OmniSync – 人民大学联合快手、清华推出的通用对口型框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
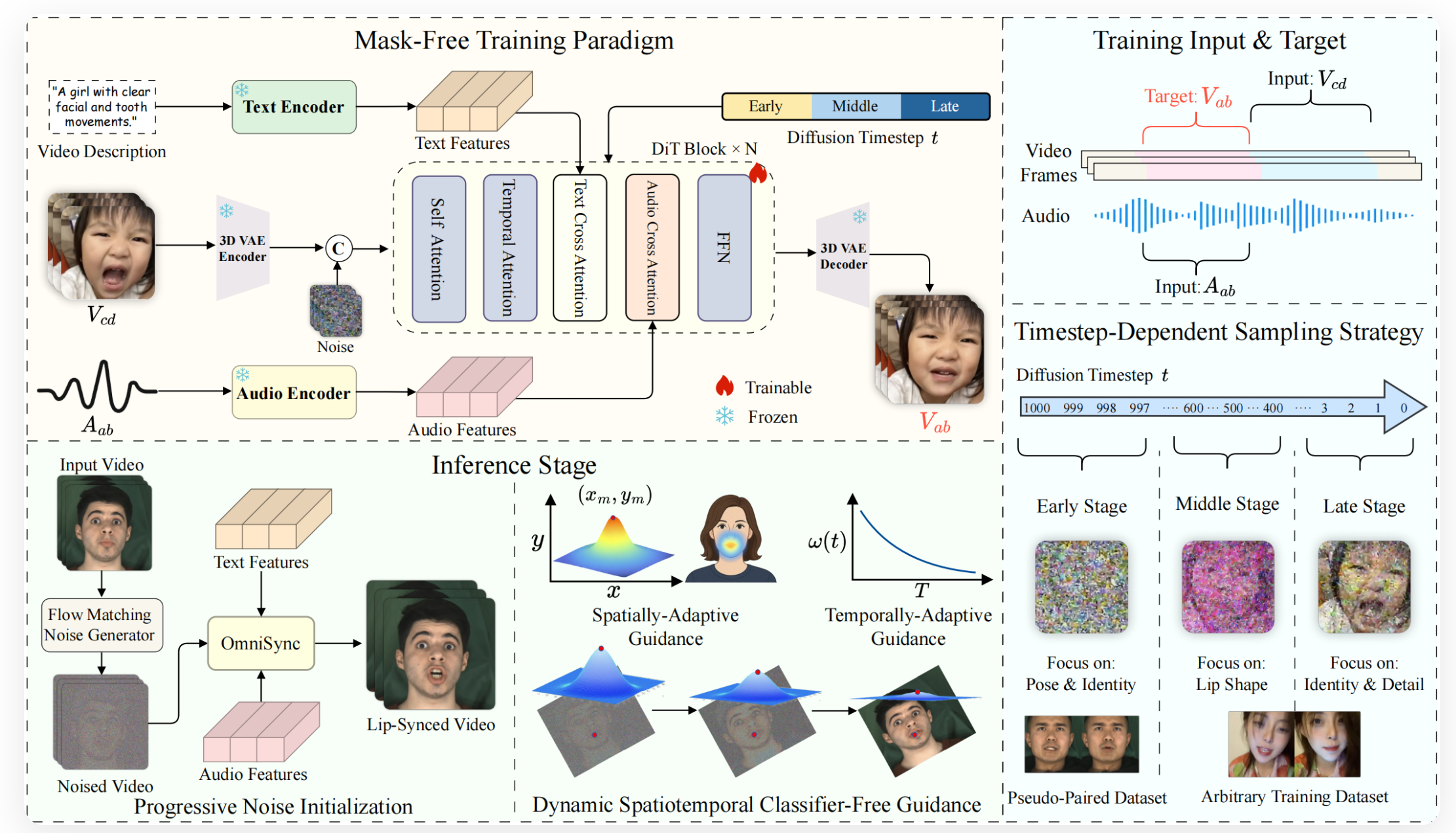
OmniSync是由中国人民大学高瓴人工智能学院、快手未来媒体智能联合实验室及清华大学相关团队共同研发的通用唇同步框架,旨在解决传统唇同步技术在身份一致性、姿势变化及面部遮挡场景下的鲁棒性问题。该框架基于扩散变换器模型,支持无限时长推理,并兼容风格化、非人类及AI生成内容,通过无掩膜训练范式与动态时空无分类引导机制,实现高质量唇部动作生成与面部动态的自然融合。其技术突破为短视频制作、虚拟数字人及影视特效等领域提供了高效解决方案。

功能特点
- 无掩膜训练范式
- 无需依赖参考帧和显式掩膜,直接对视频帧进行编辑,支持无限时长推理,降低对输入数据的依赖性。
- 姿势与身份一致性
- 通过基于流匹配的渐进噪声初始化方法,确保头部姿态和人物身份在唇同步过程中保持稳定,避免因姿势变化导致的身份混淆。
- 动态时空无分类引导(CFG)
- 自适应调整音频引导强度,优化唇同步效果的同时保留面部细节,提升复杂场景下的鲁棒性。
- 遮挡鲁棒性
- 即使面部部分被遮挡,仍能保持准确的唇同步效果,适应动态拍摄环境中的不确定性。
- 风格多样性
- 支持风格化角色与艺术化表现形式,兼容真实人物、2D/3D虚拟形象及AI生成内容。
优缺点
优点
- 高度身份一致性:在不同姿态和表情下,仍能保持人物身份的稳定识别。
- 强鲁棒性:在面部遮挡、复杂光照等条件下,唇同步效果依然精准。
- 无限时长推理:突破传统方法的时长限制,支持长视频内容的唇同步处理。
- 通用兼容性:适配多种视觉场景,包括风格化内容与非人类角色。
缺点
- 计算资源需求:扩散变换器模型对硬件要求较高,需高性能GPU支持实时推理。
- 复杂场景下的微调:在极端表情或快速动作中,唇同步精度可能略有下降,需进一步优化。
如何使用
- 接入API或SDK
- 开发者可通过快手开放平台或GitHub获取OmniSync的API接口或SDK工具包,集成至现有视频编辑系统。
- 上传输入数据
- 输入视频文件与对应的音频文件,支持多种格式(如MP4、WAV)。
- 参数配置
- 调整唇同步强度、风格化程度等参数,优化输出效果。
- 生成与导出
- 系统自动处理并生成唇同步后的视频,支持导出为常见格式(如MP4、GIF)。
框架技术原理
- 扩散变换器模型
- 基于Transformer架构,通过自注意力机制捕捉音频与视频帧之间的时空关联性,实现端到端的唇同步生成。
- 流匹配与渐进噪声初始化
- 在推理过程中,采用流匹配算法对噪声进行渐进式初始化,确保生成结果的连续性与一致性。
- 动态时空无分类引导(CFG)
- 结合音频信号的时序特征,动态调整引导强度,优化唇部动作的精确性与自然度。
- 时间步依赖采样
- 通过时间步依赖的采样策略,逐步细化唇部区域的生成细节,提升整体视觉质量。
创新点
- 无掩膜训练范式
- 消除对显式掩膜的依赖,简化数据预处理流程,提升模型泛化能力。
- 统一框架支持多场景
- 兼容真实人物、虚拟形象及AI生成内容,突破传统方法的场景限制。
- 动态时空无分类引导
- 自适应调整音频引导强度,平衡唇同步精度与面部细节保留。
- 基于流匹配的渐进初始化
- 确保头部姿态与身份一致性,支持复杂姿势下的稳定生成。
评估标准
- 唇同步精度
- 通过音视频对齐误差(如Mel-Cepstral Distortion, MCD)评估唇部动作与音频的匹配程度。
- 身份一致性
- 采用人脸识别准确率(如FaceNet相似度)衡量人物身份在唇同步过程中的保持效果。
- 鲁棒性测试
- 在遮挡、复杂光照及快速动作等场景下,评估模型的稳定性与准确性。
- 用户主观评价
- 通过问卷调查收集用户对生成结果的自然度、真实感的评分。
应用领域
- 短视频与直播
- 为创作者提供高效的唇同步工具,提升视频内容的趣味性与互动性。
- 虚拟数字人
- 优化虚拟主播、数字偶像的口型表现,增强其真实感与表现力。
- 影视与游戏
- 辅助动画制作与游戏角色配音,减少人工调整成本。
- 教育与无障碍
- 生成教学视频中的唇同步内容,提升听力障碍者的观看体验。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
