Ming-lite-omni : 蚂蚁集团开源的统一多模态大模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
项目介绍
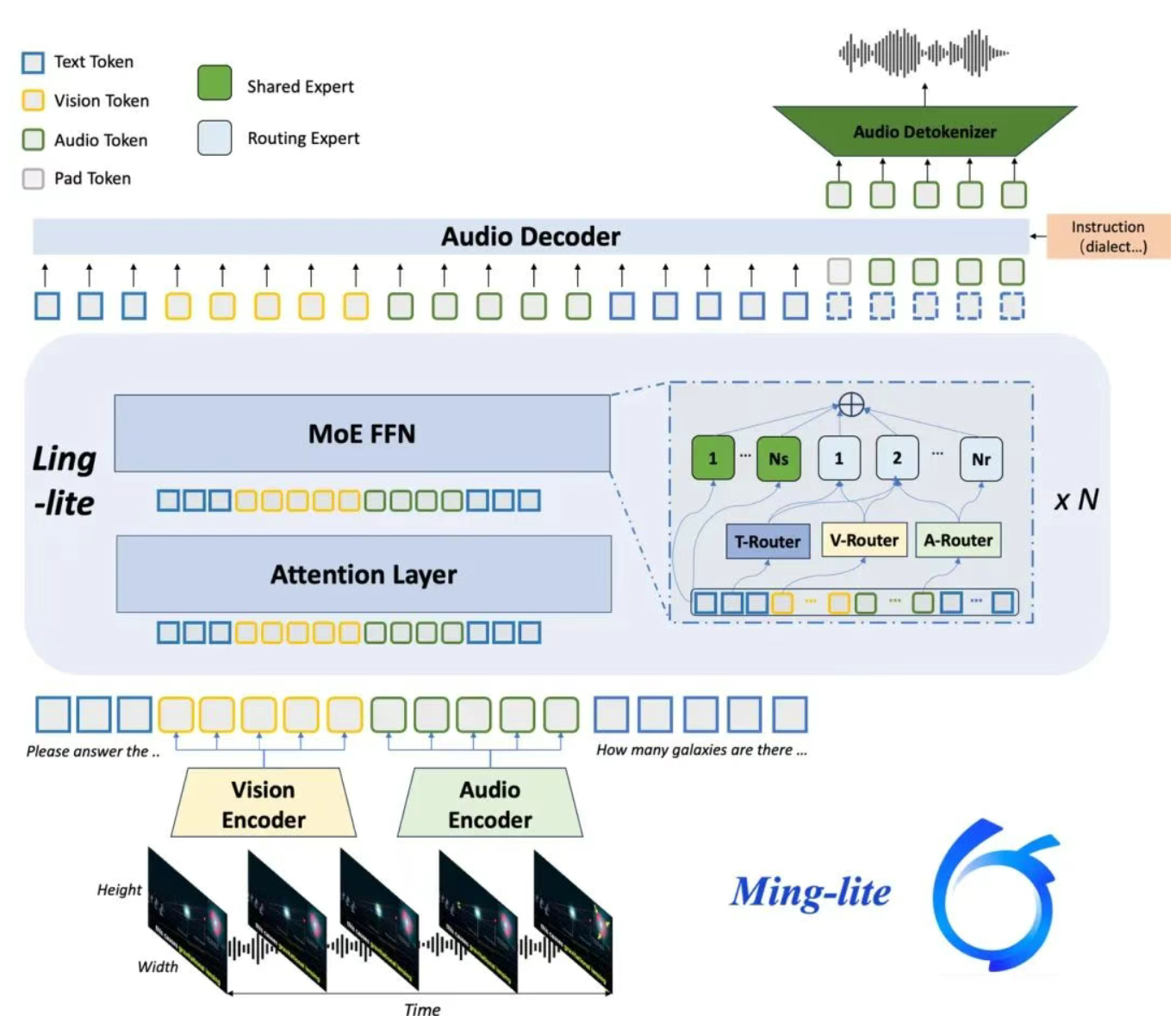
Ming-lite-omni 是蚂蚁集团开源的一款面向多模态交互场景的统一大模型,旨在通过单一架构实现跨模态的理解、生成与交互。该模型以 MoE(Mixture of Experts) 为核心架构,支持文本、图像、音频和视频的输入输出,具备原生全模态交互能力,可同时处理理解和生成任务,适用于复杂场景下的智能交互需求。
功能特点
- 全模态输入输出
- 支持文本、图像、音频、视频的实时交互,无需依赖外部工具即可完成跨模态转换。
- 例如:用户输入语音指令,模型可直接生成文字回复或图像内容。
- 统一理解与生成
- 将理解(如文本分类、图像识别)与生成(如文本生成、图像生成)功能集成到同一模型中,减少任务切换的延迟。
- 轻量化与高效性
- 基于 MoE 架构,模型参数可动态激活,降低计算资源消耗,适合部署在边缘设备或云端。
- 开源与社区支持
- 代码完全开源,提供详细的文档和示例,开发者可快速上手并扩展功能。
优缺点
优点
- 统一架构:避免多模型协同的复杂性,降低开发和部署成本。
- 全模态支持:适用于多种交互场景,如智能客服、多模态搜索等。
- 高效性:MoE 架构优化了计算资源分配,适合大规模应用。
缺点
- 资源需求:尽管轻量化,但全模态处理仍需较高算力,低端设备可能受限。
- 训练数据依赖:多模态模型的性能高度依赖高质量的跨模态数据集。
- 技术成熟度:作为开源项目,部分功能可能需社区进一步优化。
如何使用
- 环境准备
- 安装 Python 3.8+、PyTorch 2.0+ 和其他依赖库。
- 克隆项目仓库:
git clone https://github.com/antgroup/Ming-lite-omni.git
- 模型加载
- 使用预训练模型或加载本地权重文件:

- 使用预训练模型或加载本地权重文件:
- 推理示例
- 文本生成:输入提示词,生成回复。
- 图像生成:输入文本描述,生成对应图像。
- 多模态交互:结合语音输入和图像输出,实现智能对话。
- 微调与扩展
- 支持自定义数据集的微调,开发者可根据需求调整模型行为。

框架技术原理
- MoE 架构
- 通过多个专家网络(Experts)和门控网络(Gating Network)动态选择最优参数,提升模型效率。
- 跨模态对齐
- 使用对比学习(Contrastive Learning)和多模态预训练任务,对齐不同模态的语义空间。
- 自回归生成
- 基于 Transformer 的自回归机制,逐步生成文本、图像或音频内容。
- 流式处理
- 支持实时流式输入输出,适用于语音助手、实时字幕等场景。
创新点
- 统一多模态架构
- 首次将理解与生成任务集成到同一 MoE 模型中,减少模块间通信开销。
- 原生全模态支持
- 不依赖外部 ASR/TTS 工具,直接处理音频输入输出,降低延迟。
- 开源生态
- 提供完整的训练代码和预训练模型,推动多模态技术的社区化发展。
评估标准
- 性能指标
- 准确率:多模态分类任务的准确率。
- 生成质量:文本流畅度、图像清晰度、语音自然度。
- 延迟:端到端推理时间,尤其是流式处理场景。
- 基准测试
- 在多模态数据集(如 COCO、VQA)上评估模型性能。
- 对比其他开源模型(如 LLaVA、MiniGPT-4)的优劣。
应用领域
- 智能客服
- 支持语音、文字、图像的多模态交互,提升用户体验。
- 多模态搜索
- 用户可通过图像或语音查询信息,模型返回文本或视频结果。
- 辅助创作
- 文本生成图像、图像生成视频等创意工具。
- 无障碍技术
- 为视障/听障用户提供跨模态信息转换服务。
项目地址
- HuggingFace模型库:https://huggingface.co/inclusionAI/Ming-Lite-Omni
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
