9月1日·DeepSeek公开V3/R1训练细节,积极回应AI生成内容标识新规
9月1日·周一 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
DeepSeek公开V3/R1训练细节,积极回应AI生成内容标识新规
DeepSeek在其官微发布公告,积极响应网信办《人工智能生成合成内容标识办法》的生效,明确所有AI生成内容将标注“AI生成”,并严禁用户恶意篡改标识。同时,DeepSeek公开了V3/R1模型的训练细节,涵盖预训练和优化训练(微调)阶段,强调其6850亿参数规模的模型通过高质量、大规模、多样化的数据训练而成。在数据治理上,DeepSeek采用过滤器剔除不良内容,并通过算法与人工审核降低统计性偏见。此外,DeepSeek还开源了模型权重、参数及推理工具代码,采用MIT协议供用户免费使用。来源:微信公众号【新智元】
NeurIPS 2025投稿量爆仓,400篇已录用论文被拒
NeurIPS 2025因投稿量激增而引发学术界的广泛关注。本届会议首次设立分会场,分别在圣迭戈和墨西哥城举办,但即便如此,仍无法容纳近3万篇投稿。由于场地限制,NeurIPS组委会通知“高级领域主席”(SAC)拒收已被录用的约400篇论文,即便这些论文已通过初审。这一决定引发了学术社区的广泛不满,许多研究者认为应通过拆分会议或扩容来解决,而非随意拒收优秀论文。此前ICLR也曾采取类似做法,而AAAI 2026也面临投稿量激增的问题,收到近2.9万份投稿,其中近2万篇来自中国。。来源:微信公众号【新智元】

首个具身智能大规模强化学习框架RLinf开源
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构开源了RLinf,这是首个面向具身智能的“渲训推一体化”大规模强化学习框架。RLinf通过创新的系统设计,支持具身智能领域的大脑、小脑及大小脑联合模型,解决了具身智能训练中算力和显存竞争的挑战。该框架采用基于Worker的统一编程接口,提出混合式执行模式,相比其他框架提速超120%。此外,RLinf还集成了两套后端,分别针对已收敛和未收敛的模型架构,支持多种训练需求。在性能上,RLinf在具身智能任务中表现出色,相关模型已开源,欢迎下载测试。来源:微信公众号【机器之心】
GRPO后训练范式及其改进
深入探讨大语言模型后训练中的强化学习范式GRPO及其改进。GRPO由DeepSeek提出,旨在优化PPO算法,去除价值函数,通过策略模型的多次输出采样来确定Advantage,降低了训练成本。然而,GRPO仍存在稳定性问题,尤其是在中小规模训练中。为此,今年出现了多种改进方法,如字节和清华AIR的DAPO,通过Clip-Higher机制、动态采样等优化训练过程;Qwen团队的GSPO将重要性采样从token级提升至序列级,显著提高了训练稳定性;微软的GFPO则通过数据过滤优化多个响应属性。这些改进推动了大模型后训练技术的发展。来源:微信公众号【机器之心】

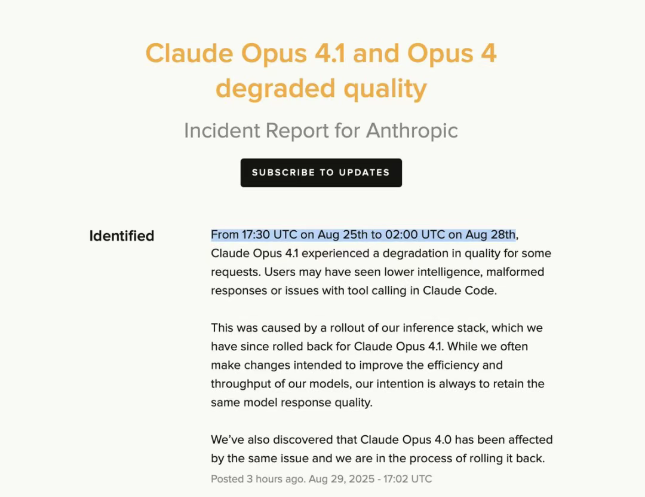
Claude Opus 4.1翻车,Anthropic承认并回滚更新
Claude Opus 4.1出现性能退化的问题。用户反馈该模型在白天处理某些请求时表现迟钝,尤其是在上午10点到11点期间,推理性能大幅下降。Anthropic官方承认这一问题,指出是推理堆栈出了问题,原本为了提升模型效率而采用的1.58位量化导致了精度和稳定性下降。此外,用户还反映模型存在使用限制不明确和API密钥暴露等问题。Anthropic迅速回滚了Claude Opus 4.1的版本,并表示正在处理受影响的Claude Opus 4.0版本。这一事件引发了网友对明星公司模型质量的关注。来源:微信公众号【量子位】
相关文章
