LongCat-Audio-Codec : 美团开源的语音编解码方案
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
LongCat-Audio-Codec是美团LongCat团队于2025年10月17日正式开源的专用语音编解码方案,专为语音大语言模型(Speech LLM)设计。该方案通过将原始音频信号映射为语义与声学并行的Token序列,实现高效离散化处理,支持从信号输入到输出的全链路音频处理。其核心目标是为语音交互、语音搜索等场景提供低延迟、高效率的编解码能力,推动AI音频技术在智能家居、车载系统、实时翻译等领域的落地。
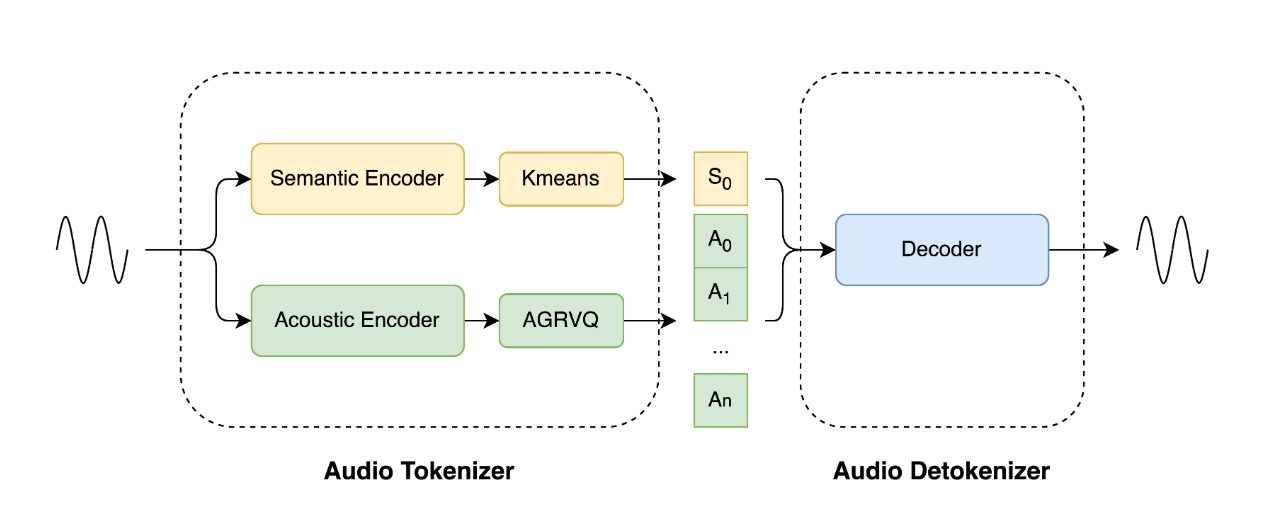
功能特点
- 语义与声学双Token并行:
- 传统编解码方案难以平衡语义与声学信息,而LongCat-Audio-Codec通过Token化技术,同时提取语音的语义内容(如文本含义)和声学特征(如音调、节奏),确保解码后的音频质量与语义准确性。
- 低延迟流式解码:
- 支持实时交互场景,如车载语音助手、实时翻译等,通过流式解码技术减少延迟,提升用户体验。
- 一站式工具链:
- 提供完整的Token生成器(Tokenizer)与Token还原器(DeTokenizer),开发者可快速集成至现有系统,无需从零构建编解码流程。
- 灵活架构与可扩展性:
- 支持定制化开发,例如针对智能音箱优化语音指令识别,或针对多语言场景训练跨语言模型。
优缺点
- 优点:
- 高效压缩与传输:Token化处理简化音频数据结构,降低带宽需求,适合网络传输。
- 提升模型性能:Speech LLM可更专注于语义理解与生成,减少对底层音频处理的依赖。
- 开源生态支持:降低语音技术应用门槛,促进开发者创新。
- 缺点:
- 极端场景适应性:对噪音干扰严重或非标准发音的语音,识别准确性可能下降。
- 长音频处理限制:虽支持长音频建模,但极端时长下可能需优化计算资源分配。
如何使用
- 在线Demo体验:
- 访问美团或HuggingFace提供的在线Demo,上传音频文件即可实时查看Token序列生成与音频还原结果。
- 预训练模型调用:
- 通过HuggingFace模型库或美团官方仓库下载预训练模型,配合API接口直接调用编解码功能。
- 集成至现有系统:
- 利用提供的Tokenizer与DeTokenizer工具链,通过配置文件调整参数(如采样率、Token长度),快速适配语音识别、合成等任务。
框架技术原理
LongCat-Audio-Codec采用双流Token化架构:
- 语义流:提取语音中的文本信息,转化为离散Token序列,供Speech LLM进行语义理解。
- 声学流:保留语音的音调、节奏等特征,转化为并行Token序列,确保解码后音频的自然度。
- 动态分辨率处理:支持可变长度音频输入,通过自适应Token划分平衡精度与效率。
- 轻量化设计:优化计算流程,减少冗余操作,适合边缘设备部署。
创新点
- 语义-声学并行Token化:
- 首次将语义与声学信息解耦为独立Token流,解决传统方案中信息丢失或混淆的问题。
- 流式解码优化:
- 通过增量式Token处理,实现低延迟实时交互,满足车载、会议等场景需求。
- 开源生态构建:
- 提供完整工具链与预训练模型,降低技术门槛,吸引开发者参与语音技术创新。
评估标准
- 压缩效率:
- 衡量Token序列对原始音频的压缩比,直接影响传输带宽需求。
- 解码质量:
- 通过客观指标(如信噪比、梅尔倒谱失真)和主观听感测试评估还原音频的清晰度与自然度。
- 实时性:
- 测试流式解码的端到端延迟,确保满足实时交互场景要求。
- 多语言支持:
- 评估跨语言场景下的语义保留与声学还原能力。
应用领域
- 智能家居:
- 提升智能音箱的语音指令识别速度与准确性,优化人机交互体验。
- 车载系统:
- 支持低延迟语音反馈,增强驾驶安全性与便利性。
- 实时翻译:
- 减少翻译延迟,提升跨语言沟通效率。
- 语音识别与合成:
- 为ASR(自动语音识别)与TTS(文本转语音)系统提供高效音频处理支持。
- 长音频处理:
- 适用于有声读物、播客等场景,实现高效编码与解码。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
