本较高。
如何使用
- 输入准备
提供单张静态肖像、驱动音频及提示文本(可选)。 - 模型调用
通过项目官网或开源代码库调用FantasyTalking模型,输入准备好的数据。 - 参数调节
根据需求调节表情强度、运动幅度等参数,实现个性化控制。 - 视频生成
模型输出与音频同步的动态视频,支持多种分辨率和格式。
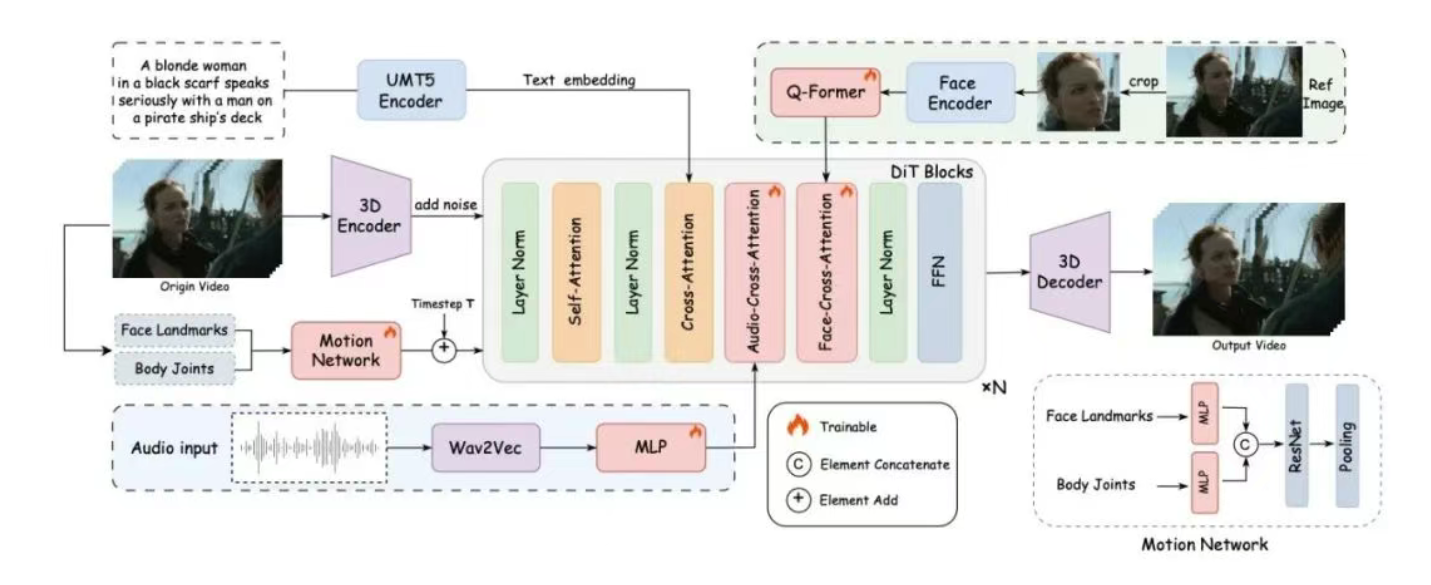
框架技术原理
- 双阶段视听对齐
第一阶段通过片段级训练建立全局运动模式,第二阶段通过帧级细化专注唇部微动作校准,确保口型与音频精确同步。 - 面部专注注意力机制
采用交叉注意力机制解耦身份特征与动态生成,仅需3%的额外参数量即可实现身份保持。 - 运动强度调制模块
引入可调节系数控制表情幅度与身体摆动强度,支持0-1连续值调节生成不同情绪状态。 - 视频扩散变换器
基于Wan2.1模型的时空建模能力,单张RTX3090显卡可生成1280×720分辨率视频。
创新点
- 双阶段训练策略
片段级与帧级结合的训练方式,提升全局运动与局部细节的协同效果。 - 面部专注注意力
通过解耦身份特征与动态生成,实现高效身份保持与动作自由度的平衡。 - 运动强度调制
首次实现表情与身体运动强度的显式控制,拓展数字人可控性边界。 - 多视角支持
支持特写、半身、全身等多视角动态输出,适应复杂场景需求。
评估标准
- 视频质量
生成视频的清晰度、流畅度及动作自然度。 - 时间一致性
口型与音频的同步精度及动作的时序连贯性。 - 运动多样性
支持的表情与动作种类及强度调节范围。 - 身份保持
动态视频中人物身份特征的一致性与稳定性。
应用领域
- 影视制作
用于虚拟演员生成、历史人物复刻等场景。 - 数字娱乐
打造虚拟偶像、游戏角色等互动内容。 - 教育培训
生成虚拟教师、培训讲师等教学素材。 - 广告营销
创建虚拟代言人、产品演示等宣传内容。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
