rStar2-Agent : 微软开源的数学推理模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
rStar2-Agent 是微软研究院于2025年9月发布的开源数学推理模型,拥有140亿参数。该模型通过智能体强化学习(Agentic Reinforcement Learning)框架,在数学推理任务上实现了与6710亿参数的DeepSeek-R1相当的性能,甚至在部分基准测试中超越了后者。其核心设计理念是让模型从“更长时间地思考”转向“更聪明地思考”,即通过工具交互和动态反馈优化推理路径,而非依赖冗长的思维链(Chain-of-Thought)。
功能特点
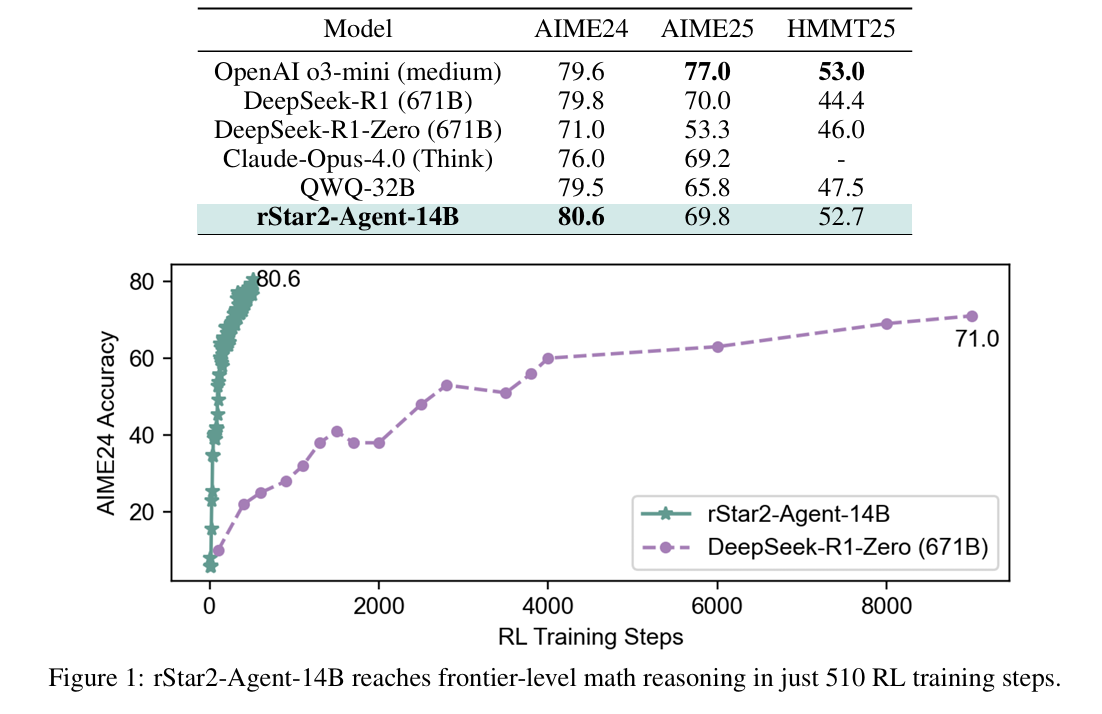
- 高效推理能力:在AIME24和AIME25数据集上分别实现80.6%和69.8%的平均通过率,超越DeepSeek-R1(79.8%和69.0%)。
- 工具辅助验证:支持Python代码工具调用,可动态验证中间推理步骤,减少错误累积。
- 多轮交互机制:通过“思考-行动-反馈”循环,模型能根据环境反馈调整推理策略,提升问题解决效率。
- 低资源训练:仅需64块AMD MI300X GPU,训练一周即可完成,计算成本显著低于传统大模型。
优缺点
优势:
- 参数效率高:14B模型实现671B模型的性能,证明小模型通过算法优化可突破规模限制。
- 推理更简洁:平均响应长度比DeepSeek-R1短数千个token,减少冗余计算。
- 泛化能力强:在科学推理(GPQA-Diamond)、工具使用(BFCL v3)等任务上表现优异,超越DeepSeek-V3。
局限:
- 训练步数敏感:超过510步训练后性能急剧下降,表明模型潜力受参数规模限制。
- 复杂任务边界:在超长文本(如百万字级)的因果推理中,稀疏架构可能导致上下文信息丢失。
如何使用
- 环境配置:
- 安装Python 3.10+、PyTorch 2.0+及依赖库(如
transformers、accelerate)。 - 从HuggingFace下载预训练权重:
openbmb/rStar2-Agent-14B。
- 安装Python 3.10+、PyTorch 2.0+及依赖库(如
- 工具调用扩展:
- 通过结构化JSON格式封装Python代码调用。
框架技术原理
- GRPO-RoC算法:
- 正确重采样(Resample-on-Correct):对成功轨迹按工具错误率和格式规范度筛选,保留高质量样本;对失败轨迹随机降采样,保留多样化错误模式。
- 非对称采样策略:解决传统RL中“仅结果奖励”导致的噪声问题,提升推理稳定性。
- 高吞吐量基础设施:
- 支持45,000次并发工具调用,平均延迟0.3秒,通过动态负载均衡和安全隔离设计,确保大规模训练效率。
- 多阶段训练流程:
- 非推理SFT:仅训练指令遵循、JSON格式化和基础工具使用能力。
- 三阶段RL训练:逐步增加任务难度(8K→12K→17.3K tokens),限制最大输出长度以强制模型学习高效推理。
创新点
- 智能体强化学习框架:
- 首次将工具交互与动态反馈机制引入数学推理,使模型能自主探索、验证和修正中间步骤。
- GRPO-RoC算法:
- 通过非对称采样策略解决环境噪声问题,提升推理轨迹质量。
- 分阶段训练策略:
- 从“工具使用”到“高效推理”的渐进式训练,避免传统SFT阶段的过拟合风险。
评估标准
- 数学推理性能:
- AIME24/25:平均通过率(pass@1)作为核心指标。
- 推理效率:
- 平均响应长度(tokens)衡量模型简洁性。
- 泛化能力:
- GPQA-Diamond(科学推理)、BFCL v3(工具使用)、IFEval(通用对齐)等基准测试。
应用领域
- 教育:
- 自动解题、个性化学习辅导。
- 科研:
- 数学定理证明、符号计算辅助。
- 金融:
- 量化交易策略验证、风险模型推导。
- 工业:
- 代码调试、复杂系统建模。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
