HumanOmniV2 : 阿里通义开源的多模态推理模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
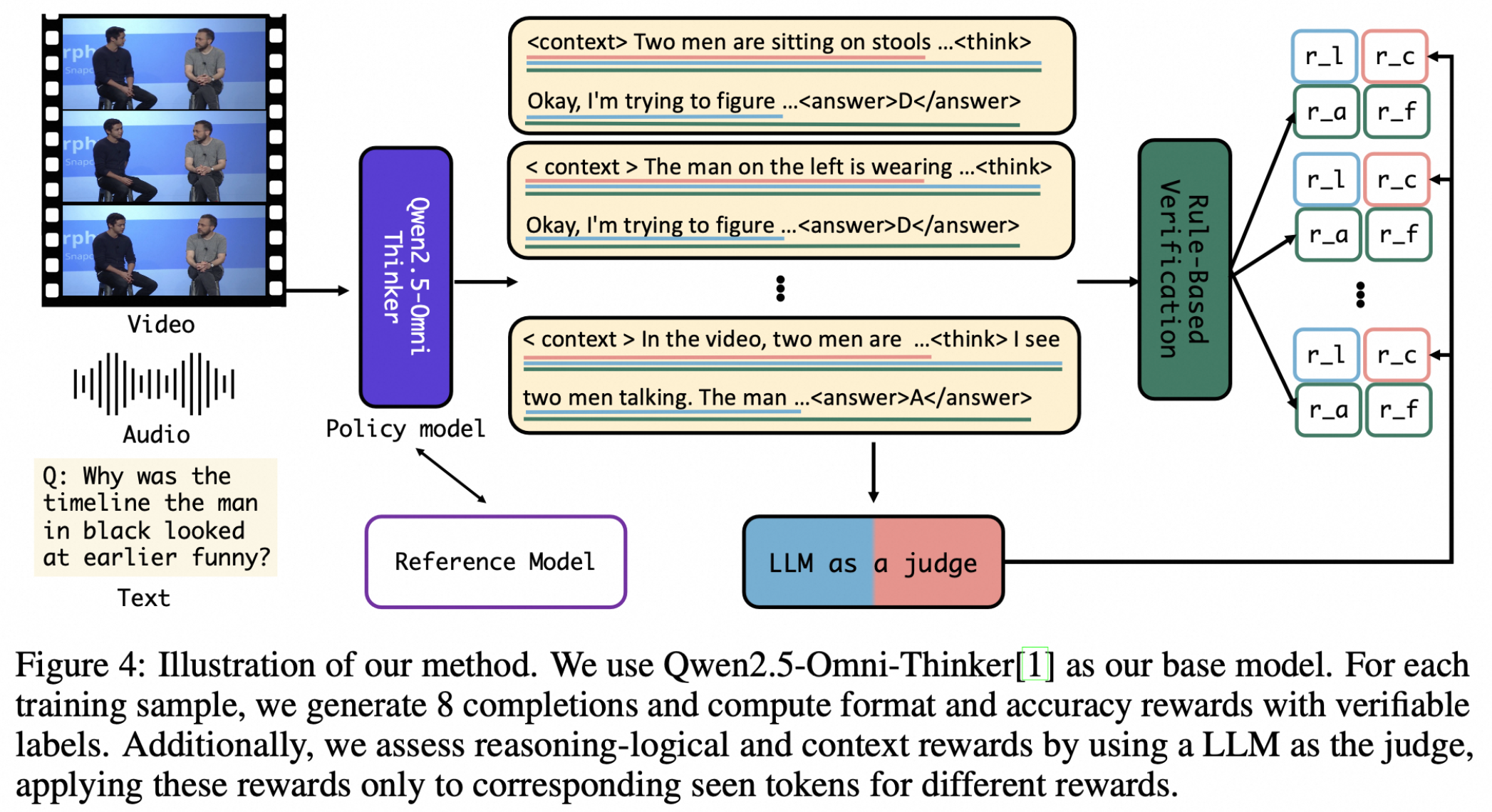
HumanOmniV2是阿里巴巴通义实验室于2025年7月开源的多模态推理模型,旨在解决传统AI模型在全局上下文理解不足和推理路径简单的问题。该模型通过强制上下文总结机制、大模型驱动的多维度奖励体系及基于GRPO的优化训练方法,实现了对文本、图像、视频、音频等多模态信息的深度融合与推理,能够精准捕捉隐藏信息并理解复杂人类意图,在开源全模态模型中性能领先。
功能特点
- 全局上下文理解:
- 模型在生成答案前会输出上下文概括,系统性分析多模态输入中的视觉、听觉、语音信号,避免“断章取义”。例如,在判断“女人为什么翻白眼”时,模型结合视频中的表情、语气和场景,得出“对敏感话题的俏皮反应”而非“不满”的结论。
- 细粒度推理能力:
- 能捕获多模态输入中的微妙线索,如语气、语速、肢体语言等。在分析电视采访片段时,模型通过“黑裙女子平静回应”“浅蓝色衬衫男子兴奋语气”等细节,推断两人关系。
- 多维度奖励机制:
- 引入上下文奖励、格式奖励、准确性奖励和逻辑奖励,确保输出内容符合结构化要求且推理过程整合多模态信息。
优缺点
优点:
- 性能卓越:在IntentBench基准测试中准确率达69.33%,超越同类开源模型,尤其在社交智能理解、情感识别等任务中表现突出。
- 结构化输出:强制要求模型按“背景理解-深度思考-最终答案”三步骤回应,提升推理透明度和可解释性。
- 开源生态友好:模型权重、训练脚本及评测工具均已开源,支持开发者二次开发。
缺点:
- 响应格式限制:结构化输出可能限制模型在后续思考中纠正上下文信息的能力。
- 参数规模风险:基于7B模型实验,在更大参数规模下的性能一致性需进一步验证。
如何使用
- 模型获取:
- GitHub:访问HumanOmniV2官方仓库下载代码与训练脚本。
- Hugging Face:从Hugging Face模型库获取预训练权重。
- 环境配置:
- 硬件要求:建议使用NVIDIA A100/H100 GPU集群,单卡显存≥80GB。
- 软件依赖:Python 3.10+、PyTorch 2.3+、Transformers 4.40+。
框架技术原理
- 强制上下文总结机制:
- 模型需先生成多模态输入的整体总结(如人物、动作、环境),再进入推理阶段,确保全局理解。
- 改进的GRPO算法:
- 引入词元级损失(Token-level Loss)解决长序列训练中的奖励稀释问题。
- 移除问题级归一化项,避免不同难度样本间的权重偏差。
- 应用动态KL散度机制,在训练初期鼓励探索,后期稳定收敛。
- 全模态推理训练数据集:
- 融合图像、视频、音频等任务的上下文信息,解决大规模人工标注数据缺失的问题。
创新点
- “背景理解-深度思考-最终答案”三阶段响应格式:
- 类似人类推理过程,先全面观察场景再逻辑分析,避免传统模型直接处理查询的“捷径问题”。
- 大模型驱动的多维度奖励机制:
- 通过上下文奖励、逻辑奖励等引导模型生成符合人类认知的推理链,提升复杂意图理解能力。
- IntentBench评测基准:
- 包含633个视频和2689个问题,覆盖社交智能、情感识别等领域,为多模态推理模型提供标准化评估框架。
评估标准
- IntentBench:
- 评估模型理解复杂人类意图和情感的能力,HumanOmniV2准确率达69.33%。
- Daily-Omni/WorldSense:
- 测试模型在日常事件理解和常识推理上的综合能力,HumanOmniV2得分分别为58.47%和47.1%。
应用领域
- 智能客服:
- 分析用户文字描述和上传的图片,提供精准帮助。
- 内容创作:
- 理解用户的多维度需求,生成符合预期的写作、设计或视频制作建议。
- 教育领域:
- 根据学生学习行为和作业表现,制定个性化学习方案。
- 医疗领域:
- 辅助医生分析病例,整合病历、影像和检查结果,提供全面诊断参考。
- 金融领域:
- 分析市场数据、新闻信息和用户行为,为投资决策提供风险评估。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
