Qwen3 Reranker : 阿里通义开源的文本重排序模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Qwen3 Reranker 是阿里巴巴通义实验室开源的文本重排序模型,属于 Qwen3 系列模型的一部分,专为提升搜索和推荐系统的相关性排序能力而设计。该模型基于 Qwen3 基础模型构建,支持 119 种语言及编程语言,提供 0.6B、4B、8B 三种参数规模,适用于不同场景下的性能与效率需求。Qwen3 Reranker 在文本检索场景中显著提升搜索结果的相关性,尤其在多语言检索任务中表现优异,能够处理长文档排序,支持法律文书、科研论文等复杂场景。

功能特点
- 多语言支持:支持 119 种自然语言及编程语言,适用于跨语言检索和排序任务。
- 长文本处理:上下文窗口达 32k tokens,能够处理法律文书、科研论文等长文档,确保语义连贯性。
- 高效排序:在 100 文档排序任务中,延迟压至 80ms 内(A100 显卡),满足实时性要求。
- 任务指令微调:支持自定义指令(如“按病例描述相关性排序”),优化特定领域性能,实测可提升排序准确率 3%-5%。
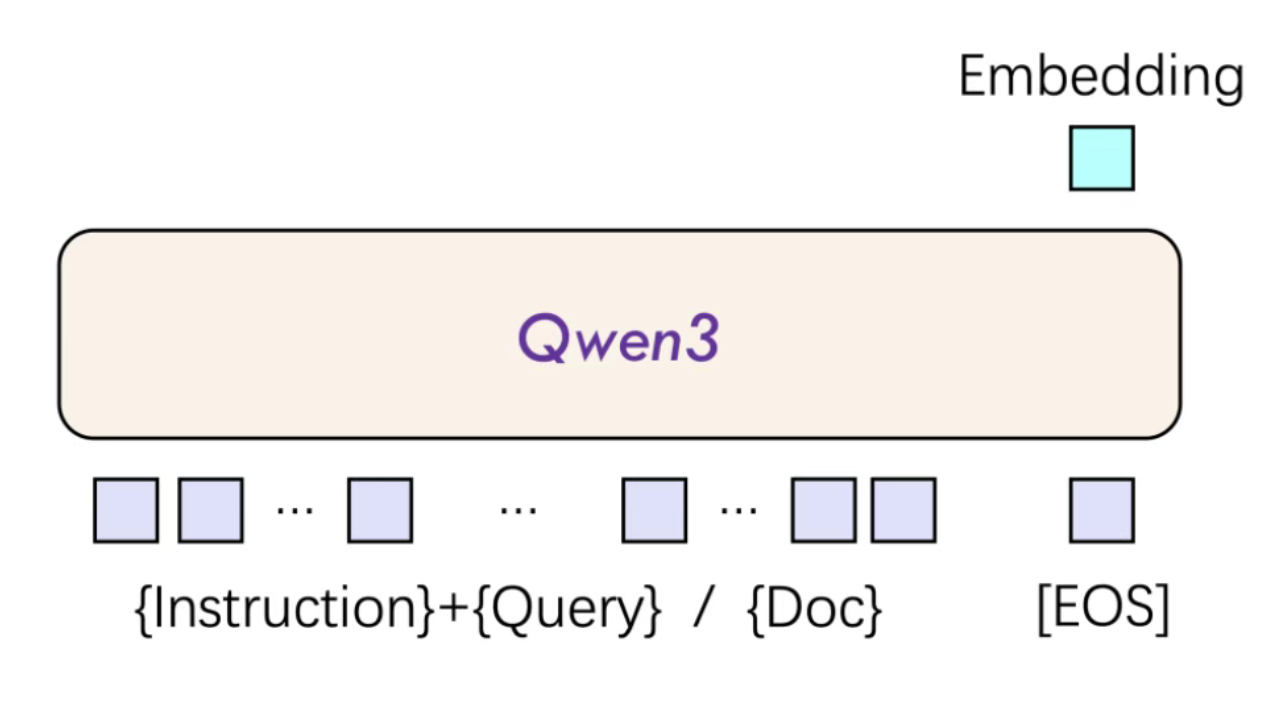
- 单塔交互结构:将用户查询与候选文档拼接输入,通过动态计算查询-文档交互特征输出相关性得分,实现非静态向量匹配的实时排序。
优缺点
优点:
- 多语言与长文本处理能力强:支持 119 种语言,32k 上下文窗口,适用于复杂场景。
- 排序效率高:在 100 文档排序任务中延迟低,满足实时性需求。
- 支持任务指令微调:可根据特定领域需求优化性能,提升排序准确率。
缺点:
- 模型规模较大:8B 参数模型对硬件要求较高,可能限制在资源受限环境下的部署。
- 依赖高质量标注数据:虽然支持指令微调,但性能提升仍需依赖高质量的标注数据。
如何使用
- 通过 Hugging Face 使用:
- 访问 Hugging Face Qwen3 Reranker 页面,选择适合的模型版本(0.6B、4B 或 8B)。
- 使用以下代码加载模型并进行推理:from transformers import AutoTokenizer, AutoModelForSequenceClassification model_name = “Qwen/Qwen3-Reranker-8B” # 选择适合的模型版本 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name) query = “What is the capital of France?” document = “The capital of France is Paris.” inputs = tokenizer(query, document, return_tensors=”pt”, truncation=True, max_length=512) outputs = model(**inputs) score = outputs.logits.item() # 获取相关性得分
- 通过阿里云 API 使用:
- 访问阿里云官方文档,获取 API 密钥和调用方式。
- 使用 API 调用模型进行文本重排序。
框架技术原理
Qwen3 Reranker 基于 Qwen3 基础模型的稠密版本构建,采用单塔交互结构。其技术原理包括:
- 输入处理:将用户查询与候选文档拼接输入,形成文本对。
- 特征计算:通过动态计算查询-文档交互特征,输出相关性得分。
- 长文本处理:集成 RoPE 位置编码与双块注意(Dual Chunk Attention)机制,有效避免长程信息丢失,确保 32k 上下文内语义连贯性。
- 模型融合:采用基于球面线性插值的模型融合技术,提升模型的稳定性和一致性。
创新点
- 长文档排序优化:32k 上下文窗口专为法律文书、科研论文等长文档排序优化,显著提升长文本处理稳定性。
- 任务指令微调:支持自定义指令优化特定领域性能,实测可提升排序准确率 3%-5%,而竞品如 ColBERT 缺乏此类功能。
- 多语言与跨语言支持:支持 119 种语言及编程语言,适用于跨语言检索和排序任务。
评估标准
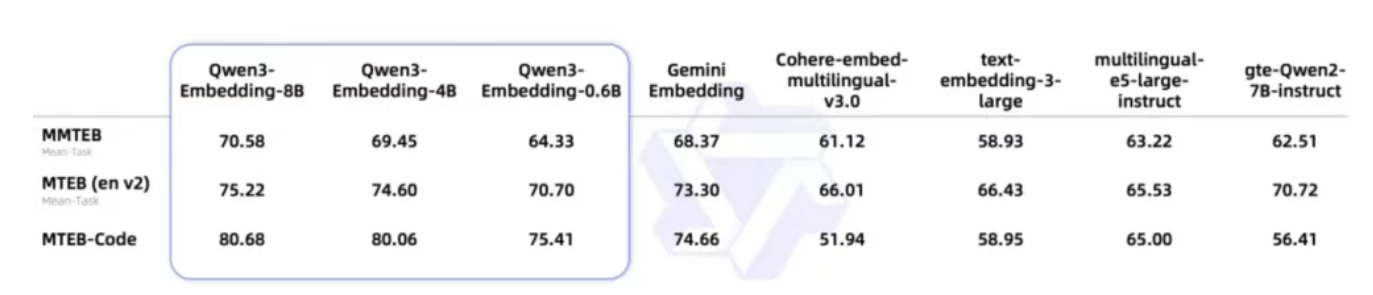
- 多语言检索任务:在 MTEB-R、CMTEB-R、MMTEB-R 等检索子集上表现优异,8B 模型在多语言检索任务中取得了 69.02 的高分。
- 中文检索任务:得分达到 77.45,显著优于其他基线模型。
- 英文检索任务:得分达到 69.76,表现优异。
- 排序延迟:在 100 文档排序任务中,延迟压至 80ms 内(A100 显卡),满足实时性需求。
应用领域
- 搜索引擎:提升搜索结果的相关性,优化用户体验。
- 推荐系统:根据用户查询和候选文档的相关性,优化推荐结果。
- 知识库问答:结合检索模型和生成模型,先从知识库检索相关信息,再由生成模型基于检索结果生成自然语言回答。
- 法律与科研:处理法律文书、科研论文等长文档的排序任务。
项目地址
- Hugging Face:Qwen3 Reranker 集合
- GitHub:Qwen3-Embedding 仓库(Qwen3 Reranker 相关代码可能在此仓库或关联仓库中)
- ModelScope:Qwen3 Reranker 集合
- 技术报告:Qwen3 系列模型技术报告(包含 Qwen3 Reranker 的详细技术原理和评估结果)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
