CoGenAV:通义大模型联合相关团队推出的多模态语音表征模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
CoGenAV主要介绍
CoGenAV是通义大模型联合相关团队推出的多模态语音表征模型,通过学习音频、视觉和文本之间的时序对齐关系,显著提升噪声环境下的语音识别能力。该模型采用“对比生成同步”策略,精准对齐音视频特征,在多个视听任务中刷新了SOTA记录,并已开源。
功能特点
- 多模态对齐:可实现语音、唇部运动和文本的多模态对齐,通过对比生成同步训练方法,高效学习视听表示。
- 任务多样:在视听语音识别(AVSR)、视觉语音识别(VSR)、视听语音增强和分离(AVSE/AVSS)、活跃说话人检测(ASD)等多个任务中表现出色。
- 数据高效:仅使用223小时的标注数据(来自LRS2数据集)即可训练高性能模型。
- 部署便捷:可直接接入现有的主流语音识别模型,如Whisper,无需进行复杂的修改或微调。
优缺点
优点:
- 性能卓越:在嘈杂环境下,音视频语音识别(AVSR)性能提升超过80%,语音增强与分离(AVSE/AVSS)表现超过之前的先进模型,主动说话人检测(ASD)准确率高达96.3%。
- 成本低廉:训练数据量相对较少,部署门槛低,能节省大量的训练成本。
- 抗噪能力强:在噪声环境下仍能保持较高的语音识别准确率。
缺点:
- 数据依赖:虽然训练数据量相对较少,但高质量的多模态标注数据获取仍有一定难度。
- 模型复杂度:模型采用了较为复杂的架构和训练策略,对计算资源和开发者的技术要求较高。
如何使用
- 安装依赖:确保安装了whisper和fairseq等必要的依赖库,可通过
pip install -r requirements.txt安装相关依赖。 - 加载模型:克隆项目代码后,加载CoGenAV模型和预训练的语音识别模型(如Whisper)。
- 准备输入:根据任务需求,准备视频、音频等输入数据。
- 推理输出:使用加载的模型对输入数据进行处理,得到语音识别、语音增强与分离等任务的输出结果。具体推理脚本可参考项目文档,如
python infer_vsr_avsr.py --input_type cogenav_av --model_size large --cogenav_ckpt weights/large_cogenav.pt。
框架技术原理
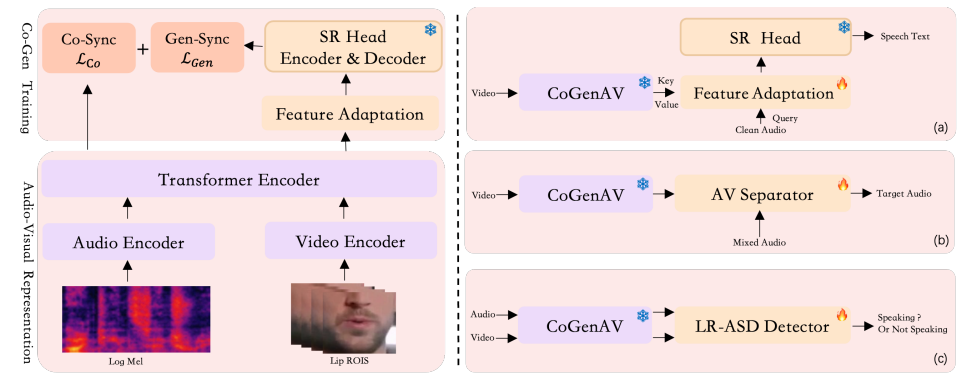
- 对比生成同步策略:包括特征提取、对比同步和生成同步三个步骤。特征提取阶段,观察说话时的嘴型(通过分析视频),同时提取音频中的语音信息;对比同步阶段,加强音频和视频特征之间的关联;生成同步阶段,利用预先训练好的语音识别模型,将音视频信息与相应的文字对应起来。
- 视听特征表示框架:设计了特征适应模块,并使用一个冻结的预训练ASR模型作为语音识别(SR)头,实现音视频特征的融合和处理。
创新点
- 对比生成同步方法:通过对比生成同步策略,精准对齐音视频特征,提高了跨模态信息的融合效率。
- 高效学习视听表示:仅使用少量标注数据即可训练高性能模型,降低了数据成本。
- 多任务适用性:在多个视听任务中表现出色,具有较强的通用性。
评估标准
- 视觉语音识别(VSR)和音视频语音识别(AVSR):使用词错率(WER)作为评估指标,在LRS2数据集上进行评估。
- 视听语音分离(AVSS)和视听语音增强(AVSE):使用SI-SNRi、SDRi和PESQ等指标进行评估,这些指标代表每个测试集中所有说话人的平均值,较大的值表示性能更好。
- 主动说话人检测(ASD):使用平均精度均值(mAP)作为评估指标。
应用领域
- 语音识别:在嘈杂环境下实现更准确的语音识别,可用于智能语音助手、语音导航等场景。
- 语音增强与分离:从混合语音中分离出目标语音或增强语音清晰度,可用于会议录音、语音通话等场景。
- 活跃说话人检测:准确判断出谁在说话,可用于视频会议、监控系统等场景。
项目地址
- Github仓库:https://github.com/HumanMLLM/CoGenAV
- HuggingFace模型库:https://huggingface.co/detao/CoGenAV
- arXiv技术论文:https://arxiv.org/pdf/2505.03186
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
