MetaStone-S1 : 原石科技推出的反思型生成式大模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
MetaStone-S1是原石科技于2025年7月推出的反思型生成式大模型,首次融合“Long-CoT强化学习”与“过程评分学习”范式,支持自监督推理链筛选与实时优化。模型通过共享主干网络实现策略模型与过程评分模型(SPRM)的协同训练,仅增加53M参数即可完成推理质量评估,无需人工标注。其核心目标是通过低成本推理实现高性能推理,在数学、编程、中文推理等任务中达到或超越OpenAI o3-mini、DeepSeek R1等竞品水平,并开源1.5B、7B、32B三种版本供开发者使用。
功能特点
- 深度推理与长链生成
- 支持超长推理链(Long-CoT)生成,可处理数学证明、编程算法等复杂任务。
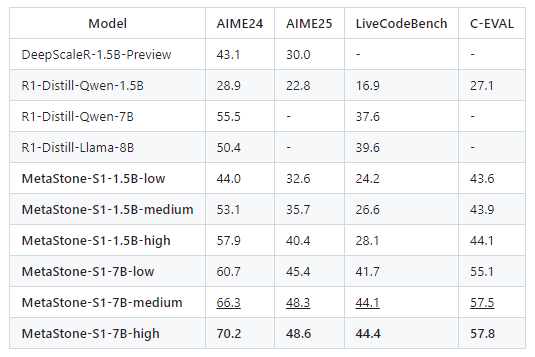
- 在AIME24数学竞赛中,32B版本以56.7%正确率超越DeepSeek R1-671B(79.8%参数量下的79.8%正确率,但MetaStone-S1以32B参数实现类似性能),在LiveCodeBench代码任务中准确率达88%,接近人类开发者水平。
- 自监督推理链优化
- 内置SPRM机制,实时评估推理步骤质量并剔除错误路径,显著提升最终答案准确性。
- 通过动态权重算法(SPR Loss)仅依赖最终答案标签优化过程评分,摆脱对人工标注的依赖。
- 多档位推理模式
- 提供Low(快速响应)、Medium(平衡精度与速度)、High(深度思考)三种模式,适配不同场景需求。
- 在High模式下,模型可生成32条候选推理链并择优输出,实现“生成-评估-择优”闭环。
- 开源与可扩展性
- 全面开源1.5B/7B/32B模型及配套工具,支持开发者在特定领域进一步优化推理能力。
- 支持与HuggingFace、ModelScope等平台集成,降低部署门槛。
优缺点
优点:
- 高性能低成本:32B参数模型在AIME24、LiveCodeBench等任务中性能超越671B参数的DeepSeek R1,推理成本降低85%。
- 自监督学习:无需过程标注数据,通过最终答案标签即可训练SPRM,降低数据采集成本。
- 灵活推理模式:三种档位模式满足从实时交互到深度研究的多样化需求。
缺点:
- 基座模型限制:当前版本基于QwQ-32B基座模型,在High模式下的数学、代码任务中仍落后于OpenAI o3-mini,需等待自研基座模型迭代。
- 中文优化不足:虽在C-EVAL中文推理任务中表现优异,但在多语言支持上仍弱于GPT-4o等模型。
- 硬件门槛较高:32B版本需高端GPU支持,中小企业部署可能面临算力挑战。
如何使用
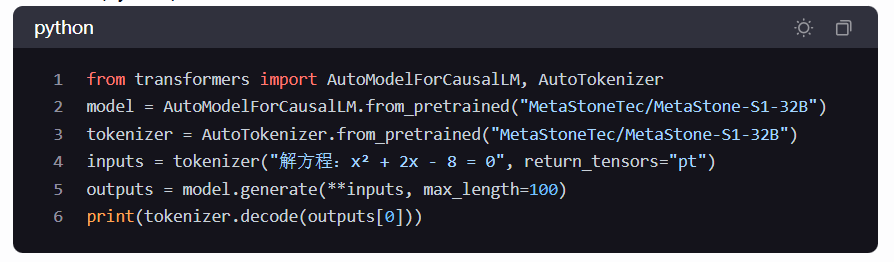
- API调用
- 通过HuggingFace或ModelScope平台调用MetaStone-S1 API,支持文本、代码、数学推理等任务。
- 示例代码(Python):

- 本地部署
- 下载模型权重至本地服务器,通过FlashAttention等优化库加速推理。
- 支持与Cursor等IDE集成,实现代码自动补全与错误调试。
- 定制化开发
- 基于开源代码训练行业专属模型,例如在金融领域优化量化交易策略生成,或在医疗领域辅助诊断推理。
框架技术原理
- 双头共享架构
- 策略模型(Policy Model)与SPRM共享主干网络,在Transformer层上并行部署生成头(Generation Head)和评分头(Scoring Head)。
- 生成头负责推理链生成,评分头基于自监督学习对每个步骤实时评分,二者共享梯度实现协同进化。
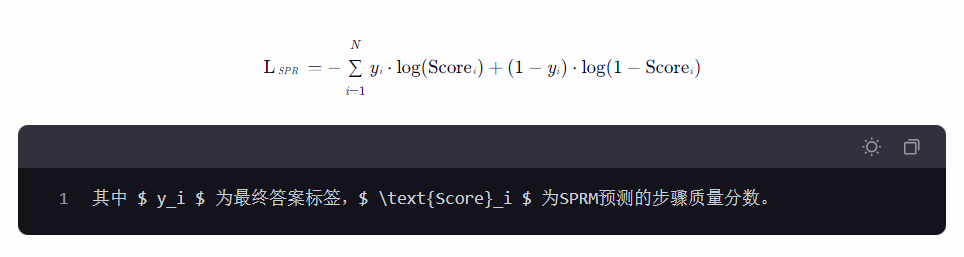
- 自监督过程奖励(SPR Loss)
-
以最终答案的正确性作为弱监督信号,通过噪声过滤机制生成步骤级伪标签,训练SPRM区分优质/低质推理步骤。
-
损失函数公式:
-
-
动态推理择优(Test-Time Scaling)
- 在推理阶段生成多条候选推理链(如High模式生成32条),通过SPRM计算路径总分,选择最优路径继续生成。
- 通过调整候选链数量(Rollout次数)平衡计算成本与推理质量,建立思考长度与模型性能的Scaling Law。
创新点
- 反思型生成范式
- 首次将推理与过程评分统一到单一模型中,减少99%以上独立奖励模型参数,实现高效自监督学习。
- 通过共享主干网络降低计算冗余,使32B参数模型具备与671B模型竞争的推理能力。
- 长链推理可视化
- 揭示模型筛选优质推理路径的“Aha Moment”,将智能涌现过程可视化,为AI可解释性研究提供新范式。
- 通过拟合1.5B~32B参数的推理曲线,量化思考长度与模型性能的关系,指导后续模型优化。
- 低成本高性能平衡
- 在AIME24数学竞赛中,32B模型以每秒0.3美元的推理成本超越DeepSeek R1-671B(每秒2.5美元),成本降低85%。
- 开源策略降低AI应用门槛,推动推理模型在科研、教育等领域的普及。
评估标准
- 学术基准测试
- 数学:AIME24/25竞赛,评估模型解决复杂数学问题的能力。
- 编程:LiveCodeBench测试集,评估代码生成与调试能力。
- 中文推理:C-EVAL测试集,评估模型在中文语境下的逻辑推理能力。
- 实际应用场景
- 科研辅助:药物分子设计、学术论文分析等任务的效率提升。
- 金融科技:量化交易策略回测的收益率与风险控制能力。
- 智能制造:工业设备故障诊断的准确率与维修方案优化。
- 推理效率指标
- 推理成本:每秒处理Token数(Tokens/s)与单位成本(美元/百万Tokens)。
- 思考长度:模型生成单条推理链的平均Token数,反映深度推理能力。
- 模式切换灵活性:Low/Medium/High模式下的性能与成本平衡表现。
应用领域
- 科研与教育
- 辅助数学/物理竞赛题解答,生成可交互的解题路径说明。
- 支持科研论文的公式推导和理论验证,确保学术内容的逻辑严谨性。
- 金融科技
- 生成量化交易策略,实时分析市场情绪与风险。
- 优化投资组合配置,提升资产回报率。
- 智能制造
- 基于多级因果推理,快速定位工业设备故障根源并生成维修方案。
- 优化生产线调度,提升生产效率与资源利用率。
- 法律智能
- 深度分析合同条款的逻辑关系,精准识别潜在法律风险点。
- 提供符合法律逻辑的修订建议,辅助律师起草法律文件。
项目地址
- GitHub仓库:https://github.com/MetaStone-AI/MetaStone-S1
- HuggingFace模型库:https://huggingface.co/MetaStoneTec
- arXiv技术论文:https://arxiv.org/abs/2507.01951
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
