Voxtral : Mistral AI开源的语音模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Voxtral是Mistral AI于2025年7月发布的全球首个开源语音理解模型系列,旨在打破大型企业封闭系统在音频领域的垄断,为开发者提供高性能、低成本的语音智能解决方案。该模型基于Mistral Small 3.1基座模型构建,支持语音转录、语义理解、问答交互及API调用等功能,覆盖从本地边缘设备到云端生产环境的全场景需求。其核心目标是通过开源协议(Apache 2.0)降低语音AI技术门槛,推动行业从“封闭商用API”向“开源可商用+云端即服务”双轨模式转型。

功能特点
- 超长上下文处理:支持32k token上下文窗口,可转录长达30分钟的音频,理解长达40分钟的语义内容。
- 多语言原生支持:覆盖英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语、意大利语等主流语言,具备自动语言识别能力。
- 端到端语音智能:集成语音转录、问答交互、结构化摘要生成功能,无需串联独立ASR和语言模型。例如,用户可直接针对音频内容提问或生成会议纪要。
- 语音触发系统指令:支持基于口语意图直接调用后端API、工作流或函数,实现语音到系统命令的无缝转换。
- 多版本灵活部署:
- Voxtral Small(24B参数):面向生产级部署,性能对标ElevenLabs Scribe、GPT-4o-mini,成本不足后者50%。
- Voxtral Mini(3B参数):适用于本地/边缘设备部署,支持资源受限场景。
- Voxtral Mini Transcribe:超轻量转录专用模型,性能超越OpenAI Whisper,成本减半。
优缺点
- 优点:
- 开源生态友好:Apache 2.0协议允许自由商用、修改和分发,促进社区协作与创新。
- 成本效益显著:在转录任务中,Voxtral Mini Transcribe成本不足Whisper的50%;Voxtral Small性能接近ElevenLabs Scribe,成本同样减半。
- 长音频处理突破:支持30分钟转录和40分钟理解,远超传统语音模型的片段式处理能力。
- 缺点:
- 实时性待优化:目前未支持实时流式处理,在语音交互场景中可能存在延迟。
- 情感识别缺失:与顶级商业模型(如Scribe)相比,缺乏语音情感分析、说话人情绪识别等高级功能。
如何使用
- 在线体验:通过Mistral官方聊天机器人Le Chat(chat.mistral.ai)直接测试语音输入功能。
- 本地部署:
- 从Hugging Face下载模型权重:
- 使用Hugging Face Transformers库加载模型并推理:from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor model = AutoModelForSpeechSeq2Seq.from_pretrained(“mistralai/Voxtral-Small-24B-2507”) processor = AutoProcessor.from_pretrained(“mistralai/Voxtral-Small-24B-2507″) inputs = processor(audio_path=”input.wav”, return_tensors=”pt”) outputs = model.generate(**inputs) print(processor.decode(outputs[0]))
- API调用:通过Mistral开发者平台(console.mistral.ai)获取API密钥,集成费用从每分钟0.001美元起。
框架技术原理
- 基座模型继承:基于Mistral Small 3.1的语言理解能力,通过多任务训练融合语音编码器与文本解码器。
- 分层式注意力机制:
- 帧级注意力:捕捉音频帧间的局部特征。
- 上下文注意力:建模长音频的全局依赖关系,支持超长上下文处理。
- 多模态对齐:通过对比学习对齐语音与文本的语义空间,实现跨模态问答交互。
- 高效推理优化:采用CUDA内核并行计算与模型量化技术,降低延迟并支持边缘设备部署。
创新点
- 开源语音智能商业化:首次在实际生产环境中实现“开源可商用+云端即服务”双轨模式,降低企业技术门槛。
- 语音到行动的闭环:集成语音理解、问答、摘要生成与API调用功能,实现从语音输入到系统操作的完整链路。
- 多语言统一架构:通过共享参数实现跨语言语音理解,避免传统模型对多语言支持的冗余设计。
评估标准
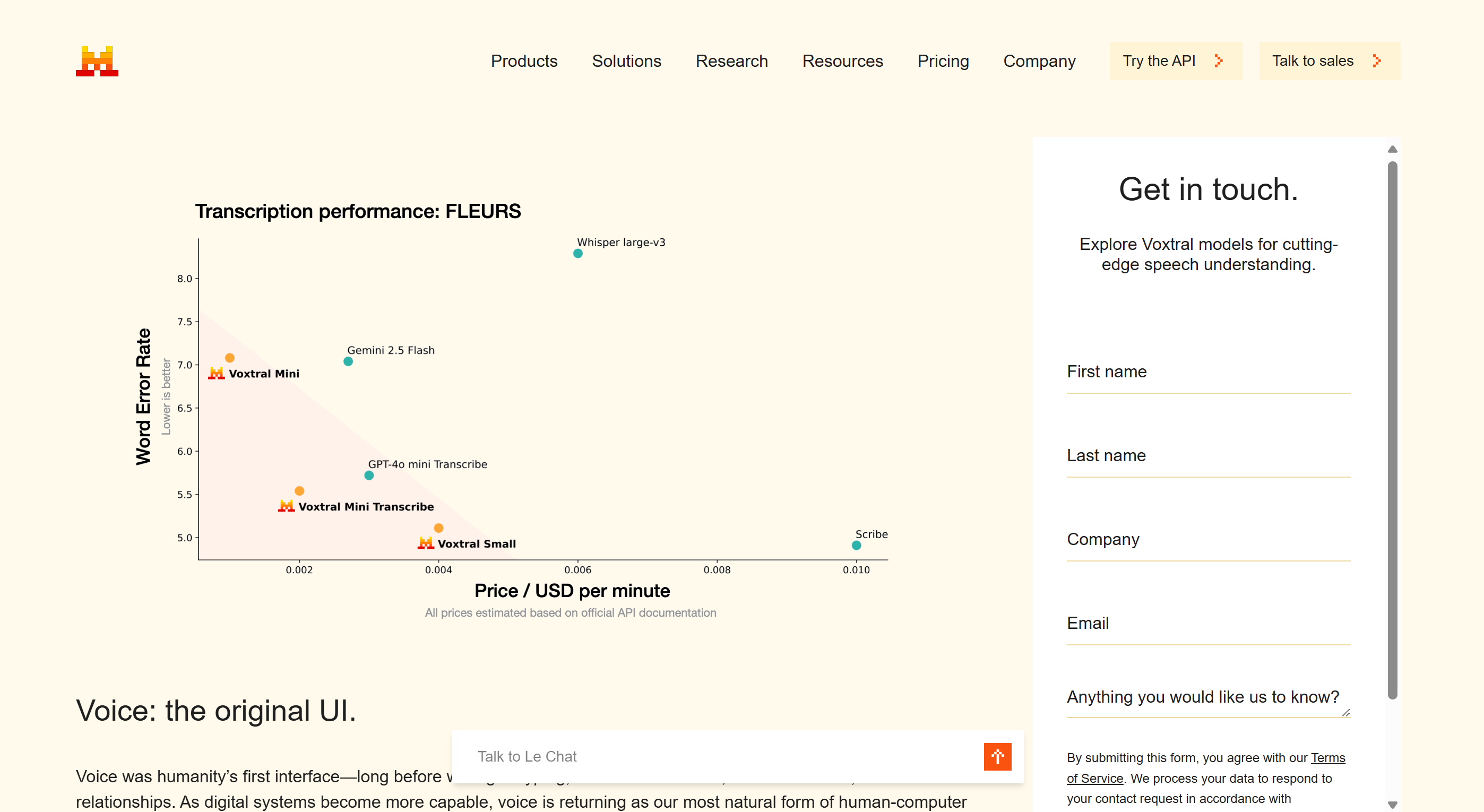
- 转录准确率:采用跨语言宏平均词错率(WER)评估,数值越低越好。Voxtral在英语短音频、长音频及Mozilla Common Voice基准上均超越Whisper large-v3。
- 语义理解能力:通过FLEURS-Translation基准测试语音翻译性能,Voxtral Small在法语、德语等语言中排名第一。
- 成本效率:比较单位算力下解决的问题数量,Voxtral Small在保持与ElevenLabs Scribe相当性能的同时,成本减半。
- 多语言支持:在FLEURS多语言基准测试中,Voxtral Small在所有任务上超越Whisper large-v3。
应用领域
- 会议记录与速记:自动转录并生成结构化会议纪要,支持多角色说话人分割。
- 教育辅助:实时转录讲座内容,生成关键词摘要与问答对,辅助学生复习。
- 媒体制作:为视频添加多语言字幕,或通过语音指令编辑音频片段。
- 企业客服:通过语音理解分析用户意图,自动触发工单系统或知识库查询。
项目地址
- 官网介绍:mistral.ai/news/voxtral
- 模型下载:Hugging Face Voxtral系列
- API接入:Mistral开发者平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
