PaddleOCR-VL : 百度飞桨开源的多模态文档解析模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
PaddleOCR-VL是百度飞桨团队于2025年10月开源的多模态文档解析模型,基于文心大模型4.5架构衍生,核心参数仅0.9B。该模型专为复杂文档结构解析设计,支持文本、表格、公式、图表等多类元素的精准识别与结构化输出。在国际权威评测OmniDocBench V1.5中,PaddleOCR-VL以92.6分登顶全球第一,超越GPT-4o等百亿级大模型,成为文档解析领域的SOTA(State-of-the-Art)模型。其轻量化设计(0.9B参数)和高效推理性能(单张A100 GPU达1881 token/s)使其适用于资源受限场景,如边缘设备部署。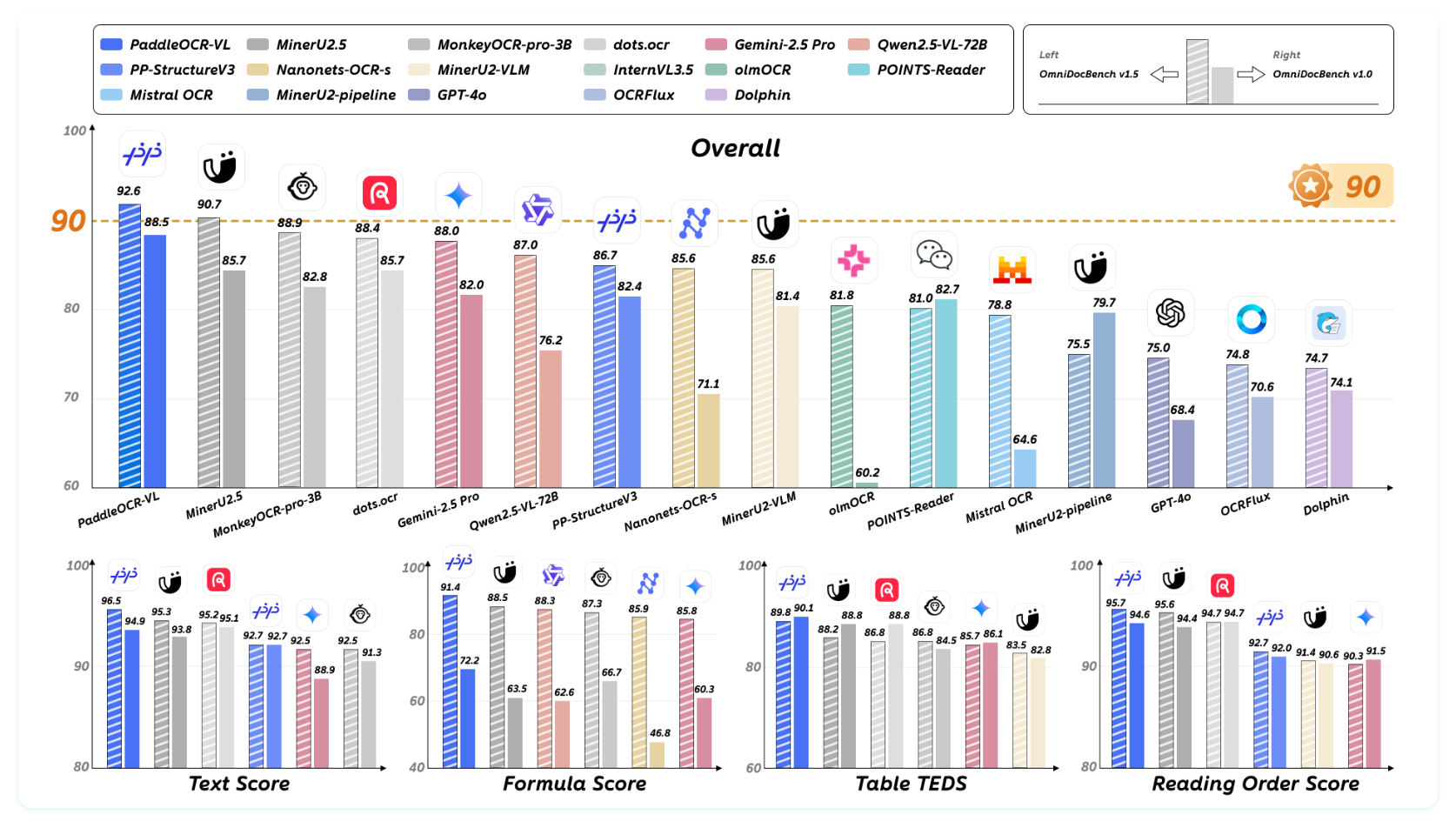
功能特点
- 多模态解析能力
- 支持印刷体、手写体、竖排文字、表格嵌套、数学公式及条形图/折线图等复杂文档元素的识别。
- 表格结构还原TEDS评分高达93.52,公式识别CDM指标达91.43,图表数据提取准确率领先。
- 多语言支持
- 覆盖109种语言,包括中文、英文、阿拉伯语、俄语等主流语言及小语种,支持全球化文档处理。
- 高精度与轻量化
- 文本识别归一化编辑距离(NormED)仅0.035,阅读顺序预测误差值仅0.043。
- 参数仅0.9B,推理速度快,较MinerU2.5提升14.2%,较dots.ocr提速253.01%。
- 结构化输出
- 支持Markdown、JSON、HTML等格式,可直接用于数据分析或知识库构建。
- 抗干扰能力
- 对模糊、倾斜、阴影遮挡的文档图像具有强鲁棒性。
优缺点
优点:
- 性能全面领先:在权威评测中超越GPT-4o、Gemini-2.5 Pro等巨型模型。
- 资源高效:轻量化设计适合端侧部署,降低计算成本。
- 开源生态:提供完整代码、预训练模型及在线Demo,开发者可快速集成。
缺点:
- 极端场景局限性:对极端手写体或艺术字体的识别仍需优化。
- 格式细微偏差:在线Demo的预览格式(如表格缩进)可能存在细微偏差。
如何使用
- 命令行调用

- Python API调用
- 本地部署
- 硬件要求:8GB+显存 + RTX 30系列以上GPU。
- 环境准备:Ubuntu 22、Python 3.11、CUDA 12.6、PaddlePaddle 3.2.0。
- 模型下载:通过HuggingFace或ModelScope获取预训练模型。
- 推理加速:支持vLLM推理服务器,提升处理速度。


框架技术原理
- 两阶段处理架构
- 第一阶段(版面分析):PP-DocLayoutV2模型定位语义区域(如标题、正文、表格)并预测阅读顺序,采用RT-DETR目标检测框架与轻量级指针网络。
- 第二阶段(细粒度识别):PaddleOCR-VL-0.9B模型基于NaViT动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型,对文本、表格、公式、图表进行结构化识别。
- 后处理模块:聚合两阶段输出,生成结构化Markdown或JSON文件。
- 动态分辨率输入
- NaViT编码器支持任意尺寸图像,减少幻觉问题。
- 模块解耦设计
- 分离版面分析与内容识别,提升复杂场景稳定性。
- 轻量化语言模型
- ERNIE-4.5-0.3B在控制计算开销的同时维持强语义理解能力。
创新点
- 架构创新:首创“布局分析+元素识别”两阶段解耦架构,兼顾布局稳定性与识别精准度。
- 数据优势:基于超过3000万高质量、多场景、多语言的训练数据,并通过困难样本挖掘持续优化。
- 性能突破:0.9B参数模型在多项基准测试中全面超越数十亿参数模型,实现精度与效率的完美平衡。
- 全栈能力:提供从多语言文本、手写体、竖排文本到复杂表格、公式、图表的解决方案。
评估标准
- 页面级理解:布局识别、阅读顺序检测。
- 元素级提取:表格、公式、图表、手写文字、历史文档的识别准确率。
- 多语言支持:109种语言的识别覆盖范围与准确率。
- 推理效率:单张A100 GPU的Token处理速度(1881 token/s)。
应用领域
- 金融行业:票据、财报的自动化解析与结构化存储。
- 教育领域:教材、试卷中的公式与图表提取,辅助数字化教学。
- 法律文档:合同、判决书的条款识别与知识图谱构建。
- 科研分析:论文中的实验数据与图表提取,加速文献综述。
- 跨国企业:多语言文档的本地化处理与格式保留转换。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
