FastVLM:苹果推出的高效视觉语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
FastVLM 是苹果提出的一种针对视觉语言模型(VLM)的高效视觉编码器,专为高分辨率图像处理优化。它通过创新的 FastViTHD 混合视觉编码器,在保持高准确性的同时,显著减少编码时间和视觉 token 数量,从而降低整体延迟。FastVLM 的设计旨在实现延迟、模型大小和准确性之间的优化平衡,特别适合在资源有限的移动设备(如 iPhone)上部署。
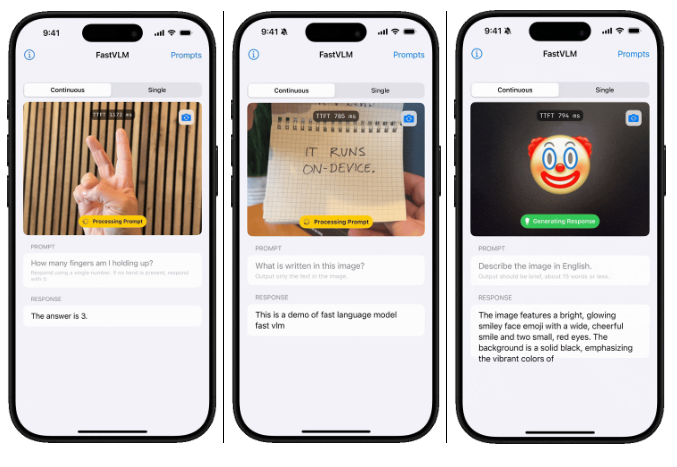
功能特点
- 高效视觉编码:
- 采用 FastViTHD 编码器,生成更少的视觉 token,显著减少编码时间。
- 在高分辨率图像(如 1152×1152)下,编码速度比同类模型快 85 倍。
- 低延迟响应:
- 在 LLaVA-1.5 设置中,首次 token 生成时间(TTFT)提升了 3.2 倍。
- 模型尺寸优化:
- 视觉编码器尺寸比同类模型小 3.4 倍,便于在移动设备上部署。
- 高准确性:
- 在多项基准测试(如 SeedBench、MMMU)中,性能与更大模型相当。
- 简化设计:
- 仅通过缩放输入图像尺寸实现 token 数量和分辨率的平衡,无需额外的 token 剪枝。
优缺点
优点:
- 速度快:编码速度提升显著,适合实时应用。
- 模型小:视觉编码器尺寸小,适合移动设备部署。
- 高准确性:在保持高效的同时,性能不逊色于更大模型。
- 设计简洁:无需复杂的 token 剪枝,模型设计更高效。
缺点:
- 依赖高分辨率输入:在低分辨率下可能无法充分发挥优势。
- 训练数据需求:需要大量高质量的图像-文本对数据进行预训练。
如何使用
-
环境准备:
- 安装 PyTorch 和相关依赖库。
- 下载 FastVLM 的预训练模型权重。
-
参数调节:
- 通过调整输入图像尺寸控制生成速度和质量。
- 通过
max_length参数控制生成文本的长度。
框架技术原理
- FastViTHD 编码器:
- 采用混合视觉编码器架构,结合卷积层和自注意力机制,减少 token 数量。
- 使用多尺度池化、额外的自注意力层和下采样技术,提高编码效率。
- 视觉语言投影器:
- 将视觉编码器的输出转换为大型语言模型(LLM)可理解的格式。
- 大型语言模型(LLM):
- 结合视觉特征生成文本响应,实现多模态理解。
创新点
- 高效高分辨率处理:
- 专为高分辨率图像设计,显著减少编码时间和 token 数量。
- 无需 token 剪枝:
- 通过缩放输入图像尺寸实现 token 数量和分辨率的平衡,简化模型设计。
- 移动端优化:
- 模型尺寸小,适合在 iPhone 等移动设备上部署。
评估标准
- 客观指标:
- 首次 token 生成时间(TTFT):衡量模型响应速度。
- 视觉 token 数量:评估模型编码效率。
- 模型尺寸:评估模型部署的可行性。
- 主观评价:
- 准确性:在基准测试(如 SeedBench、MMMU)上的表现。
- 实用性:在移动设备上的实际运行效果。
应用领域
- 移动设备 AI:
- 在 iPhone 上实现实时图像理解和自然语言交互。
- 实时多模态应用:
- 如实时图像标注、视觉问答等。
- 边缘计算:
- 在资源有限的设备上部署高效的多模态模型。
项目地址
-
- GitHub仓库:https://github.com/apple/ml-fastvlm
- arXiv技术论文:https://www.arxiv.org/pdf/2412.13303
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
