5月12日·Transformer作者创企推出“连续思维机器”,AI推理更像人类
5月12日·周一 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Transformer作者创企推出“连续思维机器”,AI推理更像人类
Transformer作者之一Llion Jones创立的Sakana AI发布了“连续思维机器”(CTM),这是一种新型人工神经网络,通过模拟生物大脑中神经元活动的同步来实现复杂推理。与传统神经网络不同,CTM在神经元层面引入时间信息,使模型能够分步骤思考问题,推理过程更具可解释性。CTM在迷宫求解和图像识别等任务中表现出色,其行为模式类似于人类,例如在解迷宫时会逐步规划路径,在识别图像时会关注关键特征。CTM的出现被认为是弥合人工神经网络与生物神经网络差距的重要一步,为AI的发展提供了新的方向。来源:微信公众号【机器之心】
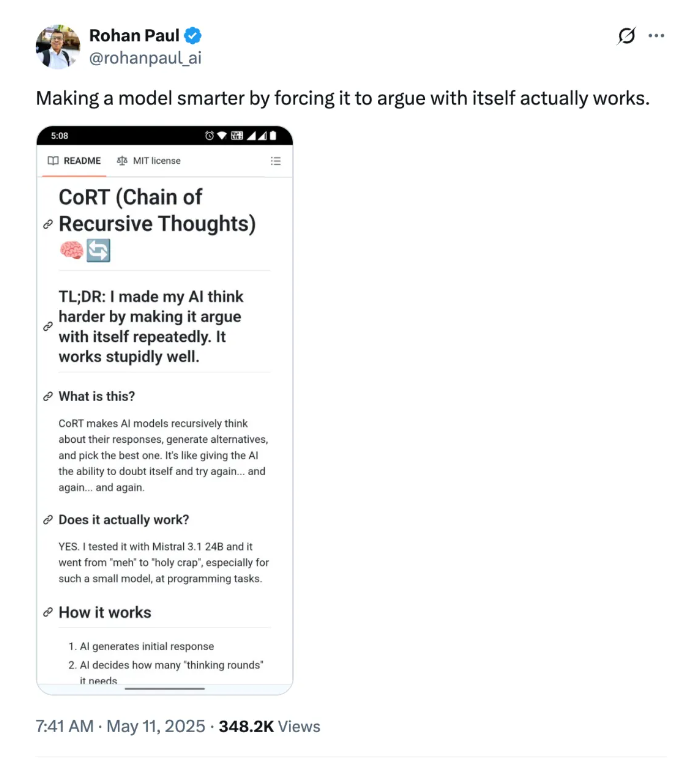
递归思考版CoT(CoRT)引发热议,网友质疑其创新性
一种名为CoRT(Chain-of-Recursive-Thoughts)的递归思考模型引发了广泛关注。CoRT在传统的链式思考(CoT)基础上引入了递归思考机制,让AI模型能够生成多种替代性方案,并通过自我批判和迭代优化选择最佳答案。这一机制类似于人类的反思性思维,能够显著提升语言模型的推理能力。然而,许多网友对CoRT的创新性提出了质疑,认为其与现有的多智能体辩论和自我反驳模式相似,更像是“新瓶装旧酒”。尽管如此,CoRT在编程任务中的表现提升显著,例如将井字棋游戏从基础的命令行界面提升到面向对象编程,显示出其在实际应用中的潜力。来源:微信公众号【机器之心】
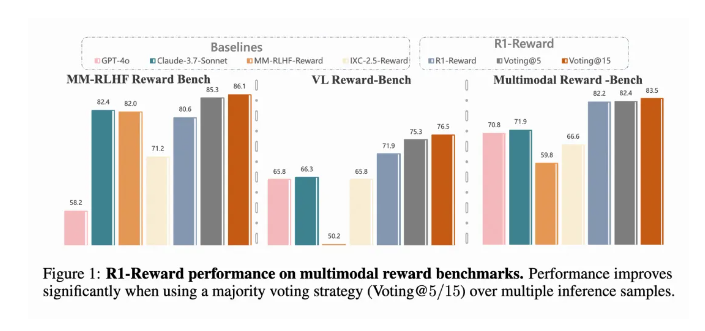
R1-Reward解锁奖励模型长时推理能力,强化学习训练更稳定
快手、中科院、清华、南大等机构的研究团队提出了R1-Reward,一种通过强化学习(RL)训练的多模态奖励模型,显著提升了模型的长时推理能力。该研究针对现有RL算法在训练多模态奖励模型时的不稳定性问题,提出了StableReinforce算法,通过改进损失函数、优势值处理方法和引入一致性奖励,有效稳定了训练过程。R1-Reward在多个多模态奖励模型基准测试中超越了现有最佳模型,准确率提升了5%到15%。此外,该模型在推理时通过多次采样和投票策略,性能进一步提升,显示出强大的工业化潜力,已在快手的短视频、电商和直播等业务场景中成功应用。来源:微信公众号【机器之心】
字节跳动与北大联合发布DreamO,低成本快速实现复杂图像定制
字节跳动与北京大学联合发布了DreamO,一个支持多条件组合的统一图像定制化生成框架。该框架通过单一模型即可实现主体、身份、风格及服装参考的多样化定制,并支持不同控制条件的自由组合,适应实际应用中的复杂需求。DreamO基于Flux-1.0-dev构建,引入了条件嵌入和索引嵌入,并通过低秩自适应模块优化模型,支持多条件任务。其渐进式训练策略分为三个阶段:主体驱动数据优化、全数据训练和图像质量优化,显著提高了生成质量和一致性保持能力。DreamO开源、成本低、速度快,8~10秒即可完成一张图片的定制化生成,展现了强大的工业化潜力。来源:微信公众号【量子位】

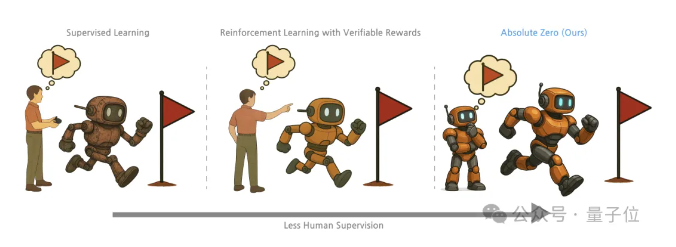
清华&通院推出“绝对零”训练法,大模型自我博弈解锁推理能力
清华大学、北京通用人工智能研究院和宾夕法尼亚州立大学的研究人员提出了一种名为“绝对零”(Absolute Zero)的训练方法,通过自我博弈让大模型在无需外部数据的情况下学会推理。该方法通过让模型扮演出题者(Proposer)和解题者(Solver)两个角色,生成并解决推理任务,从而提升模型的推理能力。实验表明,“绝对零”训练出的模型在编程任务和数学推理任务上均取得了显著进步,例如在HumanEval+数据集上通过率从80.5%提升到83.5%,在数学任务上平均准确率提升了15.2个百分点。此外,该方法还显示出与模型规模正相关的性能提升趋势,表明其能够有效利用大模型的潜力。来源:微信公众号【量子位】
相关文章
