MirrorMe : 阿里通义推出的音频驱动肖像动画框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
MirrorMe是阿里巴巴通义实验室推出的音频驱动肖像动画框架,旨在通过单张参考图像和音频输入(如对话、歌唱、Rap等),生成具有丰富表情和头部动作的动态肖像视频。该框架突破了传统方法对3D模型或面部标记的依赖,直接通过音频特征驱动视频生成,支持多语言、多风格内容创作,适用于虚拟角色开发、动画制作、教育和娱乐等领域。
功能特点
- 音频驱动视频生成
- 输入单张图像和任意音频(如说话、唱歌、方言、外语),即可生成与音频节奏同步的动态肖像视频。
- 支持生成长达1分30秒的视频,角色表情(如微笑、眨眼)和头部动作(如摇头、点头)自然流畅。
- 多语言与风格支持
- 覆盖普通话、粤语、英语、日语、韩语等语言,适配不同文化场景。
- 支持历史画作、3D模型、卡通形象等多样化肖像风格,赋予静态图像动态生命力。
- 角色身份一致性
- 通过特征提取网络(ReferenceNet)保持生成视频中角色的外观一致性,避免身份混淆。
- 时间维度控制
- 根据输入音频长度生成任意时长视频,支持无缝拼接多段内容,形成连贯叙事。
优缺点
优点:
- 技术突破性:无需复杂3D建模,直接通过音频生成视频,降低创作门槛。
- 自然度与表现力:表情和动作与音频情感高度匹配,生成效果逼真(如让高启强用罗翔声音讲法考)。
- 多场景适配:支持内容创作、虚拟主播、教育互动、广告营销等多领域应用。
缺点:
- 生成稳定性:偶发口型对不准、翻白眼等失误,需进一步优化控制机制。
- 身体部位生成:未显式约束身体部位时,可能意外生成手部等无关动作。
- 计算成本:依赖扩散模型,生成速度较慢,实时性受限。
如何使用
- 输入准备
- 提供一张参考图像(如人物照片、历史画像)和一段音频(如对话录音、歌曲)。
- 模型推理
- 通过预训练的音频编码器提取音频特征(如语调、节奏)。
- ReferenceNet从参考图像中提取特征,确保角色身份一致性。
- 结合面部区域掩模和多帧噪声,生成与音频同步的面部动画。
- 输出结果
- 生成包含丰富表情和头部动作的视频,支持导出为常见格式(如MP4)。
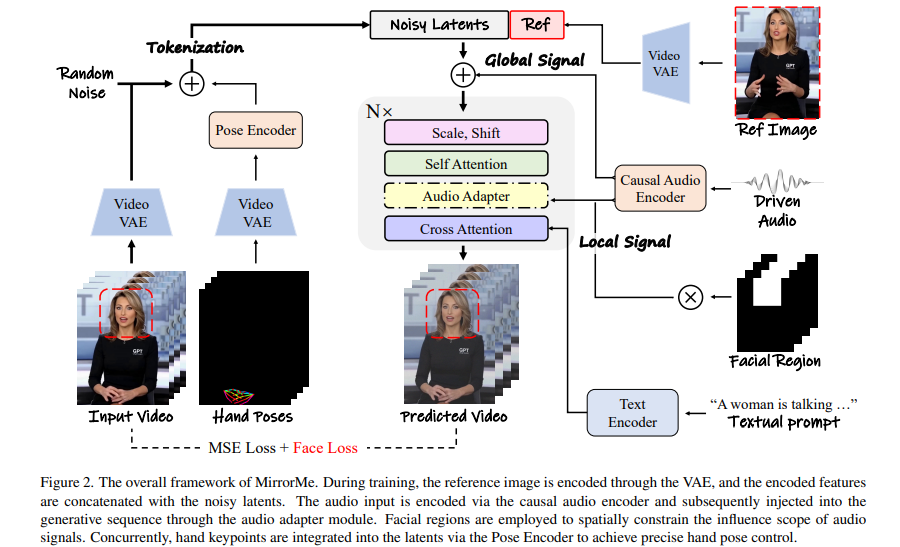
框架技术原理
- 双阶段生成流程
- 帧编码阶段:ReferenceNet从参考图像和运动帧中提取特征,构建角色身份基础。
- 扩散处理阶段:音频编码器处理音频嵌入,结合面部区域掩模和多帧噪声,通过主干网络(UNet结构)去噪生成视频帧。
- 注意力机制交叉执行
- 参考注意力(Reference-Attention):保持角色外观一致性。
- 音频注意力(Audio-Attention):调节角色动作与音频节奏匹配。
- 时间模块优化
- 通过自注意力机制捕捉视频帧间的时间关系,确保动作连贯性(如说话时的唇部同步)。
创新点
- 直接音频到视频合成
- 摒弃传统3D建模或面部标记,通过扩散模型实现端到端生成,简化流程并降低成本。
- 动态情感表达
- 感知音频中的情感变化(如兴奋、悲伤),细化面部表情(如眉毛扬起、嘴角下撇)。
- 长视频生成能力
- 通过运动帧预提取和多分辨率特征融合,减少长视频生成中的误差累积。
评估标准
- 身份一致性
- 衡量生成视频中角色外观与参考图像的相似度(如面部特征保留率)。
- 音频-唇形同步
- 使用SyncNet等工具评估口型与音频的匹配度(如错误率低于5%)。
- 表情-情感对齐
- 通过用户研究或自动化指标(如表情自然度评分)评估情感表达准确性。
- 整体质量
- 综合视频清晰度、动作流畅性、艺术表现力等维度进行主观评价。
应用领域
- 内容创作
- 将静态肖像转化为动态视频,丰富短视频、动漫、游戏等创作形式。
- 虚拟角色开发
- 为虚拟主播、数字人提供表情和动作驱动能力,提升互动真实感。
- 教育与娱乐
- 生成动态教材(如历史人物演讲)或角色驱动的故事叙述,增强用户体验。
- 广告与营销
- 结合品牌形象与声音,制作生动广告视频(如虚拟代言人唱歌推广产品)。
项目地址
- arXiv技术论文:https://arxiv.org/pdf/2506.22065v1
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
