MiniCPM 4.1:面壁智能推出的混合思考模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
面壁智能于2025年9月8日正式发布MiniCPM 4.1基座模型,作为端侧大模型领域的里程碑式升级,该模型在MiniCPM 4.0基础上新增8B参数原生稀疏架构,成为行业首个支持“深思考”模式的端侧混合模型。其核心设计目标是通过架构创新与系统优化,在智能手机、智能汽车、智能家居等算力受限设备上实现媲美云端大模型的推理能力,同时满足隐私保护与实时性需求。
功能特点
-
-
- 稀疏注意力架构:采用InfLLM v2稀疏注意力机制,每个词元仅计算与5%以下词元的相关性,在128K长文本场景下,缓存存储空间需求降低至传统模型的25%,推理速度提升7倍。例如,处理10万字合同摘要时,传统模型需1分钟以上,而MiniCPM 4.1仅需数秒。
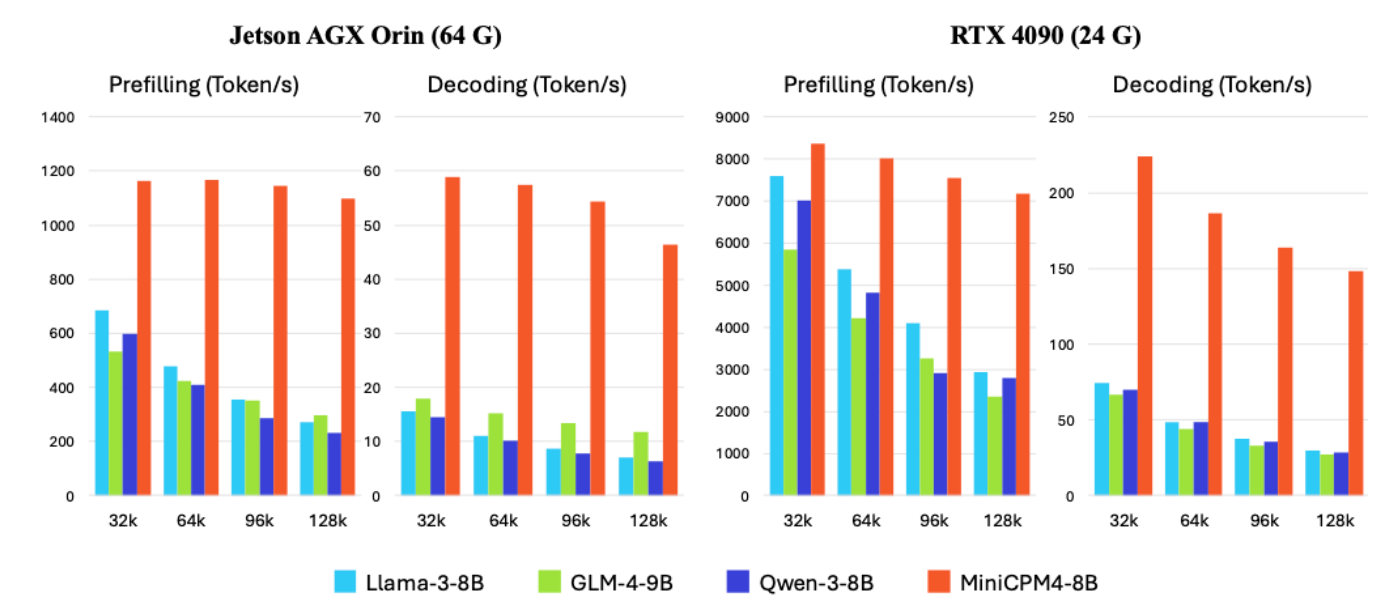
- 双频换挡机制:模型可自动识别任务类型:长文本推理时启用稀疏模式降低计算复杂度,短文本生成时切换稠密模式保证输出精度。在Jetson AGX Orin设备上,32K文本解码速度达1400 Token/s,较Llama-3-8B提升133%。
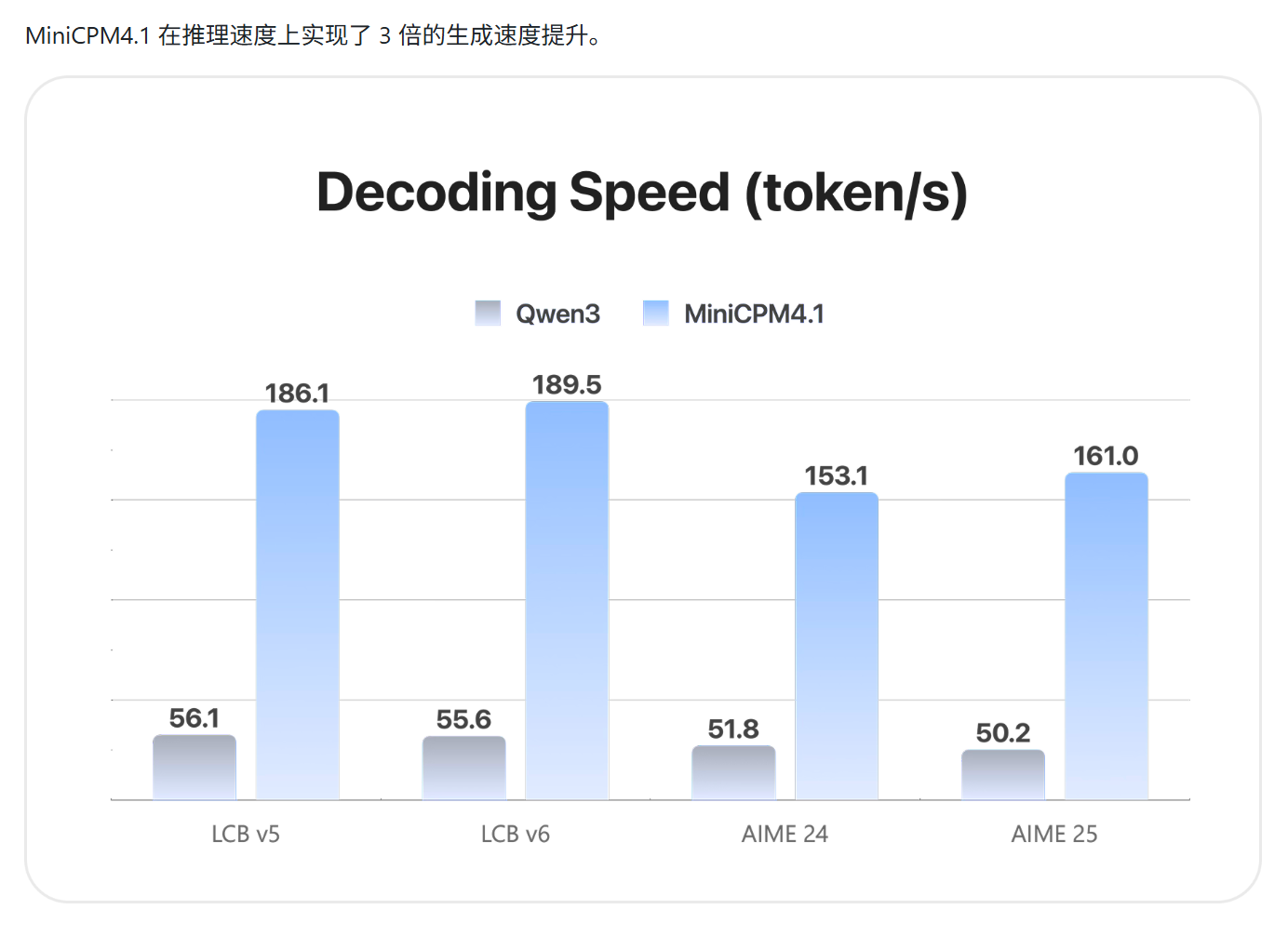
- 端侧友好部署:支持GPTQ、AutoAWQ等量化格式,可在高通骁龙8 Gen4、联发科天玑9400等芯片上直接运行,无需依赖云端算力。通过CPM.cu推理框架集成稀疏计算、投机采样等技术,模型推理效率较前代提升3倍。
- 多模态扩展能力:基于MiniCPM-V的视觉-语言融合架构,可处理图像描述、文档分析等跨模态任务。在OCRBench评测中,文本识别准确率达98.7%,数学公式解析错误率低于2%。
-
优缺点
优势:
-
-
- 算力效率突破:8B参数模型在端侧实现128K上下文处理能力,性能超越多数13B云端模型。
- 隐私安全保障:所有计算在本地完成,避免用户数据上传云端,符合GDPR等隐私法规要求。
- 实时响应能力:在车载场景中,模型可实时处理传感器数据并生成驾驶建议,延迟低于100ms。
-
局限:
-
-
- 复杂任务精度受限:在超长文本(如百万字级)的因果推理任务中,稀疏架构可能导致部分上下文信息丢失。
- 硬件适配成本:虽支持跨平台部署,但针对特定芯片的优化需额外开发工作,例如瑞芯微RK3588需手动调整内存分配策略。
-
如何使用
-
- 开发环境搭建:
- 从HuggingFace模型库下载预训练权重(openbmb/MiniCPM4.1-8B)。
- 安装CPM.cu推理框架:
pip install cpm-cu,支持CUDA 11.8及以上版本。
- 端侧部署流程:
- 使用ArkInfer工具将模型转换为目标芯片格式(如.rknn for 瑞芯微)。
- 通过ONNX Runtime或TensorRT优化推理流程,在联发科Dimensity 9400上实现1500 Token/s的解码速度。
- 开发环境搭建:
框架技术原理
- InfLLM v2稀疏注意力:
- 将键值缓存(KV Cache)划分为固定大小的语义块,通过动态相关性评分选择Top-K块进行计算。
- 引入“语义核”概念,用块内词元的平均表示替代逐词计算,将注意力复杂度从O(n²)降至O(n)。
- CPM.cu推理引擎:
- 集成频率排序推测采样(FR-Spec),通过词汇表剪枝减少75%的候选词数量。
- 采用前缀感知量化(P-GPTQ),对初始令牌使用8位量化,后续令牌使用4位量化,平衡精度与内存占用。
- 双频换挡算法:
- 通过任务特征分析器(Task Profiler)实时监测输入长度、复杂度等指标。
- 当检测到长文本(>4K Token)或复杂推理任务时,自动激活稀疏计算路径;短文本(<1K Token)则使用稠密模式。
创新点
- 原生稀疏架构设计:区别于传统模型通过剪枝实现的稀疏性,MiniCPM 4.1在预训练阶段即引入可训练的稀疏注意力,使模型天然具备高效计算能力。
- 数据-算法协同优化:
- UltraClean数据过滤系统:利用预训练模型作为“质检员”,从36万亿原始数据中筛选出8万亿高价值语料,训练效率提升4倍。
- ModelTunnel v2超参搜索:通过小模型(如0.5B参数)实验预测大模型性能,将训练参数搜索成本降低90%。
- 端侧工具调用能力:通过Model Context Protocol(MCP)协议,模型可动态调用本地API(如数据库查询、代码编译器),在学术文献检索任务中工具调用准确率达92.3%。
评估标准
- 综合性能基准:
- MMLU(大规模多任务语言理解):8B模型得分68.7,超越Llama3.2-13B(65.2)和Gemma3-13B(62.1)。
- CMMLU(中文专项):得分82.4,较Qwen3-8B提升6.2个百分点。
- 长文本处理能力:
- LongBench-128K:在法律、医疗等领域的长文档摘要任务中,ROUGE-L得分达58.3,较传统模型提升41%。
- 端侧效率指标:
- 推理速度:在骁龙8 Gen4上,128K文本预填充速度达9000 Token/s。
- 内存占用:8B模型量化后仅需4.2GB显存,可完整加载至iPhone 16 Pro(8GB RAM)。
应用领域
- 智能手机:本地化文档处理、实时语音翻译、个性化AI助手(如根据用户聊天记录生成日程建议)。
- 智能汽车:车载语音交互、驾驶行为分析、实时路况推理(如结合摄像头数据预测行人轨迹)。
- 智能家居:设备故障诊断、能源管理优化、多模态家庭助手(如通过语音+图像识别指导家电维修)。
- 工业边缘计算:生产线质量检测、设备预测性维护、工人操作规范监控。
项目地址
- GitHub仓库:https://github.com/openbmb/minicpm
- 模型下载:HuggingFace Model Hub
- 技术文档:仓库内
docs/MiniCPM4.1_Technical_Report.pdf提供完整架构设计与实验数据。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
