Vid2World:清华联合重庆大学推出视频模型转为世界模型的框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Vid2World是清华大学与重庆大学联合研发的框架,旨在将预训练的视频扩散模型转化为交互式世界模型(World Model)。传统世界模型依赖大量领域特定训练,难以在复杂环境中生成高保真度预测。Vid2World通过架构改造和训练目标调整,赋予视频模型自回归生成能力,并引入因果动作引导机制,增强动作可控性。该框架在机器人操控、游戏仿真等任务中验证了其可扩展性和有效性,为复杂环境下的顺序决策提供了新范式。

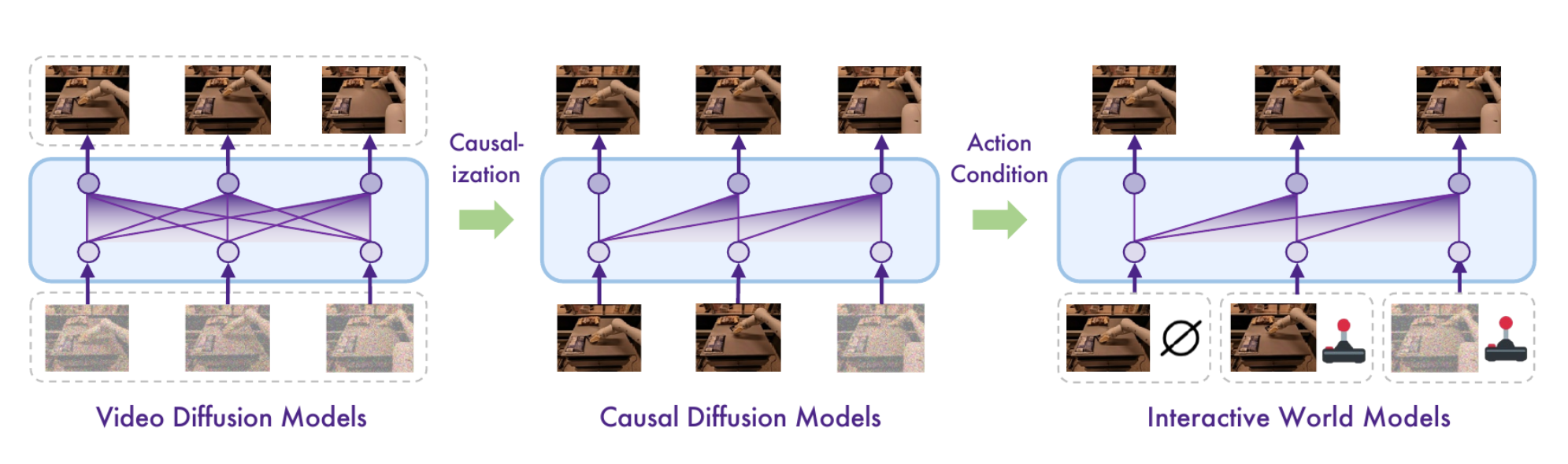
功能特点
- 自回归生成能力:通过改造视频扩散模型架构,实现视频帧的逐步生成,支持长序列预测。
- 因果动作引导:引入动作控制机制,使生成的视频序列与用户输入的动作指令对齐。
- 跨领域适应性:无需大量领域数据,即可在机器人操控、游戏仿真等场景中生成高保真度预测。
- 高效迁移学习:利用预训练视频模型的泛化能力,减少对特定任务数据的依赖。
优缺点
优点:
- 减少训练成本:避免从零开始训练世界模型,利用预训练视频模型的知识迁移。
- 增强可控性:动作引导机制使生成结果更符合用户意图,适用于交互式任务。
- 适应复杂环境:在动态、多变的场景中生成更合理的预测,提升决策效率。
缺点:
- 计算资源需求高:视频扩散模型的预训练和改造需要大量算力支持。
- 动作空间限制:对复杂动作的解析能力有限,可能影响生成结果的多样性。
- 长序列生成稳定性:在长序列生成中可能出现累积误差,需进一步优化。
如何使用
- 环境配置:安装框架依赖库,配置计算资源(如GPU)。
- 模型加载:加载预训练的视频扩散模型和Vid2World改造模块。
- 数据输入:提供初始视频帧和动作序列作为输入。
- 生成预测:运行框架生成后续视频帧,并可视化结果。
- 评估与优化:根据任务需求调整动作引导参数,提升生成质量。
框架技术原理
- 视频扩散模型改造:通过调整模型架构和训练目标,使其支持自回归生成。
- 因果动作引导机制:在生成过程中引入动作编码器,将动作指令嵌入到生成流程中。
- 时空一致性约束:通过损失函数设计,确保生成的视频帧在时间和空间上保持一致。
- 领域自适应技术:利用少量领域数据微调模型,提升在特定任务中的性能。
创新点
- 视频模型到世界模型的转化:首次提出将视频扩散模型改造为世界模型的框架,拓展了视频模型的应用边界。
- 因果动作引导:通过动作编码器实现生成过程的可控性,解决了传统世界模型缺乏交互性的问题。
- 高效知识迁移:利用预训练视频模型的泛化能力,减少对领域特定数据的依赖,加速模型部署。
评估标准
- 生成质量:通过FID(Fréchet Inception Distance)等指标评估生成视频的真实性。
- 动作一致性:衡量生成视频与输入动作指令的匹配程度。
- 长序列稳定性:评估模型在生成长序列视频时的累积误差。
- 任务性能:在机器人操控、游戏仿真等任务中验证模型的决策能力。
应用领域
- 机器人操控:生成机器人执行任务的预测视频,辅助决策规划。
- 游戏仿真:为游戏角色生成智能行为,提升游戏体验。
- 自动驾驶:预测交通场景的动态变化,优化路径规划。
- 虚拟现实:生成交互式环境,增强沉浸感。
项目地址
- 项目官网:https://knightnemo.github.io/vid2world/
- HuggingFace模型库:https://huggingface.co/papers/2505.14357
- arXiv技术论文:https://arxiv.org/pdf/2505.14357
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
