HunyuanPortrait : 腾讯混元联合清华等机构推出的肖像动画生成框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
项目介绍
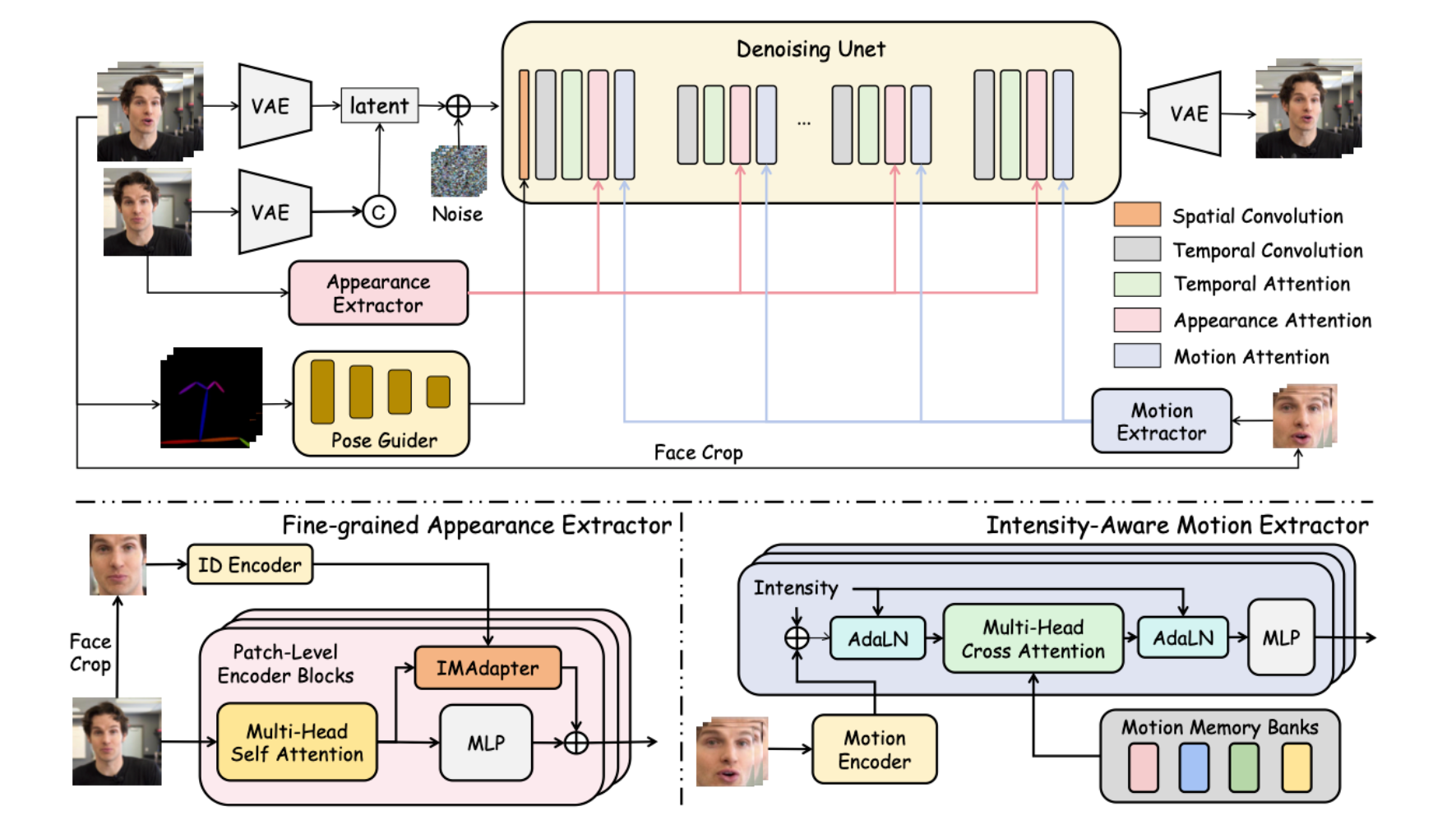
HunyuanPortrait 是由腾讯混元、清华大学、香港科技大学等机构联合研发的基于扩散模型的条件控制肖像动画生成框架,通过隐式表示实现高度可控和逼真的面部动画生成。该框架突破传统方法在身份特征保留与表情建模上的局限性,支持高保真度的肖像动画合成,尤其在处理夸张表情和跨领域风格迁移时展现出显著优势。

功能特点
- 高精度表情控制
- 支持眉毛微挑、眼珠转动、翻白眼等细节化面部动作生成,可精准捕捉微表情变化。
- 跨模态风格迁移
- 支持将静态照片转化为任意风格的脸部动画,包括卡通、雕塑、动物等跨领域风格。
- 多表情-多肖像生成
- 支持单个表情生成多种肖像动画,或单个肖像生成多种表情动画,满足多样化创作需求。
- 渐进式生成策略
- 通过逐步优化实现长期动画合成,确保高保真度和稳定性。
优缺点
优点
- 身份特征高保真:通过表情感知骨架对齐技术,有效避免动画失真和伪影问题。
- 表情细节还原强:面部细粒度损失函数可捕捉微妙表情变化,生成动画高度还原原肖像。
- 跨领域适用性广:支持对卡通、雕塑、动物等非真实领域肖像进行动画化处理。
缺点
- 计算资源需求高:扩散模型训练和推理过程对算力要求较高,可能限制低配设备部署。
- 数据依赖性强:模型性能高度依赖高质量的表情训练数据集,数据稀缺领域效果受限。
- 实时性待优化:渐进式生成策略虽提升质量,但可能增加实时交互场景的延迟。
如何使用
-
环境准备
- 安装 Python 3.8+、PyTorch 2.0+、CUDA 11.0+ 等依赖环境。
- 克隆项目仓库:
git clone https://github.com/kkakkkka/HunyuanPortrait.git
-
模型加载

-
推理示例
- 静态照片转动画:输入人脸照片,指定目标表情(如大笑、眨眼),生成对应动画。
- 风格迁移动画:输入照片和风格参考(如卡通、雕塑),生成跨风格动画。
- 多表情序列生成:输入一系列表情标签,生成连贯的面部动画序列。
-
参数调节
- 表情强度:控制生成动画的表情夸张程度。
- 风格权重:调节原肖像特征与目标风格的融合比例。
- 生成速度:通过调整渐进式生成步数平衡质量与速度。

框架技术原理
- 基于扩散的条件控制
- 利用扩散模型(Diffusion Model)的隐式表示能力,通过条件控制实现精准的肖像动画生成。
- 表情感知骨架对齐
- 引入表情感知骨架作为控制信号,通过 3D 关键点定位技术将目标动作与参考肖像对齐,避免失真。
- 面部细粒度损失函数
- 结合面部掩模和表情掩模,计算真实值与预测结果的空间距离,优化微表情细节和外观还原度。
- 渐进式生成策略
- 采用逐步优化的生成方式,扩展至长期动画合成,确保高保真度和稳定性。
创新点
- 隐式表示与条件控制结合
- 通过扩散模型的隐式表示能力,结合条件控制技术,实现高度可控的肖像动画生成。
- 表情感知骨架对齐技术
- 首次将 3D 关键点定位技术应用于肖像动画生成,有效解决身份特征保留与表情建模的矛盾。
- 跨领域风格迁移能力
- 支持对卡通、雕塑、动物等非真实领域肖像进行动画化处理,拓展应用场景。
评估标准
- 视觉保真度
- 通过定量指标(如 SSIM、PSNR)和定性分析评估生成动画的视觉质量。
- 身份表现力
- 衡量生成动画对原肖像身份特征的保留程度,避免失真和伪影。
- 动作渲染精度
- 评估模型对目标表情的还原能力,包括眉毛、眼珠、嘴角等细节动作。
- 跨领域适用性
- 测试模型在卡通、雕塑、动物等非真实领域肖像动画生成中的表现。
应用领域
- 个性化表情包制作
- 用户上传照片即可生成一系列生动表情动画,满足社交媒体个性化需求。
- 虚拟形象驱动
- 为虚拟主播、数字人等提供高保真度的面部动画驱动能力。
- 影视动画制作
- 辅助动画师快速生成角色面部表情动画,提升制作效率。
- 游戏角色设计
- 为游戏角色提供多样化的面部表情和动作,增强角色表现力。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
