SAIL-Embedding – 抖音联合港中文推出的全模态嵌入模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
SAIL-Embedding是由字节跳动抖音SAIL团队与香港中文大学MMLab联合研发的全模态嵌入基础模型,专为大规模推荐场景设计。该模型突破传统多模态模型仅支持图文或训练不稳定的局限,首次实现视觉、文本、音频的统一表征,并深度适配短视频平台的复杂信息结构。其核心目标是通过统一的多模态嵌入空间,提升推荐系统对富媒体内容的理解与匹配能力,在抖音真实业务场景中已验证显著效果提升。
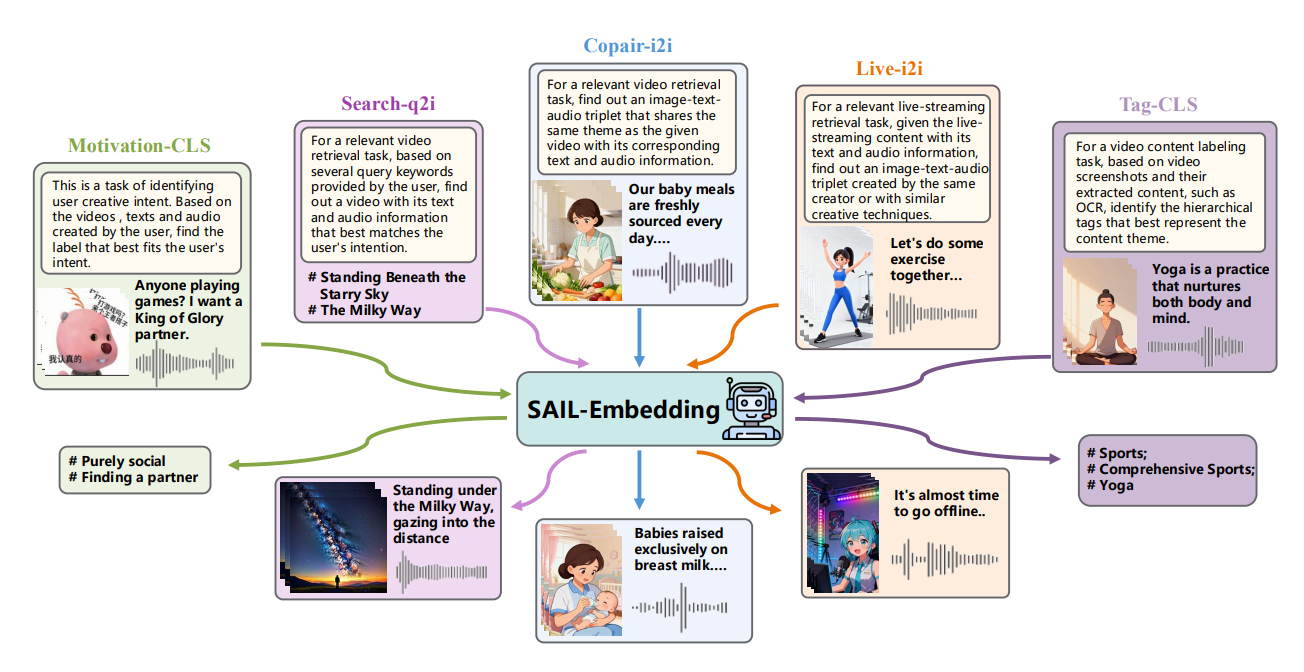
功能特点
- 全模态输入支持
覆盖短视频核心信息维度,可处理任意模态组合:- 视觉模态:视频关键帧、封面图
- 文本模态:标题、标签、OCR识别文本、ASR语音转写文本
- 音频模态:背景音乐、语音
例如,在视频检索任务中,模型能同时利用画面内容、字幕文本与背景音效,避免单一模态信息缺失导致的语义偏差。
- 跨模态理解与检索
通过统一嵌入空间实现跨模态语义对齐,支持“以文搜图”“以图搜音”等复杂检索需求,提升推荐内容的相关性。 - 动态数据策略增强训练稳定性
- 动态难负样本挖掘:通过F1分数自适应筛选难区分负样本(如主题相似但内容不同的视频),强化模型对细粒度语义差异的捕捉。
- 自适应多源数据平衡:基于Sinkhorn算法自动分配数据源权重,兼顾数据质量与多样性,缓解工业数据与开源数据的领域差异。
- 多阶段训练体系
训练分三阶段逐步深入:- 基础能力预训练:使用超10B样本的大规模多模态数据(含图文音)奠定基础语义理解。
- 任务适配优化:聚焦下游任务(如视频检索、标签分类)的高质量数据,优化任务适配性。
- 难负样本微调:引入难负样本强化模型对相似内容的判别能力。
优缺点
优点
- 全模态覆盖:突破传统模型仅支持图文或浅融合的局限,适配短视频平台复杂信息结构。
- 训练稳定性高:通过动态数据策略解决大规模训练中的噪声干扰与数据分布不均问题。
- 业务适配性强:多阶段训练体系确保模型既能理解内容语义,又能贴合推荐场景需求。
- 效果显著:在抖音真实业务场景中,用户生命周期(LT)和AUC指标显著提升。
缺点
- 计算资源需求高:全模态处理与大规模训练对硬件要求较高,可能限制中小规模团队的部署。
- 数据依赖性强:模型性能高度依赖训练数据的质量与多样性,需持续优化数据平衡策略。
- 复杂场景适配挑战:在极端复杂或长尾内容场景中,跨模态语义对齐的准确性可能受限。
如何使用(非技术向)
- 内容推荐场景
在抖音Feed流、冷启动、精选等场景中,模型通过潜入向量与嵌入离散化的语义ID赋能推荐全链路,提升内容与用户兴趣的匹配度。例如,用户观看美食视频后,模型可结合画面、字幕与背景音乐,推荐更相关的美食内容。 - 跨模态搜索
支持用户通过文本、图片或音频组合进行搜索。例如,用户上传一张海滩照片并输入“旅行攻略”,模型可返回相关旅游视频与图文内容。 - 用户兴趣建模
通过“序列到物品”蒸馏与“ID到物品”蒸馏,将用户历史行为序列与推荐系统ID表征融入多模态表示,学习用户兴趣的时序延续性与偏好信号,优化个性化推荐。
框架技术原理
- 架构设计
采用“文本+视觉+音频+融合模块”的架构:- 文本编码器:处理标题、标签等文本信息。
- 视觉编码器:提取视频关键帧与封面的语义特征。
- 音频编码器:分析背景音乐与语音的音频信号。
- 融合模块:通过双向注意力机制将多模态序列连接为单一序列,进行跨模态推理。
- 嵌入空间对齐
各模态编码器将原始特征投影至自然语言兼容的嵌入空间,并在维度与语义上对齐,确保跨模态表示的一致性。 - 推荐增强训练
- 序列到物品蒸馏:利用用户历史观看序列与目标视频的关联,学习用户兴趣的时序延续性。
- ID到物品蒸馏:对齐推荐系统中的多元化ID表征嵌入,融入用户偏好信号(如点击、关注),使嵌入结果更贴合推荐需求。
创新点
- 全模态架构突破
首次实现视觉、文本、音频的统一表征,支持任意模态组合输入,适配短视频平台复杂信息结构。 - 动态数据策略
通过动态难负样本挖掘与自适应多源数据平衡,解决大规模训练中的噪声干扰与数据分布不均问题,提升训练稳定性与可扩展性。 - 推荐增强训练体系
构建从内容理解到推荐适配的全链路优化方案,通过多阶段训练与知识蒸馏,填补学术研究与工业落地的差距。 - 业务场景验证
在抖音真实业务场景中验证技术价值,显著提升用户生命周期(LT)和AUC指标,具备极强的推广价值。
评估标准
- 离线任务性能
- Item-to-Item Retrieval(物品到物品检索):在21个涵盖内容理解、搜索与协同感知的多任务场景下,性能显著优于CLIP-based与VLM-based模型。
- Query-to-Item Retrieval(查询到物品检索):在9个涵盖检索与分类导向的多任务场景下,AUC与Recall指标领先。
- 在线业务指标
- 用户生命周期(LT):在抖音精选场景中,7天LT提升+0.158%,14天LT提升+0.144%。
- AUC增益:在抖音信息流排序模型中,由SAIL-Embedding生成的匹配特征带来AUC提升+0.08%。
- 基准测试对比
在跨模态检索领域的权威基准数据集(如MSCOCO、Flickr30K、AudioCaps)上,跨模态检索准确率(R@1、R@10)显著超越现有模型。
应用领域
- 短视频推荐
优化抖音Feed流、冷启动、精选等场景的内容推荐,提升用户兴趣匹配度与留存率。 - 跨模态搜索
支持用户通过文本、图片或音频组合进行搜索,提升搜索结果的相关性与多样性。 - 直播电商
结合商品图片、描述文本与主播语音,优化商品推荐与搜索体验,提升转化率。 - 内容理解与分类
对短视频进行多模态内容理解与分类,支持标签生成、敏感内容检测等下游任务。
项目地址
- HuggingFace模型库:https://huggingface.co/collections/BytedanceDouyinContent/sail-embedding
- arXiv技术论文:https://arxiv.org/pdf/2510.12709
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
