Logics-Parsing : 阿里开源的端到端文档解析模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
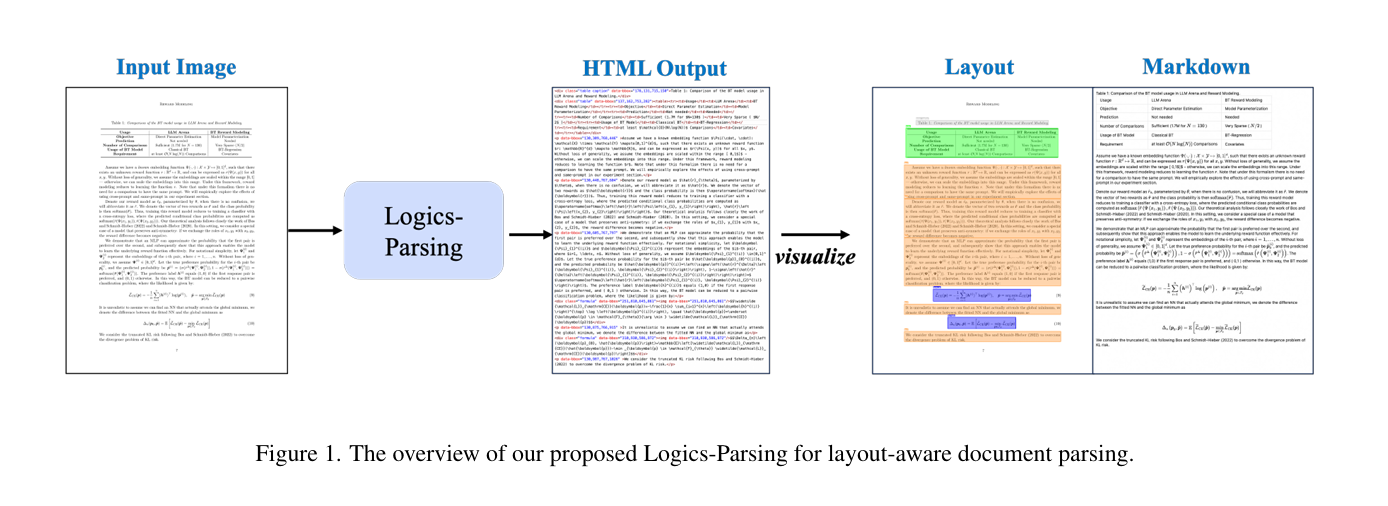
Logics-Parsing是阿里巴巴开源的端到端文档解析模型,基于视觉语言模型(VLM)架构,旨在解决传统文档解析中“多工具拼接”导致的精度损失和兼容性问题。该模型可直接从文档图片生成结构化的HTML数据,保留文档的逻辑结构(如段落、表格、公式、化学结构等),并支持复杂排版场景(如多栏报纸、图文混排、跨页表格等)。2025年9月,阿里在云栖大会上正式发布该模型并同步开源,成为文档AI领域的重要突破。
功能特点
- 端到端统一模型:输入文档图片,直接输出带逻辑结构的HTML代码,无需OCR、布局检测等多阶段流水线处理。
- 复杂内容识别:支持数学公式、化学结构式(如SMILES格式)、手写内容、表格边界及行列结构识别。
- 精细化输出:输出结果包含类别标签(段落、表格、公式等)、位置坐标、OCR文本及噪声过滤(自动去除页眉、页脚、水印)。
- 高精度与高效性:在自建评测集(覆盖论文、报纸、海报等9大类文档)中表现SOTA(业界最佳),支持单GPU高效推理。
优缺点
- 优点:
- 简化流程,降低复杂度,避免多工具拼接的误差累积。
- 对复杂排版和科学内容的解析能力强,适用于学术、企业等场景。
- 开源模型和工具链(如ModelScope、HuggingFace),社区支持完善。
- 缺点:
- 对极低质量扫描件或艺术字体的识别可能受限。
- 当前版本主要支持中英文,多语言(如阿拉伯语、日韩文)需后续升级。
框架技术原理
- 基础架构:基于Qwen2.5-VL架构,通过监督微调(SFT)和强化学习(RL)训练。
- 监督微调:融入化学式、手写汉字等多样化数据,提升模型对复杂元素的识别能力。
- 强化学习:设计布局感知奖励机制,优化阅读顺序推断和复杂布局分析。例如,模型通过“试错”学习多栏文档的正确阅读路径,奖励符合逻辑的顺序,惩罚错误顺序。
- 输出表示:生成Qwen-HTML格式,保留元素类别、边界框坐标及OCR文本,自动过滤无关内容。
创新点
- 端到端解析:首次实现从文档图片到结构化HTML的全流程统一模型,替代传统流水线方法。
- 强化学习驱动:通过RL解决LVLM(大型视觉语言模型)的“阅读障碍”,使模型学会规划最优阅读路径。
- 科学内容支持:精准识别数学公式、化学结构式等复杂元素,支持STEM学科文档解析。
评估标准
- 结构准确性:HTML输出的逻辑结构与原始文档的一致性。
- 元素识别率:公式、表格、化学结构等复杂内容的识别精度。
- 阅读顺序合理性:多栏、跨页文档的阅读路径是否符合人类习惯。
- 性能效率:单GPU推理速度及资源消耗。
应用领域
- 学术研究:解析论文、专利、实验记录,支持知识检索和训练数据构建。
- 企业文档处理:合同、发票、财报等结构化提取,降低人工处理成本。
- 教育行业:扫描试卷、课堂笔记的自动化批改和内容分析。
- 内容管理:新闻网站、出版社的文档归档和语义化存储。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
