SpikingBrain-1.0 : 中国科学院推出的类脑脉冲大模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
SpikingBrain-1.0(瞬悉1.0)是中国科学院自动化研究所李国齐、徐波团队与沐曦MetaX合作研发的首款类脑脉冲大模型,于2025年9月正式发布。该模型基于团队原创的“内生复杂性”理论,在国产GPU算力集群上完成全流程训练与推理,首次提出大规模类脑线性基础模型架构,并实现了超长序列处理效率的数量级提升。其核心目标是通过模仿人脑神经元工作机制,突破传统Transformer架构的功耗与性能瓶颈,为新一代人工智能提供非Transformer架构的技术路线。
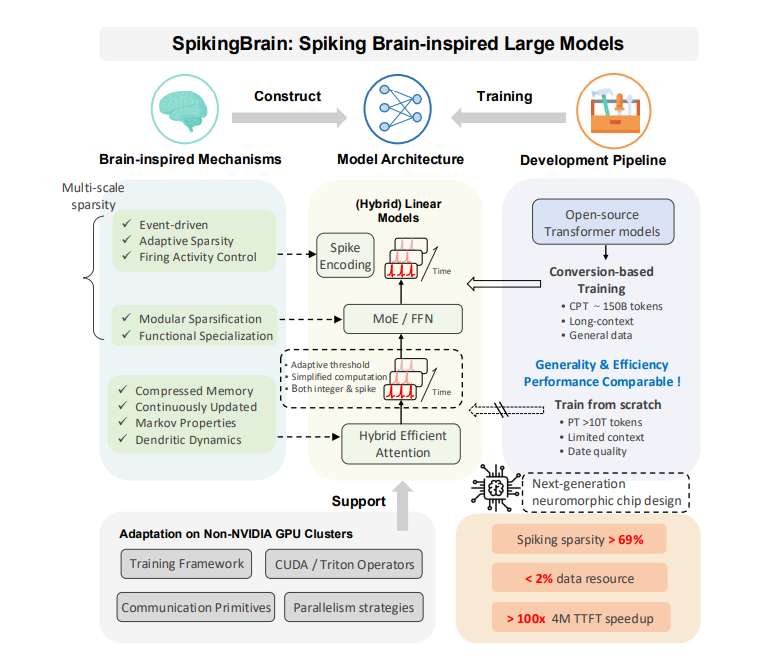
功能特点
- 超长序列高效处理:
- 在400万Token长度下,推理速度比传统Transformer模型快超100倍,100万Token长度下加速26.5倍。
- 支持一次推理中完整阅读千万字级文档(如法律条文、医学病例库),避免语义丢失。
- 极低数据量训练:
- 仅需约主流模型2%的预训练数据量,即可在多任务语言理解(MMLU)、中文理解(CMMLU、Ceval)、常识推理(ARC、HS)等任务中达到媲美开源Transformer模型的性能。
- 低功耗与高能效:
- 通过脉冲神经元事件驱动特性,结合动态阈值脉冲化稀疏机制,模型稀疏度超69.15%,长序脉冲占比仅1.85%,显著降低能耗。
- 国产自主可控生态:
- 适配国产沐曦曦云C550 GPU集群,开发了高效训练推理框架、Triton算子库及模型并行策略,支持全流程国产化部署。
优缺点
优点:
- 技术突破性:全球首款在超长序列处理中实现数量级效率提升的类脑大模型,首次构建国产非Transformer架构生态。
- 资源友好性:训练数据需求低,推理功耗仅为传统模型的2.3%,适合边缘设备部署。
- 开源生态:开源70亿参数模型(SpikingBrain-1.0-7B)并开放760亿参数模型测试接口,加速技术迭代。
缺点:
- 硬件依赖性:当前优化主要针对国产GPU,其他硬件平台适配需额外开发。
- 生态成熟度:作为新型架构,社区工具链和插件生态尚不及Transformer模型丰富。
如何使用
- 本地部署:
- 从GitHub下载开源模型(SpikingBrain-7B),使用支持脉冲神经网络的框架(如Diffusers)加载。
- 云端调用:
- 通过测试网址(体验入口)直接交互,支持超长文本输入与实时推理。
- 行业应用:
- 法律/医学文档分析:输入整部法典或病例库,模型可精准定位关键条款或诊断依据。
- 高能物理实验:实时分析每秒10⁸量级粒子数据流,识别罕见信号。
框架技术原理
- 内生复杂性架构:
- 借鉴大脑神经元内部复杂动力学,将脉冲神经元内生动力学与线性注意力机制关联,揭示现有线性注意力是树突计算的简化形式。
- 动态阈值脉冲化:
- 通过两阶段动态阈值策略,将稠密连续值矩阵乘法转换为事件驱动的脉冲化算子,减少90%以上计算量。
- 混合线性复杂度设计:
- 70亿参数模型(SpikingBrain-7B)采用线性复杂度,760亿参数模型(SpikingBrain-76B)结合混合线性复杂度,平衡性能与资源消耗。
创新点
- 理论创新:
- 首次建立脉冲神经元与线性注意力模型的理论联系,提出“基于内生复杂性”的模型构建范式。
- 工程突破:
- 解决脉冲驱动下大规模类脑模型性能退化问题,实现超长序列训练与推理的线性复杂度。
- 生态构建:
- 完成从机制原理、工程实现到规模化验证的闭环,推动国产自主可控类脑生态发展。
评估标准
| 维度 | 测试方法 | SpikingBrain-1.0表现 | 对比模型(如Llama-3.1-8B) |
|---|---|---|---|
| 推理速度 | 400万Token生成首个Token时间(TTFT) | 加速超100倍 | 传统架构受序列长度平方级增长限制 |
| 数据效率 | MMLU/CMMLU任务准确率 | 2%数据量达到90%性能 | 需全量数据训练 |
| 能耗 | 浮点运算能耗比(FLOPs/Watt) | 功耗降低97.7% | 依赖高功耗GPU集群 |
应用领域
- 科学研究:
- 高能物理实验(如粒子信号追踪)、DNA序列分析、分子动力学轨迹模拟。
- 专业服务:
- 法律合同审查、医学病例分析、金融长文本风控。
- 创意产业:
- 超长剧本生成、多章节小说连贯性写作、历史档案数字化。
项目地址
- GitHub开源模型:https://github.com/BICLab/SpikingBrain-7B
- 测试网址:https://controller-fold-injuries-thick.trycloudflare.com
- 技术报告:中文版 | 英文版
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
