VoxCPM : 面壁智能联合清华推出的语音生成模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
VoxCPM 是由面壁智能与清华大学深圳国际研究生院人机语音交互实验室(THUHCSI)联合研发的0.5B参数语音生成基座模型,于2025年9月18日正式发布。作为一款端到端扩散自回归语音生成模型,VoxCPM 突破传统离散分词方法,直接从文本生成连续语音表征,支持流式实时输出,在自然度、音色相似度及韵律表现力上达到SOTA(行业顶尖)水平。目前,该模型已在 GitHub、Hugging Face 等平台开源,支持中文、方言及多语言场景。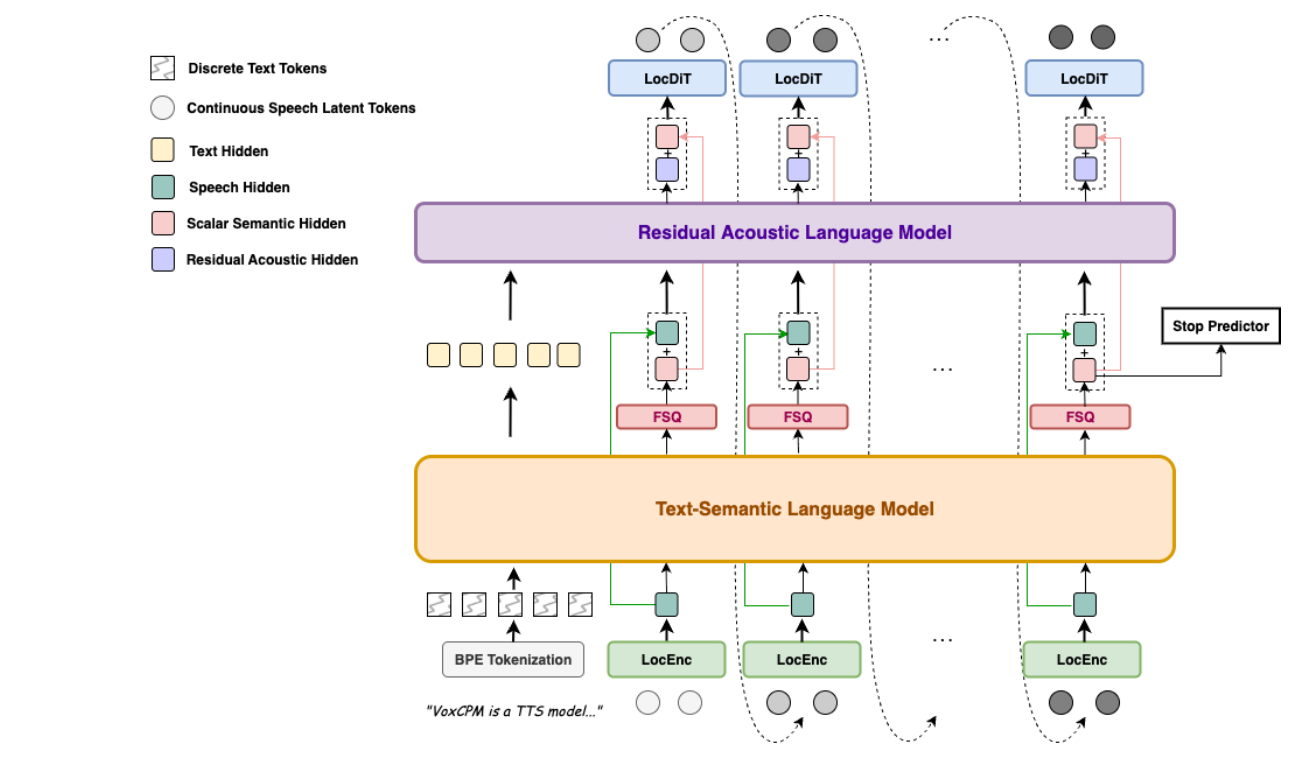
功能特点
- 上下文感知语音生成:
- 基于对文本内容的深度理解,自动匹配声音风格、腔调与韵律,生成高度拟人化的语音。例如,可模拟天气预报员的字正腔圆、英雄将领的慷慨激昂,或方言主播的特色表达。
- 零样本语音克隆:
- 仅需少量参考音频,即可精准复刻音色,并捕捉口音、情感语调、节奏停顿等细节,实现“以声传情”。
- 公式与符号音频合成:
- 支持数学公式、化学符号等特殊内容的语音输出,满足教育、科研等场景需求。
- 音素标记替换:
- 允许用户自定义读音纠正,解决多音字、生僻字发音问题。
- 高效流式合成:
- 在单张 NVIDIA RTX 4090 显卡上,实时因子(RTF)低至 0.17,支持实时交互应用。
优缺点
优点:
- 自然度媲美真人:在情绪、口音、停顿等方面表现优异,生成语音几乎无法区分于真人。
- 低资源需求:0.5B 参数实现高效推理,降低部署成本。
- 开源生态:代码与模型完全开源,支持社区协作与二次开发。
缺点:
- 方言支持有限:虽支持方言主播模拟,但覆盖语种仍需扩展。
- 实时性依赖硬件:流式合成需高性能 GPU 支持,移动端部署存在挑战。
如何使用
- 在线体验:
- 访问 Hugging Face Demo 页面(https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo),输入文本并选择语音风格,实时生成音频。
- 本地部署:
- 从 GitHub(https://github.com/OpenBMB/VoxCPM)下载模型,通过 Docker 快速启动容器,无需手动配置环境。
- API 调用:
- 集成 Hugging Face Inference API,通过网页端或命令行工具直接调用模型服务。
框架技术原理
- 端到端扩散自回归架构:
- 摒弃传统离散分词方法,直接在连续空间中建模语音,通过扩散过程生成高质量音频片段。
- 分层语言建模(HLM):
- 结合全局语义与局部声学特征,实现隐式语义-声学解耦,增强语音表达力。
- FSQ 约束优化:
- 引入频率-频谱-量化(FSQ)约束,提升生成语音的稳定性与清晰度。
创新点
- 无分词器(Tokenizer-Free)设计:
- 首次在语音生成领域实现完全连续空间建模,避免离散化带来的信息损失。
- 上下文感知与零样本克隆融合:
- 将文本理解与语音克隆能力结合,支持动态风格调整与个性化表达。
- 轻量化与高性能平衡:
- 0.5B 参数实现 SOTA 性能,为移动端和边缘设备部署提供可能。
评估标准
- 自然度(MOS 评分):
- 通过人工主观评价(Mean Opinion Score)衡量语音真实感,VoxCPM 得分接近真人水平。
- 词错误率(WER):
- 在 Seed-TTS-EVAL 评测中,正常样本词错率低于 1%,困难样本表现优异。
- 音色相似度(SIM):
- Zero-shot 音色克隆任务中,相似度评分达行业顶尖水平。
应用领域
- 有声内容创作:
- 为播客、有声书、视频配音提供高质量语音合成服务。
- 虚拟数字人:
- 驱动虚拟主播、智能客服等场景,实现自然交互。
- 教育辅助:
- 生成公式朗读、方言教学等音频内容,提升学习体验。
- 无障碍技术:
- 为视障用户提供文本转语音服务,支持个性化语音定制。
项目地址
- GitHub 仓库:https://github.com/OpenBMB/VoxCPM
- Hugging Face 模型:https://huggingface.co/openbmb/VoxCPM-0.5B
- 在线 Demo:https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
