Logics-Parsing : 阿里开源的端到端文档解析模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
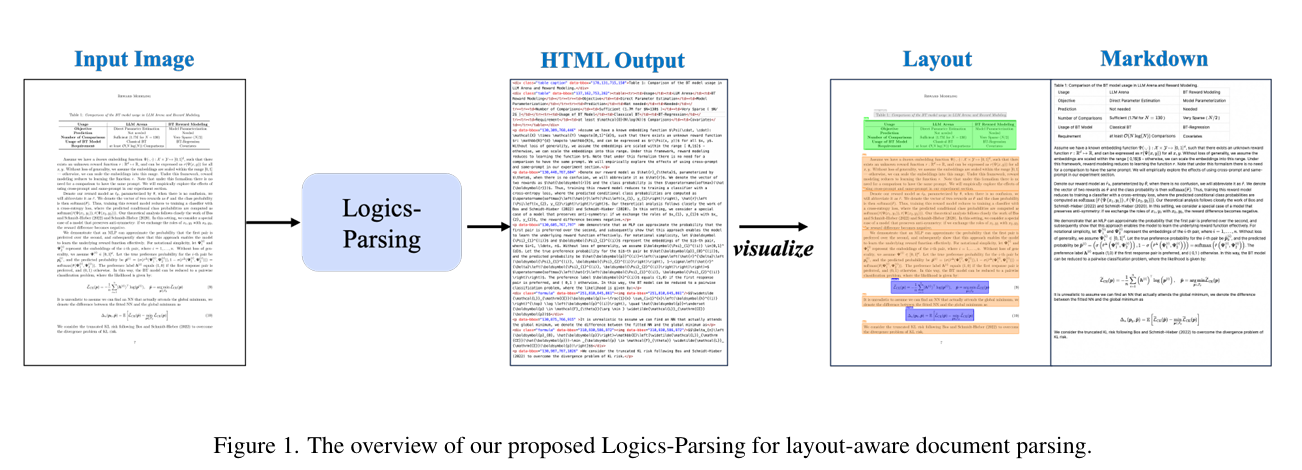
Logics-Parsing是阿里巴巴开源的端到端文档解析模型,基于Qwen2.5-VL-7B视觉语言模型(VLM)构建,通过强化学习优化布局分析与阅读顺序推断。该模型可直接将PDF图像或扫描文档转换为结构化HTML输出,支持复杂排版、多栏布局、数学公式、化学结构及手写内容的精准解析,适用于学术论文、企业报表、合同文档等场景,显著降低结构化数据处理成本。
功能特点
- 端到端处理:输入文档图像,直接输出带逻辑结构的HTML,无需OCR、布局检测等多阶段流水线。
- 复杂内容识别:支持数学公式(LaTeX格式)、化学结构(SMILES格式)、表格、手写中文字符等。
- 结构化输出:每个内容块标注类别(段落、表格、公式等)、边界框坐标及OCR文本,自动过滤页眉、页脚等噪声。
- 阅读顺序优化:通过强化学习确保多栏文档、嵌套表格的逻辑顺序正确性。
- 多语言支持:兼容中英文混排、阿拉伯语、日韩文等(未来升级方向)。
优缺点
- 优点:
- 统一模型架构降低复杂度,避免多工具拼接的精度损失。
- 在STEM领域(如化学结构、数学公式)解析准确率显著优于同类工具。
- 开源且支持商业化(Apache 2.0协议),提供在线Demo快速体验。
- 缺点:
- 当前对极端长宽比文档(如长截图)支持不足,需后续优化。
- 手写内容识别错误率仍高于印刷体,复杂连笔字可能需后处理。
如何使用
- 在线体验:访问ModelScope魔搭社区,选择样例文档(如英文论文、化学试卷)点击“Convert”,实时查看原始文档与解析结果的对比。
- 本地部署:
- 搭建环境:创建Conda虚拟环境并安装依赖(
conda create -n logics-parsing python=3.10)。 - 下载模型:通过HuggingFace或ModelScope获取预训练权重。
- 运行推理:使用命令行工具输入图像路径,生成HTML结果(如
python3 inference.py --image_path input.png --output_path output.html)。
- 搭建环境:创建Conda虚拟环境并安装依赖(
框架技术原理
- 基础模型:基于Qwen2.5-VL-7B,继承其跨模态(视觉+语言)理解能力。
- 两阶段训练:
- 监督微调(SFT):使用30万张高质量文档图像训练,覆盖文本、公式、表格、化学结构及手写汉字。
- 强化学习(RL):通过布局感知奖励机制优化阅读顺序,解决多栏排版、嵌套结构等难题。
- 输出设计:生成带语义标签的Qwen HTML,保留文档逻辑结构,支持可视化校验。
创新点
- 统一模型架构:打破传统“OCR+布局检测+公式解析”的流水线模式,实现单模型端到端处理。
- 强化学习优化:引入布局感知奖励,显著提升复杂文档的解析准确性。
- STEM领域专业支持:精准识别化学结构(SMILES格式)和数学公式(LaTeX格式),填补专业文档解析空白。
- 开源生态:提供代码、预训练模型及基准测试集,推动社区协作优化。
评估标准
- LogicsParsingBench基准测试:包含1078页复杂文档,覆盖学术论文、技术报告等9大类及20余子类。
- 核心指标:
- 整体编辑距离:比Mathpix低3.2%,比GPT-5低近50%。
- 中文表格识别准确率:86.6%(超越专业工具Textin)。
- 手写内容错误率:25.2%(领先第二名14%)。
- 化学结构错误率:51.9%(同类工具普遍>80%)。
- 公式文本识别错误率:8.9%(每百字错不到1个)。
应用领域
- 科研场景:解析学术论文中的嵌套表格、复杂公式,支持RAG知识库构建。
- 教育领域:将手写笔记、试卷转换为可检索电子版,辅助视力障碍学生屏幕朗读。
- 企业服务:自动提取合同关键条款、财务报销单表格数据,减少人工操作误差。
- 化学与数学研究:将化学结构式转为SMILES格式,直接对接实验室分析工具。
项目地址
- GitHub仓库:https://github.com/alibaba/Logics-Parsing
- HuggingFace模型库:https://huggingface.co/Logics-MLLM/Logics-Parsing
- arXiv技术论文:https://arxiv.org/pdf/2509.19760
- 在线Demo:ModelScope魔搭社区
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
