OpenAudio S1 : Fish Audio推出的新一代语音生成模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
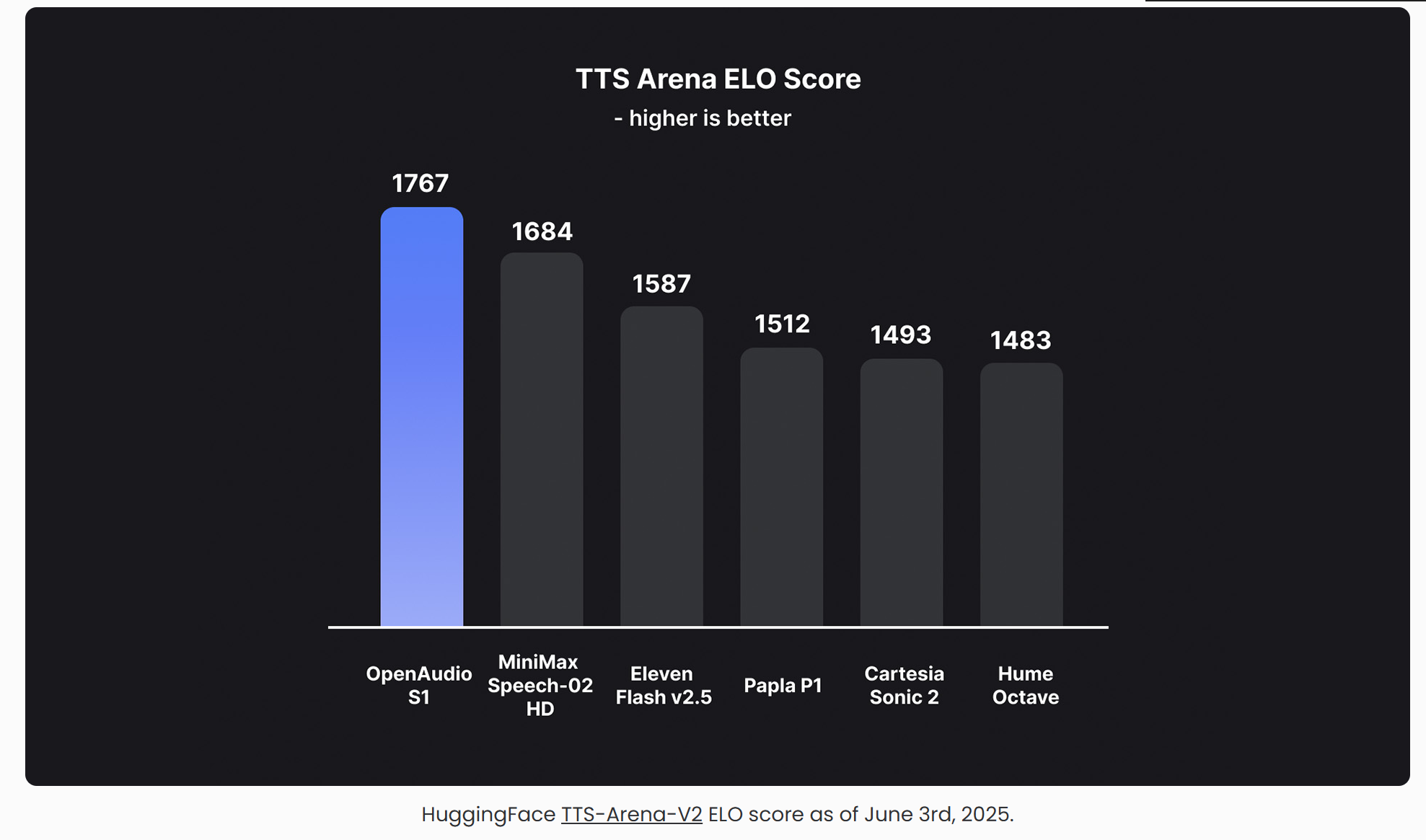
OpenAudio S1是Fish Audio推出的新一代文本转语音(TTS)模型,基于超过200万小时的音频数据训练,支持13种语言,采用双自回归(Dual-AR)架构和强化学习与人类反馈(RLHF)技术,生成的声音高度自然、流畅,几乎与人类配音无异。该模型在TTS-Arena排行榜中荣登第一,成为文本转语音领域的新标杆,适用于视频配音、播客、游戏角色语音等专业场景。

功能特点
- 高度自然的声音:生成的声音流畅、逼真,适用于专业场景,如视频配音、播客和游戏角色语音。
- 丰富的情感和语气控制:支持超过50种情感标记(如愤怒、快乐、悲伤等)和语调标记(如急促、低声、尖叫等),用户可通过自然语言指令灵活调整语音表达。
- 强大的多语言支持:支持多达13种语言,包括英语、中文、日语、法语、德语等,展现出强大的多语言能力。
- 高效的语音克隆:支持零样本和少样本语音克隆,仅需10到30秒的音频样本即可生成高保真的克隆声音。
- 灵活的部署选项:提供两种版本,40亿参数的完整版S1和5亿参数的S1-mini,后者为开源模型,适合研究和教育用途。
- 实时应用支持:超低延迟(低于100毫秒),适合实时应用,如在线游戏和直播内容。
优缺点
优点:
- 高度自然的声音:生成的语音几乎与人类配音无异,适用于专业场景。
- 丰富的情感和语气控制:支持超过50种情感和语调标记,满足多样化需求。
- 强大的多语言支持:支持13种语言,适用于跨文化内容创作。
- 高效的语音克隆:仅需10到30秒的音频样本即可生成高保真的克隆声音。
- 灵活的部署选项:提供两种版本,满足不同用户需求。
缺点:
- 硬件要求较高:40亿参数的完整版S1对硬件资源需求较大,可能限制在资源受限环境下的部署。
- 开源版本功能受限:S1-mini虽然开源,但功能可能不如完整版强大。
如何使用
- 在线体验:访问Fish Audio官网,注册即送每日100次免费额度,轻松尝鲜。
- 本地部署:S1-mini的代码和权重已在GitHub上公开,技术宅们可以尽情探索、本地部署。
- 云API调用:通过云API调用,支持批量处理(20秒/条),按量计费,适合更专业的商业应用。
框架技术原理
- 双自回归(Dual-AR)架构:结合快速和慢速Transformer模块,优化语音生成的稳定性和效率。快速模块负责快速生成初步语音特征,慢速模块则对这些特征进行精细调整,确保语音的自然度和流畅性。
- 分组有限标量矢量量化(GFSQ)技术:提升代码本处理能力,在保证高保真语音输出的同时,降低计算成本,提高模型的运行效率。
- 强化学习与人类反馈(RLHF):通过在线RLHF技术,模型能够更精准地捕捉语音的音色和语调,生成的情感表达更加自然。
创新点
- 双自回归架构:结合快速和慢速Transformer模块,优化语音生成的稳定性和效率。
- 分组有限标量矢量量化技术:提升代码本处理能力,降低计算成本。
- 强化学习与人类反馈技术:显著增强语音的情感表达能力,使生成的情感表达更加自然。
评估标准
- TTS-Arena排行榜:在TTS-Arena的最新评测中,OpenAudio S1以“Anonymous Sparkle”之名荣登榜首,击败众多开源和专有模型。
- Seed TTS评估:英语单词错误率(WER)低至0.008,字符错误率(CER)仅为0.004,远超传统模型。
应用领域
- 内容创作:为视频、播客和有声书提供专业级的配音,显著提高制作效率。
- 虚拟助手:创建个性化的语音导航或客服系统,支持多种语言的交互,提升用户体验。
- 游戏与娱乐:为游戏角色生成真实的对话和旁白,增强玩家的沉浸感。
- 教育与培训:用于生成多语言学习内容,帮助学生更好地理解和学习不同语言的发音和语调。
- 客服与支持:适用于客服机器人,提供快速、准确的语音回答,提升客户服务的效率和质量。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
