Pixel Reasoner:滑铁卢大学联合港科大等高校推出的视觉语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Pixel Reasoner是由滑铁卢大学、香港科技大学等高校联合研发的视觉语言模型(VLM),专注于提升多模态任务中的视觉理解与语言生成能力。该模型通过创新架构设计,整合视觉编码器与语言模型的跨模态交互,旨在解决传统方法在复杂视觉场景(如高分辨率图像、多对象交互)中理解不足的问题。其核心目标是通过高效融合视觉与文本信息,实现更精准的视觉问答、图像描述生成及跨模态检索等任务,为多模态AI系统提供更强的推理与生成能力。

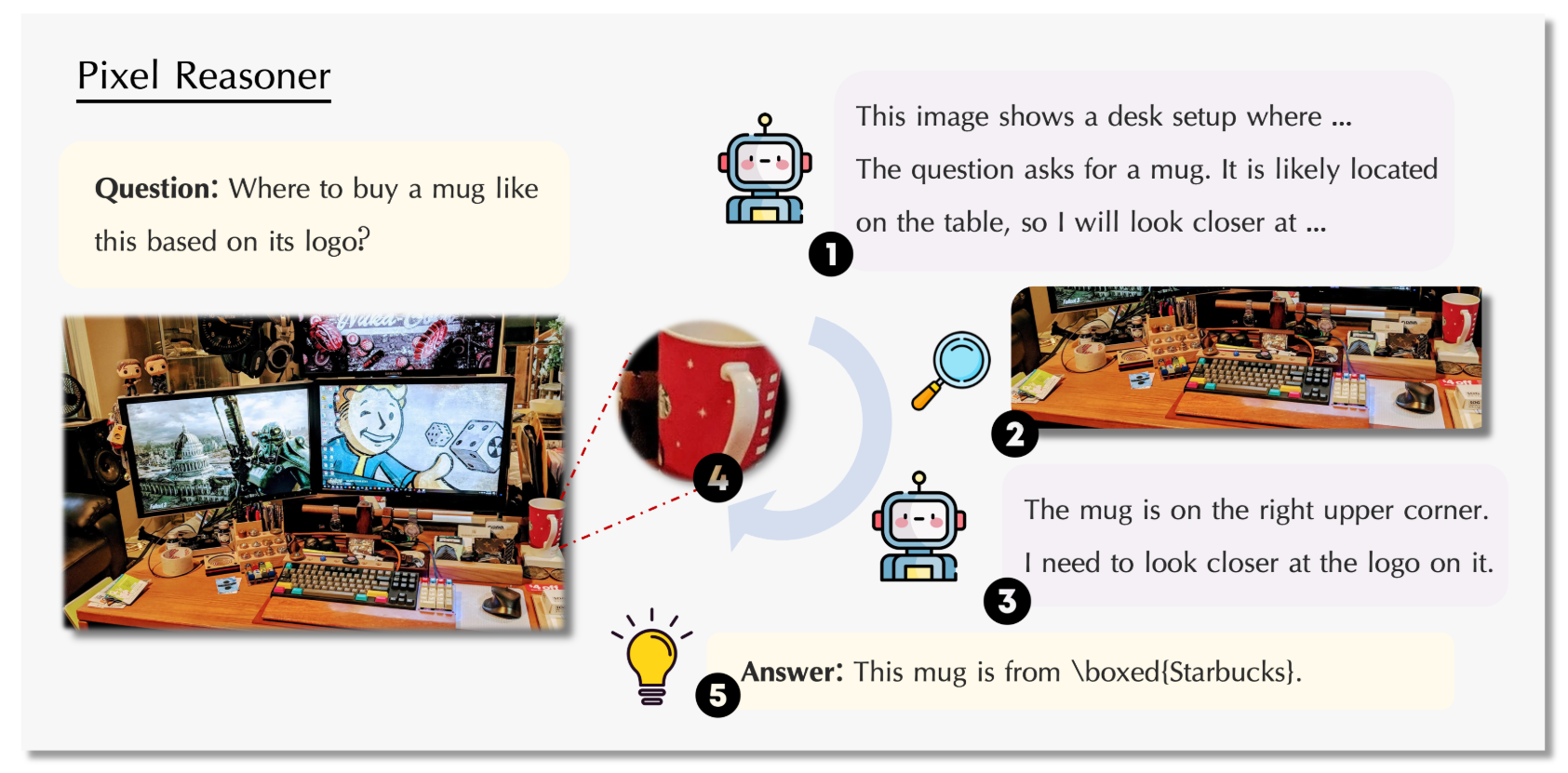
功能特点
- 跨模态深度融合:通过视觉编码器提取图像特征,并与语言模型的文本表示进行对齐,实现视觉与语言的语义关联。
- 高分辨率图像处理:支持对448×448及以上分辨率图像的直接处理,保留细节信息,提升复杂场景下的理解能力。
- 多任务适配性:可应用于视觉问答(VQA)、图像描述生成、跨模态检索及文本引导的图像编辑等任务。
- 零样本学习能力:在未见过的数据或任务中,仍能通过跨模态推理生成合理输出,降低对标注数据的依赖。
优缺点
优点:
- 视觉理解能力强:对高分辨率图像及复杂场景(如多对象、遮挡)的处理效果显著提升。
- 跨模态交互高效:通过优化视觉与语言的特征对齐,减少信息损失,提升生成文本的准确性。
- 灵活性高:支持多任务微调,适配不同应用场景(如医疗、自动驾驶)。
缺点:
- 计算资源需求大:高分辨率图像处理与多模态融合需较大算力支持,部署成本较高。
- 数据依赖性:虽具备零样本能力,但在特定领域(如专业医学图像)中仍需领域数据微调。
- 模型复杂度高:架构设计复杂,训练与优化难度较大,需专业团队支持。
如何使用
- 数据准备:输入图像与对应文本描述(如问题、指令),支持高分辨率图像直接输入。
- 模型推理:通过预训练的Pixel Reasoner模型生成文本输出(如答案、描述)或执行图像编辑任务。
- 后处理:根据需求调整生成文本的格式或图像编辑的参数,优化输出效果。
框架技术原理
- 视觉编码器:采用基于Transformer的架构(如ViT),提取图像的高维特征表示,支持高分辨率输入。
- 语言模型:基于预训练的大规模语言模型(如BERT、GPT),生成与视觉特征对齐的文本。
- 跨模态融合模块:通过注意力机制与投影层,将视觉特征与文本特征映射至同一语义空间,实现深度交互。
- 多任务解码器:针对不同任务(如问答、生成)设计专用解码头,提升任务适配性。
创新点
- 高分辨率视觉处理:直接支持448×448及以上分辨率图像输入,避免传统方法中的降采样损失。
- 动态跨模态对齐:通过自适应注意力机制,动态调整视觉与文本特征的融合权重,提升复杂场景下的理解能力。
- 多任务统一架构:单一模型支持视觉问答、图像描述、跨模态检索等多种任务,降低部署成本。
评估标准
- 视觉问答准确性:在VQAv2、GQA等基准数据集上评估模型回答的准确率。
- 图像描述生成质量:通过BLEU、CIDEr等指标评估生成文本的流畅性与相关性。
- 跨模态检索效率:评估模型在图像-文本匹配任务中的检索速度与精度。
- 零样本学习能力:在未见过的数据或任务中,评估模型的推理与生成能力。
应用领域
- 智能问答系统:为聊天机器人、搜索引擎提供视觉问答能力。
- 无障碍辅助:为视障用户生成图像描述,提升信息获取效率。
- 医疗影像分析:结合医学图像与文本报告,辅助医生诊断。
- 自动驾驶:解析道路场景图像,生成自然语言描述,支持决策系统。
- 内容创作:自动生成图像描述、广告文案,降低人工成本。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
