DeepEyes:小红书联合西安交大推出的多模态深度思考模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
DeepEyes是由小红书与西安交通大学联合研发的多模态深度思考模型,专注于通过强化学习实现图像与文本的动态交互推理。该模型突破传统多模态思维链(MCoT)依赖静态文本输入的局限,创新性地引入图像工具调用机制,允许模型在推理过程中自主决定是否调用图像缩放、细节聚焦等工具,从而在复杂视觉场景中实现更精准的感知与推理。

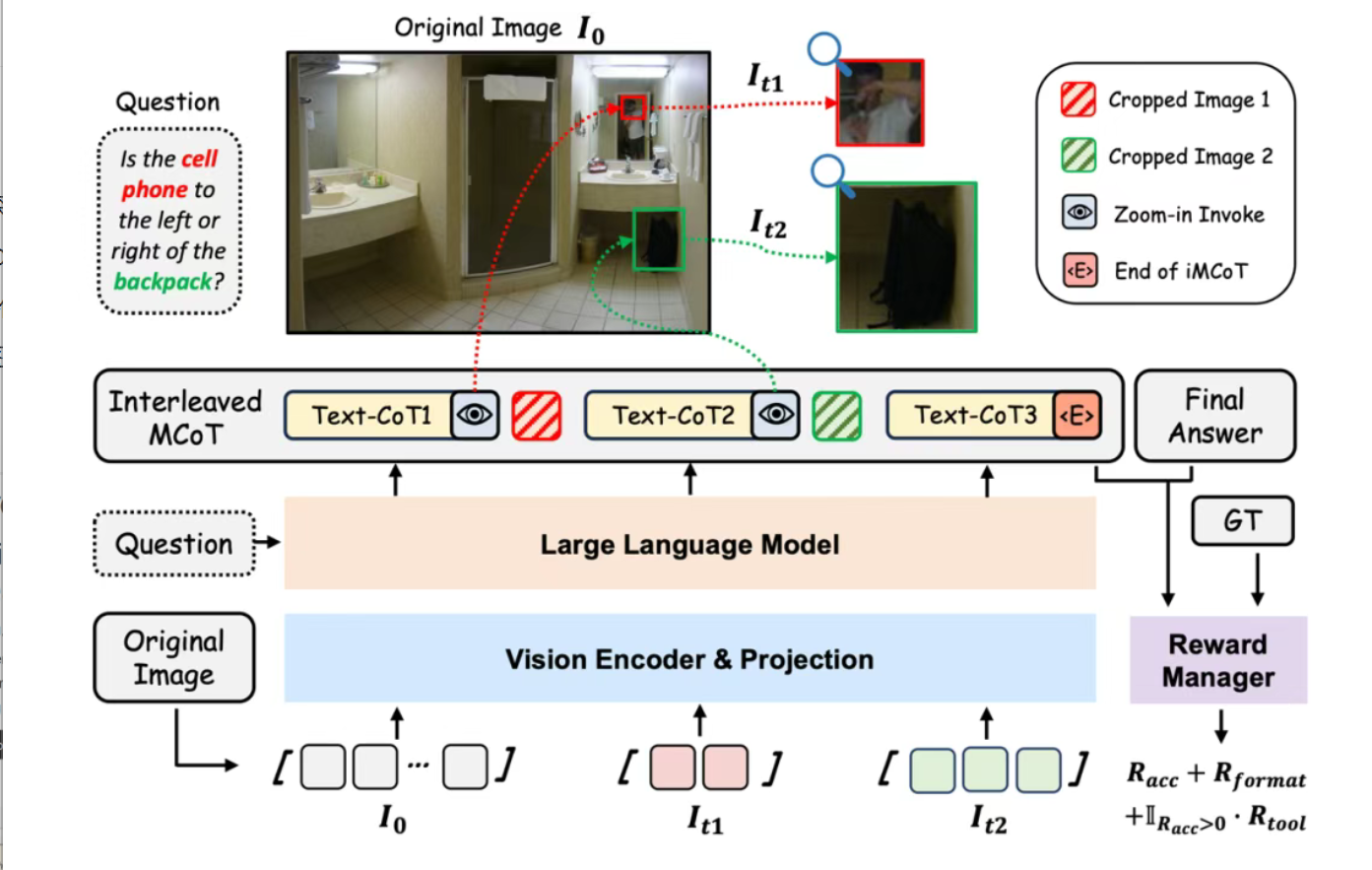
功能特点
- 动态工具调用能力
- 模型可根据任务需求自主调用图像缩放工具,动态聚焦图像细节区域(如小物体或模糊区域),实现细粒度感知。
- 支持多轮视觉-文本交替推理,逐步优化对高分辨率图像(2K-8K)中微小目标的定位能力。
- 端到端强化学习训练
- 通过强化学习(RL)直接从结果奖励中学习视觉-文本整合能力,无需依赖监督微调(SFT)或外部工具。
- 采用Group Relative Policy Optimization(GRPO)算法,优化策略以提升工具调用效率。
- 多模态思维链(iMCoT)
- 构建交替多模态思维链(Interleaved Multi-modal Chain-of-Thought),将视觉信息动态融入推理过程,模拟人类视觉认知模式。
- 工具导向的数据筛选策略
- 通过难度控制、问题格式重构和工具增益优先等策略,筛选高质量训练数据,提升模型泛化能力。
优缺点
优点
- 高分辨率感知能力:在2K-8K图像中实现微小目标的精准定位,IoU(交并比)从0.2提升至0.7。
- 动态推理机制:通过工具调用实现视觉-文本的动态交互,适应复杂视觉场景。
- 零冷启动依赖:无需SFT或外部工具,直接从结果奖励中学习视觉-文本整合能力。
缺点
- 计算资源需求高:端到端强化学习训练依赖高性能GPU,成本较高。
- 工具调用次数限制:模型在推理过程中存在最大工具调用次数限制,可能影响复杂任务的处理效率。
如何使用
- 环境配置
- 安装PyTorch、Hugging Face Transformers等依赖库。
- 下载DeepEyes模型代码与预训练权重(GitHub开源地址)。
- 数据准备
- 准备高分辨率图像数据集(如V* Bench、HR-Bench),支持2K-8K图像输入。
- 配置工具调用指令集(如图像缩放、区域裁剪等)。
- 模型训练
- 使用GRPO算法进行强化学习训练,配置奖励函数(任务准确性、输出格式规范性、工具调用效率)。
- 示例命令:python train.py –model_name DeepEyes –dataset_path ./data –output_dir ./models –max_tools 6
- 推理与评估
- 加载训练好的模型,输入用户问题与原始图像,生成最终答案。
- 使用评估指标(如准确率、IoU、幻觉抑制率)验证模型性能。
框架技术原理
- Markov决策过程(MDP)
- 状态(s_t):由历史文本标记(X_t)和图像观察标记(I_t)拼接而成。
- 动作(a_t):模型生成的下一个标记(文本或工具调用指令)。
- 奖励信号(R):综合任务准确性、输出格式规范性与工具调用效率。
- 工具调用机制
- 模型在每一步推理中可生成文本或调用工具(如图像缩放)。
- 若调用工具,则输入图像坐标系,裁剪指定区域并插入推理轨迹作为后续输入。
- 训练动态与推理模式
- 初始探索阶段:频繁但低效调用工具,裁剪区域IoU低,响应冗余。
- 高频调用阶段:通过工具奖励最大化快速提升准确率,但依赖过度外部查询。
- 高效利用阶段:选择性调用工具,减少次数但维持高IoU与准确率,形成隐式规划机制。
创新点
- 无需SFT的视觉-文本整合
- 通过端到端强化学习直接从结果奖励中学习视觉-文本整合能力,突破传统MCoT依赖静态文本输入的局限。
- 动态工具调用机制
- 允许模型在推理过程中自主决定是否调用图像工具,实现视觉-文本的动态交互,适应复杂视觉场景。
- 工具导向的数据筛选策略
- 通过难度控制、问题格式重构和工具增益优先等策略,筛选高质量训练数据,提升模型泛化能力。
评估标准
- 高分辨率感知(准确率)
- 在2K-8K图像中实现微小目标的精准定位,评估模型对高分辨率图像的感知能力。
- 视觉定位(IoU)
- 评估模型在工具调用过程中对图像细节区域的裁剪精度,IoU越高表示定位越准确。
- 幻觉抑制(POPE)
- 评估模型生成答案的准确性,抑制虚假信息(幻觉)的产生。
- 数学推理(ThinkLite-VL)
- 评估模型在数学与逻辑分析任务中的表现,验证其多模态推理能力。
应用领域
- 高分辨率图像分析
- 在医学影像、卫星遥感等领域实现微小目标的精准定位与分析。
- 复杂视觉场景理解
- 在自动驾驶、机器人导航等领域实现动态视觉-文本交互推理,适应复杂环境。
- 多模态问答系统
- 在智能客服、教育辅导等领域实现图像与文本的深度融合,提升问答系统的准确性。

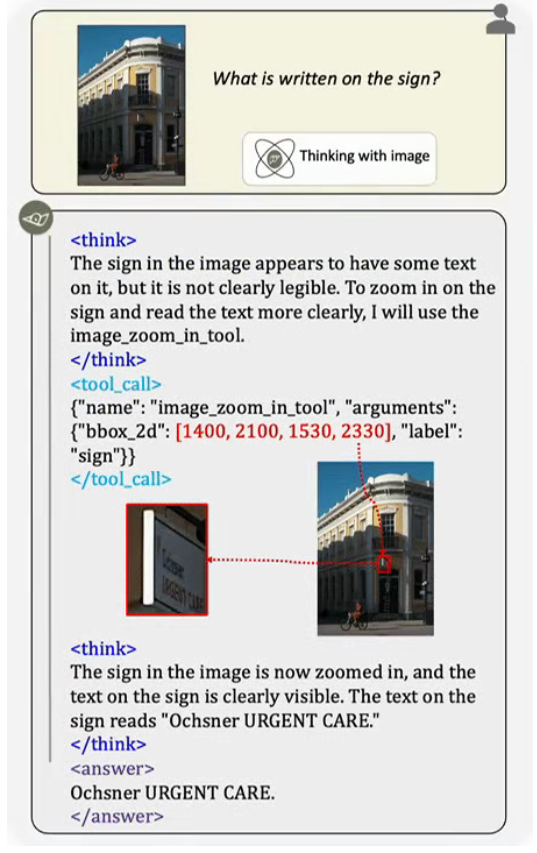
项目地址
- GitHub开源地址:https://github.com/Visual-Agent/DeepEyes
- 论文地址:arXiv:2505.1436
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
