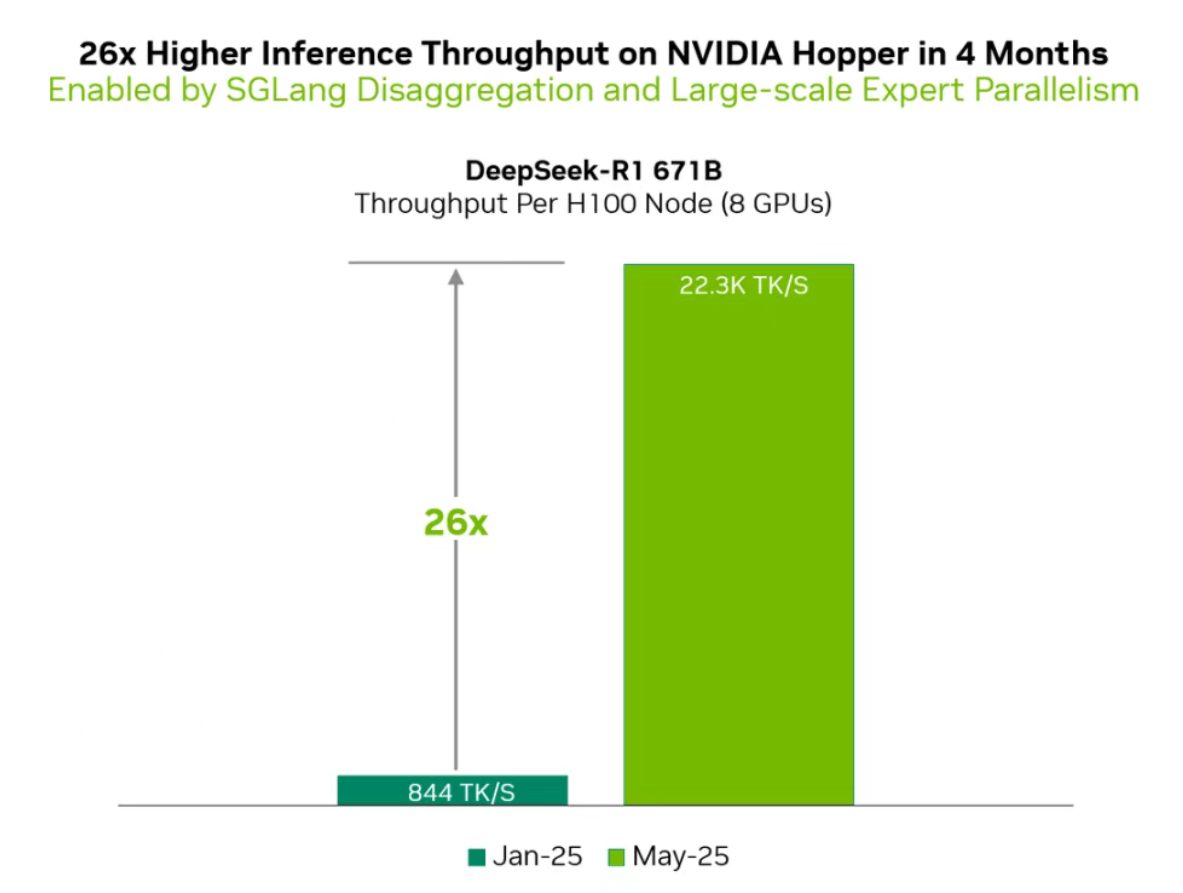
5月8日·全球首个最接近原版 DeepSeek 的开源复现,性能提升 26 倍!
5月8日·周四 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
全球首个最接近原版 DeepSeek 的开源复现,性能提升 26 倍!
谷来自 SGLang 和英伟达等机构的联合团队发布了一篇技术报告,展示了他们在短短 4 个月内将 DeepSeek-R1 在 H100 上的性能提升了 26 倍的成果。这一开源复现版本的吞吐量已非常接近 DeepSeek 官方数据。团队通过全面升级 SGLang,支持 PD 分离、大规模 EP、DeepEP、DeepGEMM 及 EPLB 等功能,成功在 12 个节点共 96 块 GPU 的集群上复现了 DeepSeek 的推理系统。优化后的方案在处理 2000 个 token 的输入序列时,实现了每个节点每秒 52.3k 输入 token 和 22.3k 输出 token 的吞吐量。此外,该方案在本地部署的成本可降至 0.20 美元/1M 输出 token,约为 DeepSeek Chat API 官方定价的五分之一。团队还详细介绍了并行设计、优化方法以及最终成果,包括注意力层、稠密 FFN、稀疏 FFN 和 LM 头的优化策略。来源:微信公众号【新智元】
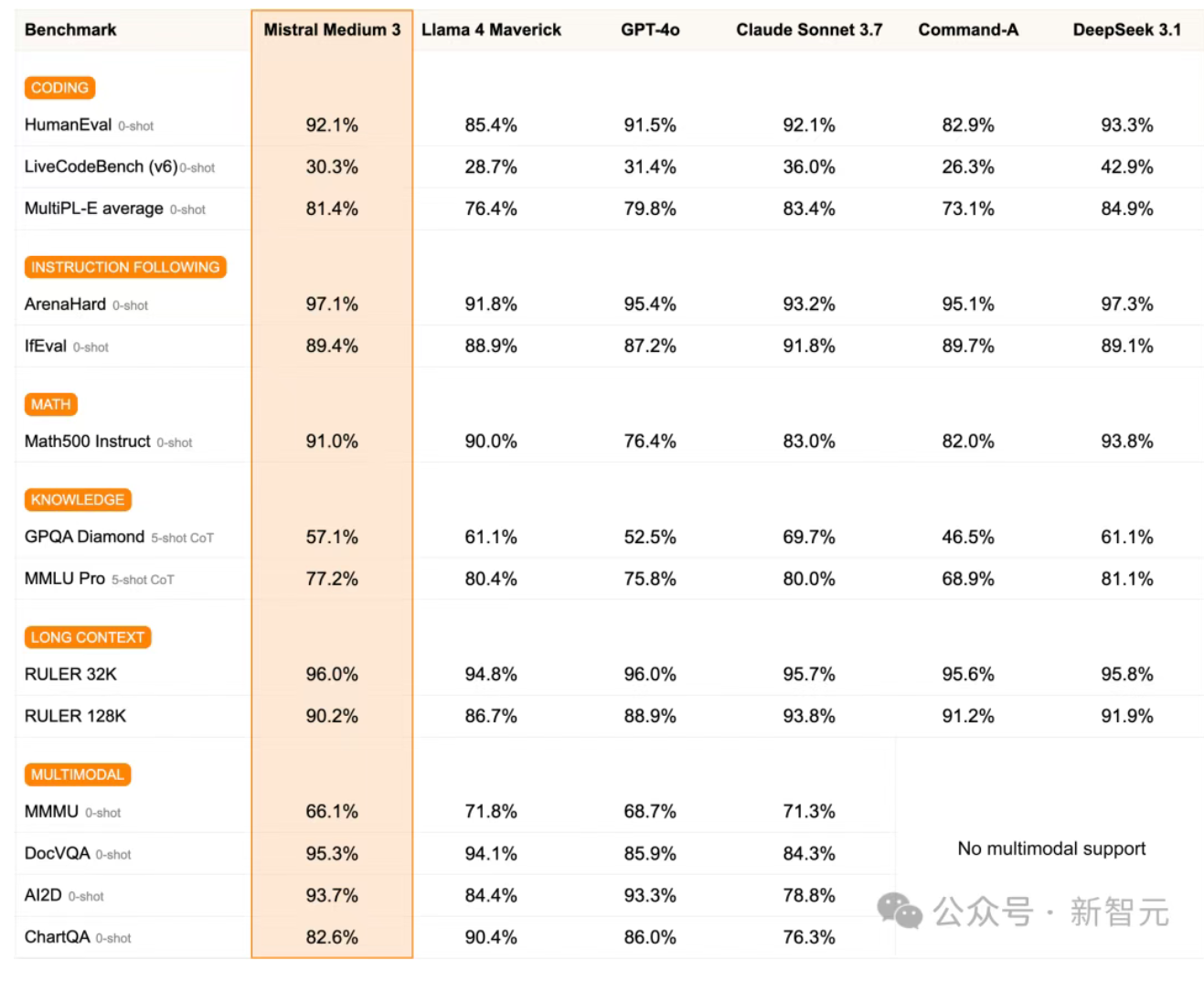
Mistral Medium 3 发布,性价比高但实测表现不佳
法国初创公司 Mistral AI 发布了其最新多模态模型 Mistral Medium 3。该公司声称该模型的性能接近甚至达到了 Claude Sonnet 3.7 的水平,但成本却比 DeepSeek V3 更低。Mistral Medium 3 的核心亮点包括顶尖性能、成本降低至原来的八分之一,以及更易于部署。然而,根据网友们的实测,该模型在实际应用中表现不佳,尤其是在编码和写作任务中,未能达到官方宣称的水平。尽管如此,Mistral Medium 3 仍提供了企业级功能,包括混合云部署、定制化后训练和集成到企业工具中。Mistral 还计划在未来几周内推出性能更强的 Mistral Large。来源:微信公众号【新智元】
OpenAI 任命新 CEO Fidji Simo,聚焦产品与应用
OpenAI 宣布任命 Fidji Simo 为「应用 CEO」,直接向公司创始人山姆・奥特曼汇报。Fidji Simo 曾是 Instacart 的 CEO,并在 Facebook(Meta)担任高管十年,以卓越的领导力和产品创新闻名。奥特曼将继续担任 OpenAI CEO,专注于研究、算力与安全。此次组织架构调整旨在加强 OpenAI 在产品和应用领域的执行力,推动研究成果更快地惠及全球用户。Fidji Simo 将在未来几个月内从 Instacart 离职,加入 OpenAI,负责领导应用团队,推动 ChatGPT 等产品的进一步发展。来源:微信公众号【机器之心】

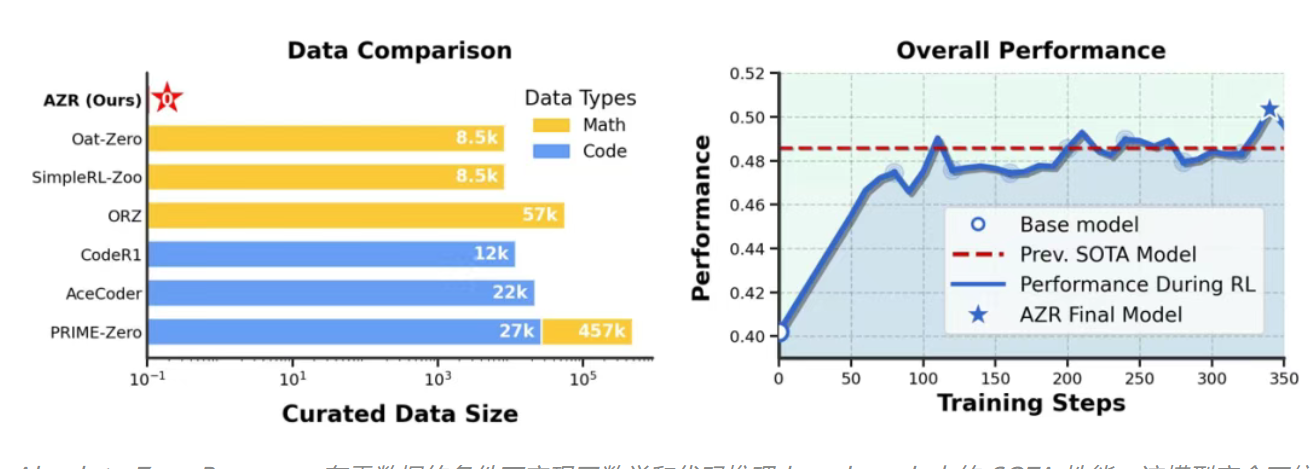
清华大学提出 Absolute Zero,开启零数据推理训练新时代
清华大学 LeapLab 团队联合北京通用人工智能研究院 NLCo 实验室和宾夕法尼亚州立大学的研究者们提出了一种全新的推理训练范式——Absolute Zero。该范式通过类 AlphaZero 的自博弈方法,使大模型能够在没有人类或 AI 生成数据的情况下,通过自我提出任务并自主解决,实现「自我进化式学习」。研究团队训练了 Absolute Zero Reasoner(AZR),以代码执行器作为真实环境,自动生成并解决三类代码推理任务,涵盖归纳、演绎与溯因推理。实验表明,AZR 在代码生成与数学推理基准任务中表现出色,超越了现有方法,达到 SOTA 水平。这一成果标志着推理模型训练从依赖人类监督向依赖环境监督的范式转变,为构建具备自主进化能力的智能体开辟了新路径。来源:微信公众号【机器之心】
华为 NPU 跑出准万亿参数大模型,打破英伟达垄断
华为盘古团队(包括诺亚方舟实验室和华为云等)基于昇腾国产算力平台,成功完成了 7180 亿参数的 MoE 模型的长期稳定训练。这一成果标志着在训练超大参数模型方面,国产 NPU 硬件平台取得了重大突破。华为通过多项系统优化技术,大幅提高了训练效率,解决了负载均衡、通信开销和硬件适配等关键问题。实验表明,盘古 Ultra MoE 模型在多个基准测试中表现出色,与 DeepSeek-R1 等顶尖模型相当。这一成就不仅展示了华为在 AI 硬件和软件协同优化方面的强大能力,也彰显了中国科技在大模型训练领域的自主创新实力。:微信公众号【量子位】
相关文章

Your blog is a testament to your dedication to your craft. Your commitment to excellence is evident in every aspect of your writing. Thank you for being such a positive influence in the online community.