ReSum : 阿里通义开源的WebAgent推理范式
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
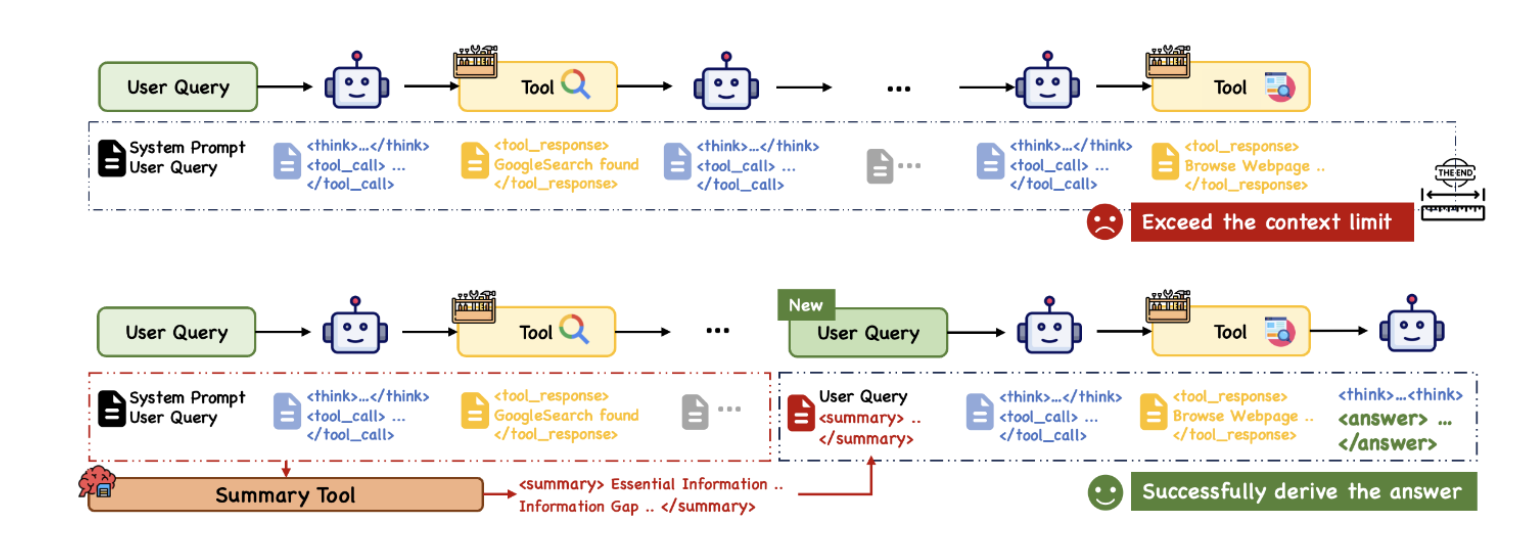
WebAgent是阿里巴巴通义实验室于2025年开源的自主搜索AI智能体框架,旨在模拟人类在网络环境中的感知、决策和行动循环,实现端到端的自主信息检索与多步推理。其核心突破在于通过WebDancer(端到端智能体训练框架)和WebWalker(Web遍历基准测试)两大模块,构建了从数据合成到强化学习的完整训练体系,使智能体能够像人类一样主动访问、筛选、整合信息,并生成结构化报告。例如,用户可指令WebAgent“分析某领域最新研究进展”,其会自动检索学术数据库、筛选相关文献,并整合不同观点生成全面报告。
功能特点
- 自主信息检索:覆盖学术数据库、新闻网站等多源信息,无需人工干预。
- 多步推理与信息整合:通过长推理与短推理结合,构建复杂推理链(如“收集竞品定价→分析减配策略→生成时间轴报告”)。
- 复杂任务处理:支持10+步骤的跨平台操作,适应高不确定性任务(如BrowseComp基准测试中的多跳推理)。
- 环境适应性强:通过监督微调(SFT)和强化学习(RL)优化模型鲁棒性,排除外部反馈干扰。
- 多语言支持:覆盖119种语言,满足全球化需求。
优缺点
优点:
- 技术先进性:在WebWalker基准测试中,WebAgent-7B模型综合准确率达42.33%,超越GPT-4o的37.50%。
- 开源生态完善:提供数据集(如WebWalkerQA)、模型权重和部署脚本,支持快速验证与二次开发。
- 任务覆盖广:从简单查询(如天气)到复杂推理(如学术研究)均可胜任。
缺点:
- 硬件要求高:部署WebDancer-32B需2块NVIDIA A100(80GB显存)及128GB内存。
- 复杂任务稳定性不足:在极端不确定性任务(如BrowseComp-en)中,开源模型仍落后于闭源系统(如OpenAI的DeepResearch)。
如何使用
- 环境配置:
- 硬件:≥2块A100 GPU(80GB显存)、128GB内存、200GB存储空间。
- 软件:Python 3.12、Conda、sglang推理后端。
- 部署流程:
- 克隆仓库:
git clone https://github.com/Alibaba-NLP/WebAgent.git - 安装依赖:
pip install -r requirements.txt - 下载模型:从Hugging Face获取WebDancer-32B权重。
- 启动服务:运行
bash scripts/deploy_model.sh /path/to/models。
- 克隆仓库:
- 交互示例:
- 配置API密钥(如Google Search、Jina API)。
- 启动Gradio界面:
bash scripts/run_demo.sh,在浏览器中输入任务指令(如“分析AI智能体发展趋势”)。
框架技术原理
WebAgent的核心是WebDancer训练框架,其流程分为四阶段:
- 数据构建:
- 通过CRAWLQA与E2HQA模拟人类浏览行为,生成复杂问答对(QA)。
- 短推理:利用大模型生成简洁推理路径(轨迹连贯性达85.7分)。
- 长推理:通过迭代提示构建深层决策链,合成数据量提升3倍。
- 监督微调(SFT):
- 解构轨迹为“思考-行动-观察”三要素,计算损失函数时屏蔽外部反馈,强制模型专注决策逻辑。
- 强化学习(RL):
- 采用DAPO算法,通过动态采样机制高效复用低利用率QA对,解决数据稀疏问题。
- 推理引擎:
- 基于ReAct框架,支持Thought-Action-Observation循环迭代,动态分配计算资源(如“快思考”与“慢思考”平衡)。
创新点
- 混合推理模式:
- 通过“思维预算机制”动态分配计算资源,实现快速响应简单查询与深度推理复杂任务的平衡。
- 高不确定性任务训练:
- 构建SailorFog-QA数据集,模拟真实网页环境中的非线性知识图谱,提升模型对模糊信息的处理能力。
- 形式化数据合成:
- 提出基于集合论的IS任务形式化模型,通过知识投影(KP)的R-并集、交集和递归操作,精准控制推理复杂度与逻辑结构。
评估标准
- 基准测试:
- WebWalker:评估智能体在长上下文导航与信息搜寻任务中的表现。
- BrowseComp:衡量模型处理高不确定性、多跳推理任务的能力(如WebSailor-72B在BrowseComp-zh中达30.1%)。
- 人工评估:
- 任务成功率:WebAgent在Web任务中成功率达73.2%。
- 自然度:通过用户反馈评估生成报告的逻辑连贯性与可读性。
应用领域
- 学术研究:快速检索和分析文献,生成研究报告(如“AI智能体技术演进”)。
- 商业决策:整合市场动态与行业趋势,辅助企业战略制定(如竞品分析)。
- 新闻媒体:协助记者收集素材,提供多角度解读(如突发事件背景分析)。
- 教育领域:支持个性化学习,生成课程设计建议(如“Python编程教学方案”)。
- 个人生活:解答日常疑问,提供旅游规划、健康咨询等服务(如“北京三日游攻略”)。
项目地址
- GitHub仓库:DeepResearch/WebAgent/WebResummer at main · Alibaba-NLP/DeepResearch · GitHub
- 模型权重:Hugging Face(搜索“WebDancer-32B”或“WebSailor-72B”)
- 数据集:WebWalkerQA(覆盖会议、教育、游戏等领域,含680个查询与1373个网页)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
