MTVCrafter:中科院联合中国电信等机构推出的人像动画生成框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
MTVCrafter(Motion Tokenization Video Crafter)是由中科院、中国电信等机构联合研发的人像动画生成框架,首次将原始3D运动序列(即4D运动)直接建模用于动画生成。该框架通过量化3D运动序列为4D运动令牌(4DMoT),结合运动感知的视频扩散模型(MV-DiT),实现复杂3D场景下的自然人像动画。其核心突破在于避免传统2D姿态图像的局限性,通过4D运动令牌提供更鲁棒的时空线索,支持跨风格、跨身份的动画生成。实验表明,MTVCrafter在FID-VID指标上达到6.98,超越第二名65%,且在开放世界场景(如动漫、像素画、水墨画等)中展现出卓越的泛化能力。
功能特点
- 4D运动令牌化:将3D运动序列编码为紧凑的4D令牌,保留时空细节,避免像素级对齐问题。
- 运动感知扩散模型:MV-DiT通过4D位置编码和运动注意力机制,将运动令牌作为上下文驱动动画生成。
- 跨风格与跨身份动画:支持单/多人、全身/半身动画,兼容动漫、写实、水墨等多种风格。
- 高保真与一致性:在复杂动作(如体操)中保持物理合理性,动画帧间平滑过渡。
优缺点
优点:
- 3D运动建模:直接利用原始3D运动数据,避免2D姿态图像的时空信息丢失。
- 泛化性强:对未见风格(如油画、电影角色)和动作(如瑜伽、跑步)的适应能力突出。
- 高可控性:支持跨身份动画,例如用真人动作驱动动漫角色。
缺点:
- 依赖3D运动数据:需高质量3D运动序列作为输入,普通用户获取难度较高。
- 计算资源需求:4D运动令牌化与扩散模型训练需大量算力支持。
- 复杂场景限制:在极端遮挡或高动态动作中可能存在细节失真。
如何使用
- 数据准备:输入目标人像图像及驱动视频(或3D运动序列)。
- 模型推理:通过预训练的4DMoT和MV-DiT模型生成动画。
- 后处理:调整动画参数(如速度、风格)以优化效果。
框架技术原理
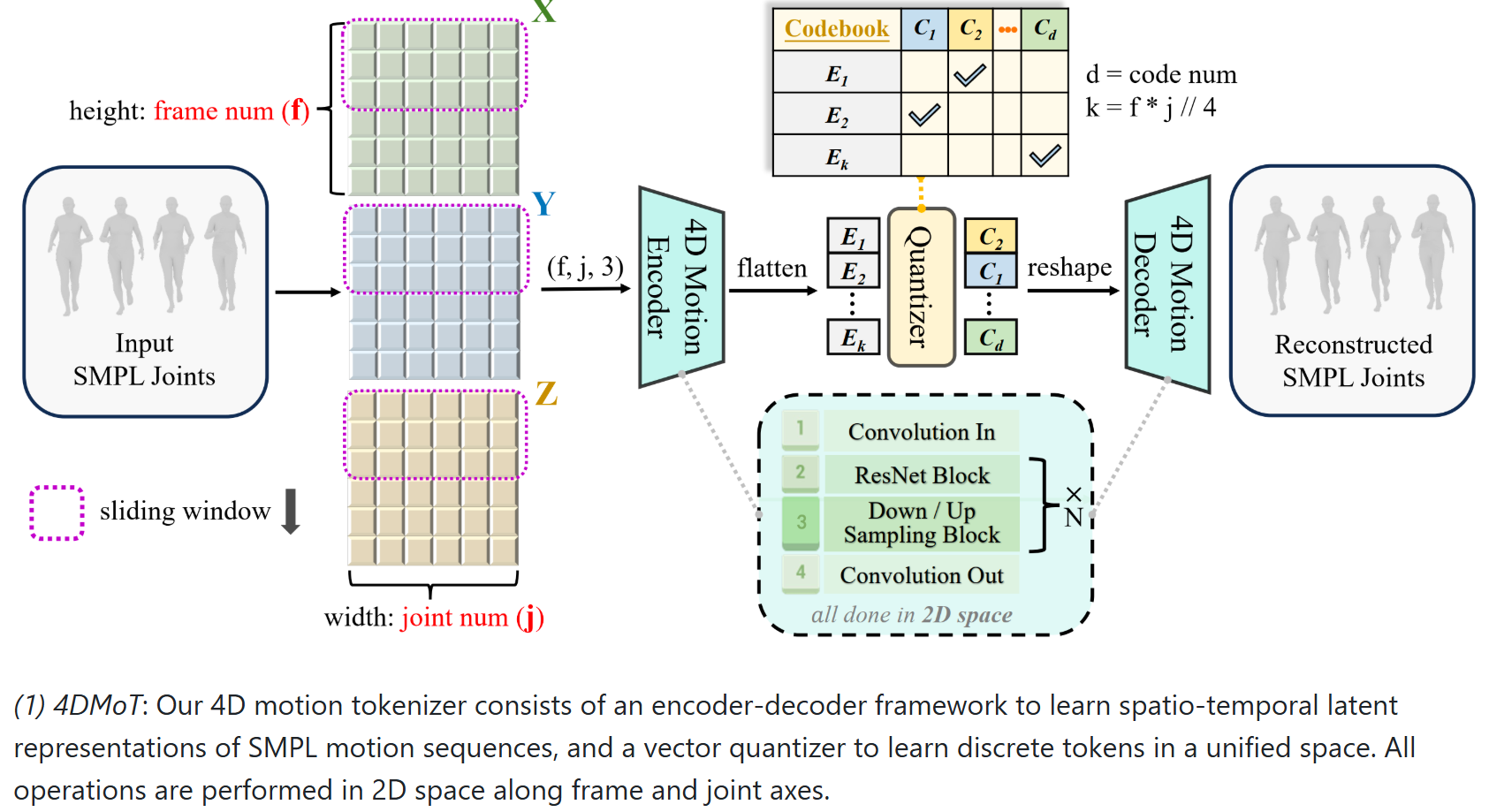
- 4DMoT(4D运动令牌化):将3D运动序列编码为离散令牌,保留时空结构信息。
- MV-DiT(运动感知视频扩散模型):基于Transformer架构,通过4D位置编码和运动注意力机制,将运动令牌作为上下文引导动画生成。
- 时空一致性约束:采用多阶段去噪损失(如姿态主导、细节主导)优化动画质量。
创新点
- 4D运动令牌化:首次将3D运动序列编码为紧凑令牌,替代传统2D姿态图像。
- 运动感知扩散模型:通过4D位置编码和运动注意力机制,实现时空连贯的动画生成。
- 开放世界泛化能力:在未见风格和动作中保持高保真度,突破传统方法局限。
评估标准
- FID-VID指标:衡量生成视频与真实视频的分布相似性,MTVCrafter达到6.98,超越第二名65%。
- 用户主观评价:在复杂动作(如体操)和跨风格(如水墨画)中,物理合理性与视觉一致性显著优于现有方法。
应用领域
- 数字人生成:为虚拟偶像、元宇宙角色提供自然动画。
- 影视动画:加速动漫、游戏角色动作设计。
- 广告与营销:生成个性化动态广告内容。
- 虚拟试穿:结合3D模型实现动态服装展示。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
