LLaSO : 逻辑智能开源的语音模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
LLaSO(Large Language and Speech Omni-Framework)是由北京深度逻辑智能科技有限公司推出的全球首个完全开源、端到端的语音语言模型(LSLM)研究框架。该框架旨在解决LSLM领域长期存在的碎片化架构、不透明训练数据和缺失评估标准等问题,通过提供大规模数据、统一基准和参考实现,为语音语言模型研究建立透明、可复现的技术基础设施。
功能特点
- 完全开源:LLaSO的所有组件,包括数据集、基准和模型,均完全开源,支持社区贡献和协同创新。
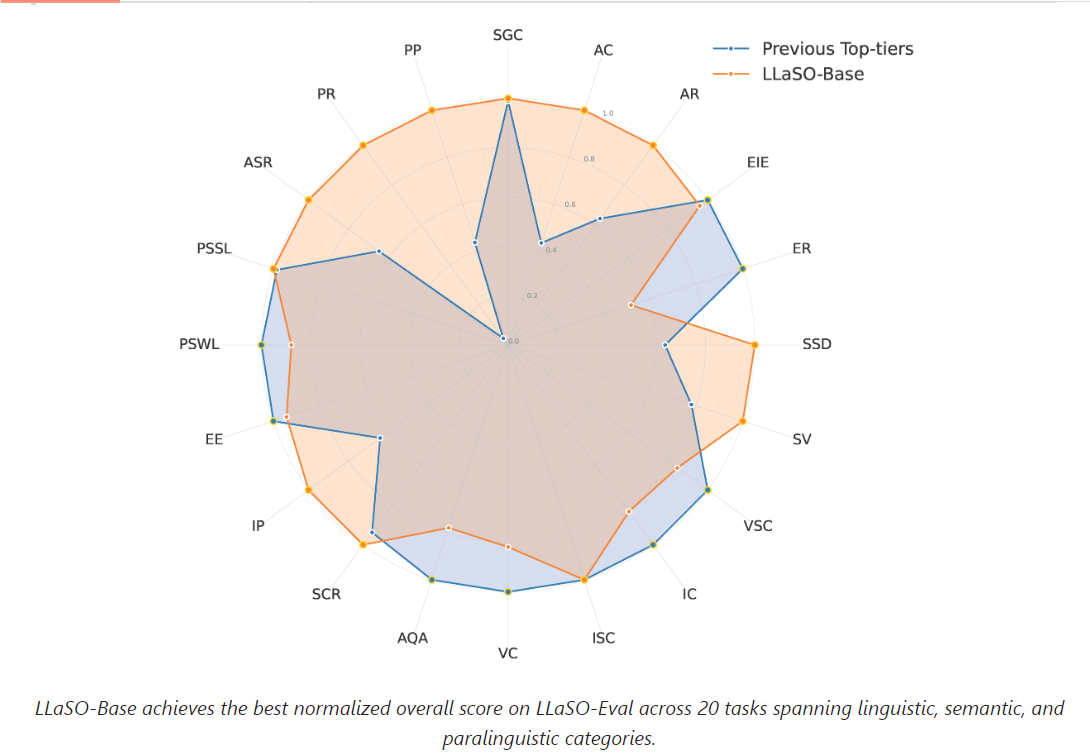
- 多任务支持:涵盖语言学、语义学和副语言学三大类共20项任务,支持文本指令+音频输入、音频指令+文本输入和纯音频交互等多种交互模态。
- 标准化评估:提供统一的评估协议和自动化评估工具,覆盖所有任务,确保评估的公平性和可复现性。
- 高性能模型:基于LLaSO数据训练的38亿参数参考模型LLaSO-Base,在ASR任务上展现了压倒性优势,WER和CER分别低至0.08和0.03。
优缺点
优点:
- 降低研究门槛:开源策略使研究者能够专注于算法创新而非数据收集。
- 统一技术标准:为LSLM领域建立了统一的技术标准,推动从“各自为战”向“协同创新”转变。
- 丰富的任务覆盖:支持多种任务和交互模态,提升模型的泛化能力和指令遵循能力。
缺点:
- 模型规模有限:LLaSO-Base模型规模为38亿参数,相比其他大型模型规模较小。
- 多语言支持不足:目前主要支持中文和英文,多语言支持仍有待提升。
- 实时性能待优化:在实时性能和长音频处理方面仍有局限性。
如何使用
- 访问项目地址:用户可以通过GitHub(EIT-NLP/LLaSO)或Hugging Face(papers/2508.15418)获取LLaSO框架的代码和模型。
- 数据准备:使用LLaSO-Align和LLaSO-Instruct数据集进行模型训练和微调。
- 模型训练:基于LLaSO数据训练参考模型LLaSO-Base,或根据需求调整模型架构和参数。
- 评估与测试:使用LLaSO-Eval评估基准对模型进行标准化评估,确保评估的公平性和可复现性。
框架技术原理
LLaSO框架采用经典的三阶段架构:
- 语音编码器:使用Whisper-large-v3将语音信号转换为数字表示。
- 模态投影器:通过多层感知器(MLP)实现语音和文本特征空间的映射。
- 语言模型backbone:采用Llama-3.2-3B-Instruct作为语言理解引擎,提供语言理解和生成能力。
训练过程分为两个阶段:
- 对齐阶段:使用LLaSO-Align数据集建立语音和文本的对应关系。
- 指令微调阶段:使用LLaSO-Instruct数据集学习复杂指令遵循能力。
创新点
- 完全开源:LLaSO是首个完全开源的LSLM研究框架,提供完整的数据、基准和模型。
- 多任务指令微调:涵盖20项任务,支持多种交互模态,显著提升模型的泛化能力。
- 标准化评估基准:提供统一的评估协议和自动化评估工具,确保评估的公平性和可复现性。
- 高性能参考模型:基于LLaSO数据训练的LLaSO-Base模型在ASR任务上展现了卓越性能。
评估标准
LLaSO-Eval评估基准包含15,044个测试样本,覆盖所有20项任务。评估指标包括:
- WER/CER:用于ASR等转录任务,数值越低表示准确率越高。
- Accuracy:用于分类任务,数值越高性能越好。
- MAE:用于数值预测任务,数值越低预测越精准。
- GPT-4o Score:针对开放式生成任务,使用GPT-4o对模型输出的相关性和准确性进行打分。
- Abstention Rate:衡量模型在面对不熟悉或困难任务时的“回避”倾向,比率越低说明模型的指令遵循能力和鲁棒性越强。
应用领域
- 智能助理:通过语音交互实现任务执行和信息查询。
- 会议纪要:自动识别和转录会议内容,提取关键信息。
- 情感分析:分析语音中的情感信息,提升人机交互体验。
- 说话人识别:识别说话人的性别、年龄、口音等特征。
- 语音翻译:实现语音到语音的实时翻译,支持跨语言交流。
项目地址
- GitHub:EIT-NLP/LLaSO
- Hugging Face:papers/2508.15418
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
