VRAG-RL:阿里通义推出的多模态RAG推理框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
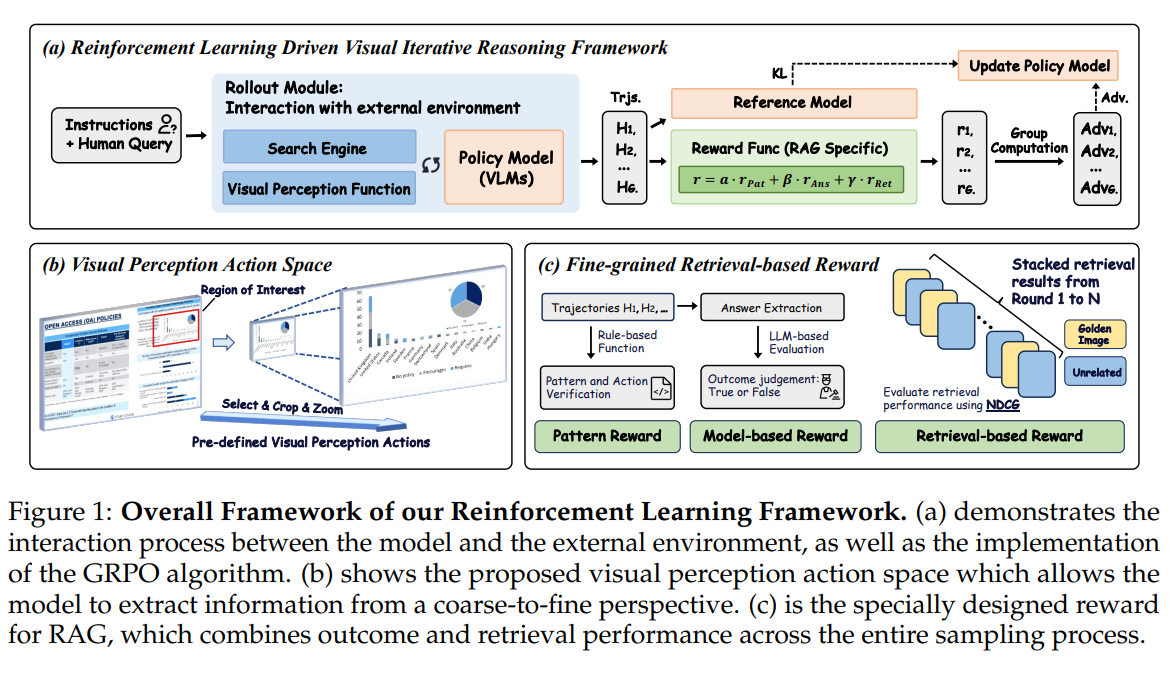
VRAG-RL(Vision-Retrieval Augmented Generation with Reinforcement Learning)是阿里巴巴通义实验室研发的多模态检索增强生成(RAG)推理框架,专为处理复杂视觉语言任务设计。该框架通过强化学习驱动多模态智能体,结合视觉感知动作与多轮交互机制,解决传统RAG方法在视觉信息理解、动态推理能力上的不足,显著提升模型在图表解析、布局识别等视觉丰富场景中的性能。

功能特点
- 视觉感知驱动
- 定义区域选择、裁剪、缩放等视觉感知动作,支持从粗粒度到细粒度逐步聚焦信息密集区域,精准提取关键视觉信息。
- 示例:处理复杂图表时,模型先提取整体信息,再通过裁剪和缩放聚焦关键数据区域。
- 多轮交互推理
- 支持与搜索引擎的多轮交互,动态调整检索策略,实现检索与推理的双向优化。
- 通过细粒度奖励机制(检索效率、模式一致性、生成质量)引导模型优化路径,形成闭环优化。
- 高效检索与推理协同
- 引入GRPO算法,通过本地部署搜索引擎模拟真实场景,实现零成本调用,提升训练效率。
- 结合大规模模型推理能力与专家模型精确标注,学习高效视觉感知策略。
优缺点
优点
- 视觉理解能力强:通过视觉感知动作和多轮交互,显著提升对图像、图表等复杂视觉信息的理解能力。
- 检索效率高:细粒度奖励机制和动态检索策略优化检索路径,减少冗余信息干扰。
- 泛化能力强:在多跳推理、文本-图表混合任务等多种场景中表现优异。
缺点
- 计算资源需求高:强化学习训练和大规模模型推理依赖高性能GPU,成本较高。
- 复杂任务依赖高质量标注:专家模型标注的准确性直接影响模型性能,标注成本较高。
如何使用
- 环境配置
- 安装依赖库(如PyTorch、Hugging Face Transformers等)。
- 下载预训练模型(如Qwen2.5-VL系列)和框架代码(GitHub开源)。
- 数据准备
- 准备多模态数据集(文本、图像、图表等),支持单跳或多跳推理任务。
- 模型训练
- 使用GRPO算法进行强化学习训练,配置视觉感知动作空间和奖励函数。
- 示例命令:
- 推理与评估
- 加载训练好的模型,输入查询并生成答案,支持多轮交互优化。
- 使用评估指标(如NDCG、ROUGE、BLEU)验证模型性能。
框架技术原理
- 视觉感知动作空间
- 定义区域选择、裁剪、缩放等动作,使模型能够动态调整视觉焦点,逐步聚焦关键信息。
- 强化学习训练
- 采用GRPO算法,通过多轮交互优化检索与推理策略。
- 奖励函数综合检索效率、模式一致性和生成质量,引导模型优化路径。
- 多模态融合
- 结合文本、图像、图表等多模态信息,通过统一语义空间实现跨模态推理。
创新点
- 视觉感知驱动的RAG范式
- 首次将视觉感知动作引入RAG框架,实现从粗到细的信息获取。
- 动态检索与推理协同
- 通过多轮交互和细粒度奖励机制,实现检索与推理的双向优化。
- 零成本搜索引擎调用
- 本地部署搜索引擎模拟真实场景,提升训练效率,降低资源消耗。
评估标准
- 检索性能
- 使用NDCG(归一化折损累积增益)评估检索效率,衡量模型对相关图像内容的优先检索能力。
- 生成质量
- 使用ROUGE、BLEU、BERTScore等指标评估生成答案的准确性、连贯性和语义一致性。
- 推理深度
- 通过多跳推理任务(如从图表数据推导结论)评估模型的逻辑推理能力。
应用领域
- 多模态问答
- 结合文本与图像进行复杂推理,回答跨模态问题(如“图表中某指标的变化趋势是什么?”)。
- 智能文档分析
- 解析财务报告、学术论文等复杂文档,提取关键数据并生成总结。
- 教育辅助
- 解析教材中的图表、公式,提供详细解答和推理过程。
- 医疗影像分析
- 结合医学影像与文本报告,辅助医生进行疾病诊断。
项目地址
- GitHub仓库:https://github.com/Alibaba-NLP/VRAG
- HuggingFace模型库:https://huggingface.co/collections/autumncc/vrag-rl
- arXiv技术论文:https://arxiv.org/pdf/2505.22019
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
