OmniVinci : NVIDIA推出的全模态大语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
OmniVinci是NVIDIA研究团队开发的开源全模态理解大语言模型,旨在通过统一架构实现视觉、音频和文本的跨模态理解与推理。该模型以90亿参数规模,在多项基准测试中超越同级别甚至更高级别模型,仅需0.2万亿(T)训练Token即可达到顶尖性能,数据效率是同类模型的6倍。其核心目标是通过模拟人类多感官感知模式,为多媒体处理、人机交互等领域提供高效的多模态解决方案。
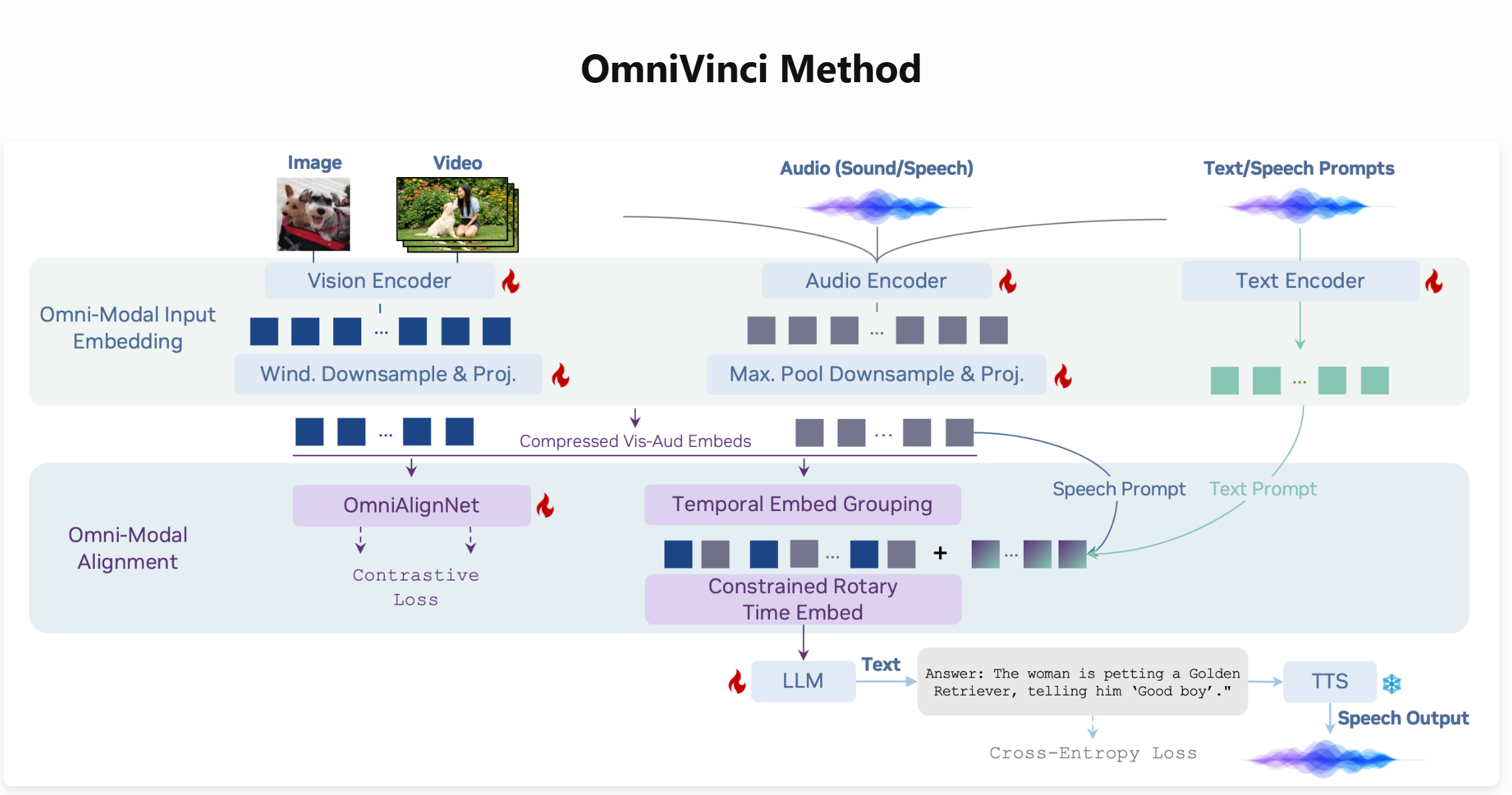
功能特点
- 跨模态理解:支持视觉(图像、视频)、音频和文本的联合解析,可准确融合不同模态数据(如理解视频中人物动作、语音内容及场景背景)。
- 时序对齐能力:通过时间嵌入分组(TEG)和约束旋转时间嵌入(CRTE)技术,精准处理视觉与音频信号的时间关系及绝对时间信息。
- 高效训练:采用两阶段训练策略(模态特定训练+全模态联合训练),结合隐式与显式学习数据,显著降低训练成本。
- 开源生态:代码、数据和网页演示均已开源,支持社区共建与扩展。
优缺点
- 优点:
- 性能卓越:在DailyOmni、MMAR、Video-MME等基准测试中,分别超越Qwen2.5-Omni等模型19.05%、1.7%和3.9%。
- 数据效率高:仅需0.2T训练Token,成本仅为同类模型的1/6。
- 应用场景广:适用于视频内容分析、机器人导航、语音转录与翻译、工业检测等领域。
- 缺点:
- 架构复杂:模型设计包含多项创新技术,训练与部署难度较高。
- 数据多样性有限:训练数据在内容和领域上仍存在局限性,需进一步扩展以提升泛化能力。
如何使用
- 在线体验:通过Hugging Face Space或项目官网访问交互式演示页面,输入文本、上传图像/视频或音频,生成跨模态理解结果。
- 本地部署:
- 在魔搭社区或Hugging Face申请免费实例,克隆项目代码库。
- 安装依赖库(如
requirements.txt中列出的工具包)。 - 运行预配置的Gradio应用(
python app.py),通过网页界面输入多模态数据并生成结果。
框架技术原理
OmniVinci采用自回归架构编码视觉和音频信号,将其对齐后输入LLM骨干网络。关键技术包括:
- OmniAlignNet:通过对比学习将视觉与音频嵌入映射到共享潜在空间,强化模态间语义对齐。
- TEG(时间嵌入分组):按时间戳将视觉与音频嵌入组织成组,编码相对时间顺序。
- CRTE(约束旋转时间嵌入):通过多尺度频率划分,实现绝对时间信息的精准标记。
创新点
- 全模态对齐机制:首次将视觉、音频和文本整合到统一潜在空间,支持可组合的跨模态理解。
- 高效数据利用:通过隐式与显式学习数据结合,减少对大规模标注数据的依赖。
- 时序处理优化:TEG与CRTE技术解决了传统模型在时间关系建模上的不足。
评估标准
- 跨模态理解能力:通过DailyOmni等基准测试,评估模型对多模态信号的联合解析与推理能力。
- 时序同步精度:测量模型对视觉与音频信号时间关系的捕捉能力(如事件先后顺序判断)。
- 数据效率:以训练Token数量和性能提升幅度为核心指标,验证模型对资源的利用率。
应用领域
- 媒体分析:自动生成视频内容摘要、转录采访语音并翻译。
- 机器人导航:通过语音提示理解环境信息,规划行动路径。
- 医疗AI:联合分析CT影像与医生口述,辅助精准诊断。
- 工业检测:实时监测设备音频与视觉信号,预警异常状态。
项目地址
- 项目官网:https://nvlabs.github.io/OmniVinci/
- GitHub仓库:https://github.com/NVlabs/OmniVinci
- Hugging Face模型库:https://huggingface.co/nvidia/omnivinci
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
