Insert Anything:浙大联合哈佛大学与南洋理工推出的图像插入框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Insert Anything 是由浙江大学、哈佛大学和南洋理工大学联合研发的开源图像插入框架,旨在解决传统图像编辑中“将任意元素无缝插入目标场景”的难题。该框架通过单一模型支持多种插入任务(如人物、物体、服装等),并首次将扩散变换器(DiT)引入图像插入领域,实现了高保真度和灵活性的视觉合成。其核心目标是通过上下文感知的编辑技术,保留参考元素的身份特征,同时与目标场景实现视觉和谐。
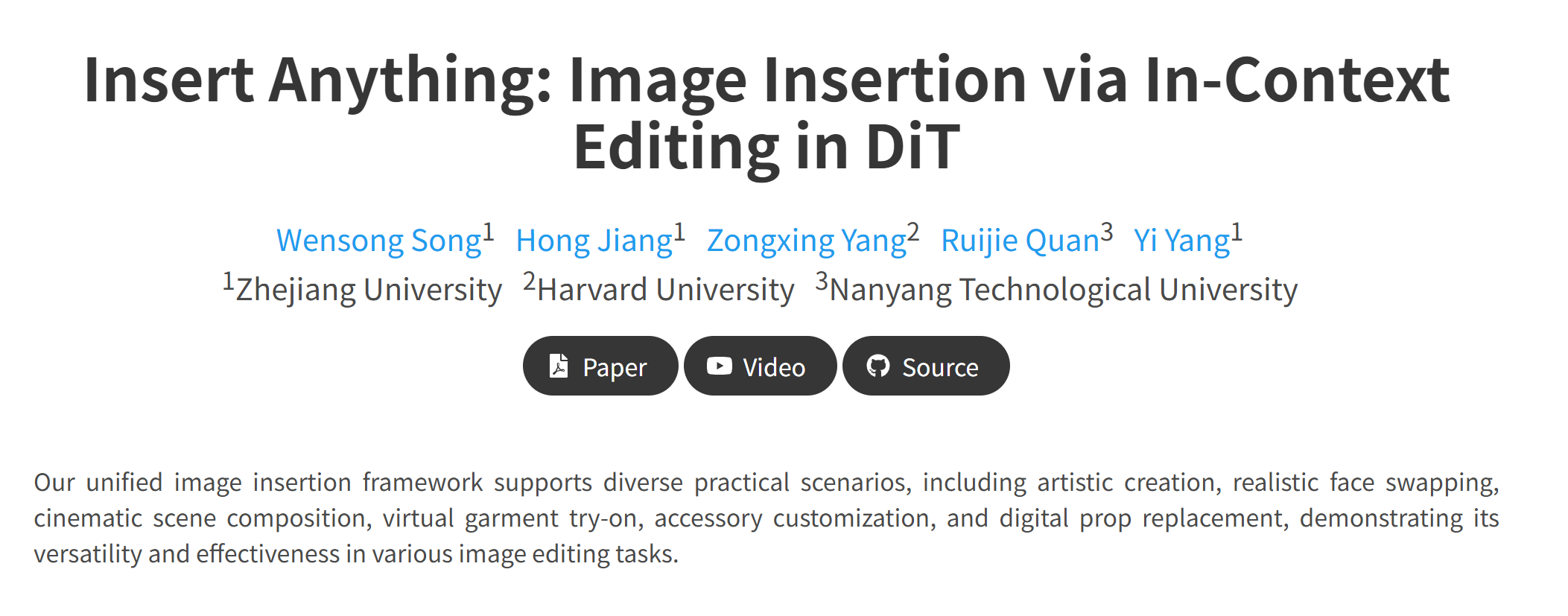

功能特点
- 多任务统一框架:支持人物、物体、服装等多种插入任务,无需针对不同任务单独训练模型。
- 双模式控制:支持掩码提示(Mask-Prompt)和文本提示(Text-Prompt)两种编辑方式,用户可根据需求灵活选择。
- 上下文感知编辑:通过双联画(Diptych)和三联画(Triptych)策略,将参考元素与目标场景的上下文信息融合,确保插入内容的自然性和一致性。
- 高保真度生成:利用DiT的多模态注意力机制,在保留参考元素细节特征的同时,实现与目标场景的颜色、纹理和谐融合。
- 大规模数据集支持:基于AnyInsertion数据集(包含120K提示-图像对)进行训练,覆盖多样化的插入任务和控制模式。
优缺点
- 优点:
- 通用性强:单一模型支持多种插入任务,显著降低了训练和部署成本。
- 灵活性高:支持掩码和文本双模式控制,满足不同用户的编辑需求。
- 生成质量高:在AnyInsertion、DreamBooth和VTON-HD等基准测试中表现优异,生成的图像在视觉真实感和细节保留方面表现突出。
- 开源社区支持:代码和数据集完全开源,便于学术界和工业界的研究与应用。
- 缺点:
- 计算资源需求高:基于DiT的模型训练和推理需要较强的计算资源支持,可能限制在低性能设备上的部署。
- 复杂场景适应性有限:在极端复杂的场景(如高度遮挡、光照变化剧烈)中,插入效果可能仍需优化。
如何使用
- 安装依赖:
- 克隆项目仓库:
git clone https://github.com/song-wensong/insert-anything.git - 安装PyTorch和相关依赖库(具体版本参考项目文档)。
- 克隆项目仓库:
- 准备数据:
- 下载AnyInsertion数据集,或准备自定义的参考图像和目标场景对。
- 模型训练:
- 根据需求选择掩码提示或文本提示模式,配置训练参数(如学习率、批次大小等)。
- 运行训练脚本:
python train.py --config configs/mask_prompt.yaml(掩码模式示例)。
- 图像插入:
- 使用训练好的模型进行推理,输入参考图像和目标场景,指定掩码或文本提示。
框架技术原理
- DiT(Diffusion Transformer)架构:
- 利用Transformer的多模态注意力机制,联合建模文本、掩码和图像之间的关系,实现灵活的编辑控制。
- 上下文编辑机制:
- 双联画(Diptych):将参考图像和掩码目标图像拼接,通过上下文关系指导插入。
- 三联画(Triptych):将参考图像、源图像和文本提示拼接,通过语义引导实现自适应融合。
- 多模态注意力融合:
- 在DiT的图像分支中,处理视觉输入(参考图像、源图像、掩码);在文本分支中,编码文本描述以提取语义信息。
- 通过通道维度拼接和噪声注入,生成高质量的目标图像。
创新点
- 首次将DiT引入图像插入领域:
- 充分发挥DiT在不同控制模式下的独特能力,实现了掩码和文本双引导的灵活编辑。
- 上下文感知的编辑技术:
- 通过双联画和三联画策略,将参考元素与目标场景的上下文信息融合,解决了传统方法中插入内容与场景不协调的问题。
- 大规模多样化数据集:
- AnyInsertion数据集包含120K提示-图像对,覆盖人物、物体、服装等多种任务,支持掩码和文本双模式训练。
评估标准
- 视觉真实感:
- 通过FID(Fréchet Inception Distance)和LPIPS(Learned Perceptual Image Patch Similarity)等指标评估生成图像与真实图像的相似度。
- 身份特征保留:
- 通过特征相似度(如余弦相似度)评估参考元素在插入后的身份特征保留程度。
- 控制模式灵活性:
- 评估掩码提示和文本提示在不同任务中的表现,包括插入位置的准确性和生成图像的多样性。
- 计算效率:
- 记录模型训练和推理的时间消耗,评估其在不同硬件环境下的性能。
应用领域
- 创意内容生成:
- 广告设计、电影特效、游戏开发等领域,快速生成高质量的合成图像。
- 虚拟试穿:
- 在线购物平台中,用户可通过上传参考服装图像,实时查看试穿效果。
- 场景构图:
- 室内设计、建筑可视化等领域,将任意物体无缝插入目标场景,辅助设计决策。
- 艺术创作:
- 艺术家可通过文本或掩码提示,将任意元素融入画作,激发创作灵感。
项目地址
- 项目官网:https://song-wensong.github.io/insert-anything/
- GitHub仓库:https://github.com/song-wensong/insert-anything
- arXiv技术论文:https://arxiv.org/pdf/2504.15009
Insert Anything 的推出为图像编辑领域带来了革命性的突破,其强大的功能和灵活的控制方式,使其在学术研究和工业应用中具有广阔的前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
