ViLAMP : 蚂蚁联合人民大学推出的视觉语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用。
主要介绍
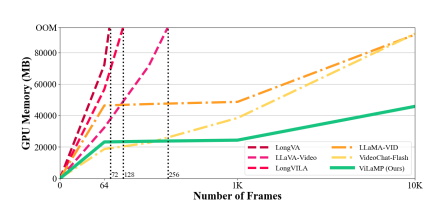
ViLAMP(Video-Language Model with Mixed Precision)是由蚂蚁集团与中国人民大学联合推出的视觉语言模型,专为解决长视频理解中的计算瓶颈问题而设计。该模型通过创新的“混合精度”策略,能够在单张A100 GPU上连续处理长达1万帧(约3小时)的视频内容,同时保持高效的理解准确率。ViLAMP在Video-MME等五个主流视频理解基准上全面超越现有方案,尤其在长视频处理中展现出显著优势,为在线教育、视频监控、直播分析等场景提供了新的技术支撑。

功能特点
- 超长视频处理能力:
- 可在单张A100 GPU上处理1万帧(约3小时)的视频内容,突破传统模型的上下文处理极限。
- 混合精度策略:
- 对关键内容保持高精度分析,对次要内容进行强力压缩,显著降低计算开销。
- 差分关键帧选择(DKS):
- 采用贪心策略选择与用户Query高度相关且多样化的关键帧,降低帧间冗余。
- 差分特征合并(DFM):
- 通过差分加权池化将非关键帧压缩为单个信息量最大化的token,保留关键信息。
- 高效计算效率:
- 内存消耗相比基线模型降低约50%,在8,192帧情况下计算量减少80%以上。
优缺点
优点:
- 长视频处理能力强:单卡可处理3小时视频,适合超长视频分析场景。
- 计算效率高:混合精度策略显著降低内存和计算开销。
- 性能优越:在多个基准测试中超越现有方案,尤其在长视频理解任务中表现突出。
缺点:
- 模型参数量较小:相比部分70B量级模型,ViLAMP参数量为7B,可能在复杂场景下表现受限。
- 对硬件要求较高:尽管优化了计算效率,但仍需A100 GPU等高端硬件支持。
如何使用
- 获取模型:
- 访问ViLAMP的GitHub仓库(https://github.com/steven-ccq/ViLAMP),下载模型代码和预训练权重。
- 环境配置:
- 根据仓库中的说明,配置Python环境并安装依赖库(如PyTorch、Transformers等)。
- 数据准备:
- 准备待处理的视频数据,确保格式符合模型要求(如帧率、分辨率等)。
- 推理与评估:
- 使用提供的脚本进行视频推理,或参考论文中的评估方法对模型性能进行测试。
框架技术原理
- 差分蒸馏原则:
- 识别并保留重要的视频信息(高查询相关性、低信息冗余性),同时压缩冗余信息。
- 层次化压缩框架:
- 在帧级别,对关键帧保留完整视觉token表示,对非关键帧采用强力压缩策略。
- 在patch级别,通过差分机制增大重要patch的权重。
- 双层混合精度架构:
- 结合DKS和DFM机制,确保模型在降低计算开销的同时准确捕获关键信息。
创新点
- 混合精度策略:
- 首次在视觉语言模型中引入混合精度策略,实现长视频的高效处理。
- 差分关键帧选择与特征合并:
- 通过DKS和DFM机制,自适应地分配计算资源,提升长视频处理效率。
- 超长视频理解基准测试:
- 提出面向视频理解场景的“大海捞针”任务(VideoNIAH),验证模型在超长视频中的建模能力。
评估标准
- 准确性:
- 在Video-MME等基准测试中,评估模型对视频内容的理解准确率。
- 计算效率:
- 测量模型在处理不同长度视频时的内存消耗和计算量。
- 长视频建模能力:
- 在VideoNIAH任务中,评估模型从超长视频中定位并理解目标片段的能力。
应用领域
- 在线教育:
- 自动分析教学视频内容,生成课程摘要或知识点标签。
- 视频监控:
- 实时监控长视频流,检测异常事件并生成报警。
- 直播分析:
- 分析直播视频内容,提取关键信息或生成互动话题。
- 影视制作:
- 辅助视频剪辑,自动识别关键帧或片段。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!

Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
This was beautiful Admin. Thank you for your reflections.