VTP : MiniMax视频团队开源的视觉生成模型预训练框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
VTP(Visual Tokenizer Pre-training)是MiniMax海螺视频团队于2025年12月开源的视觉生成模型预训练框架,专为“下一代生成模型”设计。其核心突破在于挑战传统视觉生成中“分词器(Tokenizer)规模扩展无效”的认知,通过融合表征学习与压缩重建任务,首次构建了分词器与扩散模型(Diffusion Transformer)之间的缩放曲线。实验表明,在生成模型算力不变的情况下,仅通过预训练分词器的表征空间优化,即可实现生成效果的持续提升,为视觉生成领域提供了全新的扩展路径。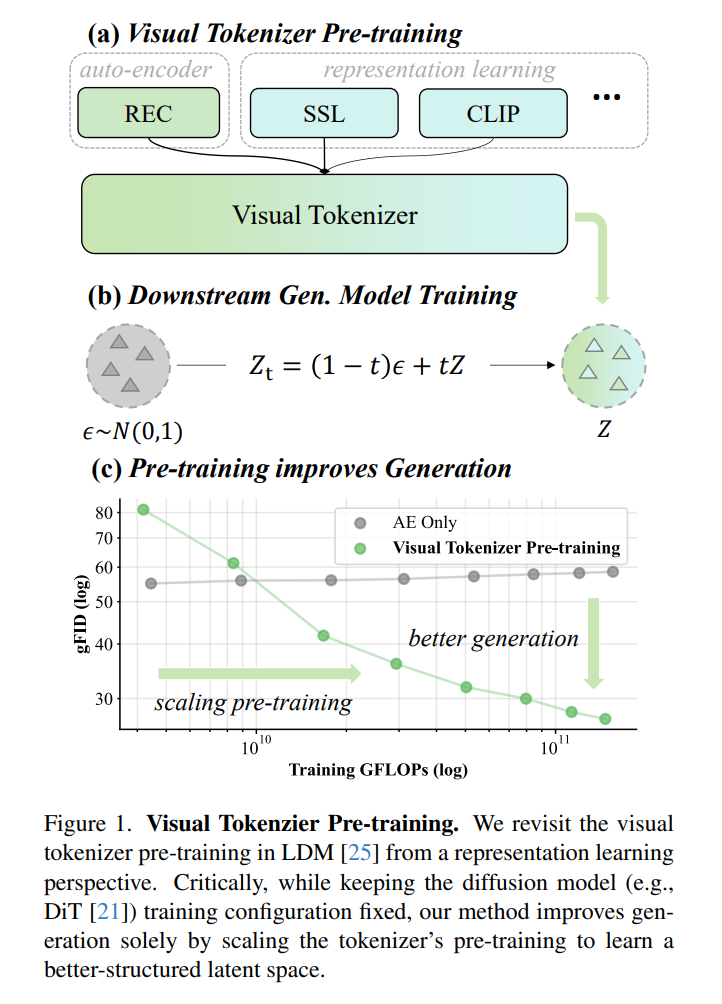
功能特点
- 理解力驱动生成:突破传统分词器仅关注像素重建的局限,通过引入语义理解(如CLIP风格的图文对比学习)和空间结构感知(如DINO风格的自监督任务),使分词器生成的潜在表示(Latents)更易被生成模型学习。
- 可扩展性:支持参数、算力、数据的动态扩展,实验显示,模型规模从Small到Large时,生成质量(gFID)从31.28降至26.12,算力增加10倍时生成性能提升65.8%。
- 工业级优化:提供端到端性能提升方案,无需修改下游生成模型(如DiT)的训练流程,仅通过前置优化分词器即可实现生成效果的倍数级改进。
- 多任务联合训练:联合优化像素重建、语义理解、空间结构感知三大目标,平衡底层细节与高层语义,避免过拟合特定场景。
优缺点
- 优点:
- 生成质量显著提升:在ImageNet零样本分类测试中准确率达78.2%,超越原版CLIP(75.5%),生成图像的语义一致性更强。
- 资源效率高:收敛速度比传统方法快4-5倍,减少训练时间和算力消耗。
- 通用性强:适用于图像生成、视频生成、3D内容生成等多场景,避免特定任务单点优化。
- 缺点:
- 训练复杂度高:需联合优化多个目标,对数据分布和采样策略敏感,需精心设计训练流程。
- 依赖大规模数据:语义理解和空间结构感知任务需大量标注或配对数据,数据获取成本较高。
如何使用
- 在线体验平台:通过Hugging Face Space或MiniMax官方Demo,上传图像/视频或输入文本描述,实时生成高质量内容,并对比传统模型与VTP的生成效果。
- 行业模板库:利用预置的电商、影视、游戏等场景模板,快速生成定制化视觉内容,支持团队协作优化。
- 可视化工具:通过交互式界面调整分词器的语义权重、结构感知强度等参数,观察生成结果的变化,辅助理解模型行为。
框架技术原理
- 多目标联合优化:
- 像素重建:保留底层细节,但权重降低(损失权重设为0.1),避免过度关注无关纹理。
- 语义理解:采用CLIP训练方式,通过图文对比学习使分词器生成的潜在表示与文本表示对齐,增强语义一致性。
- 空间结构感知:借鉴DINOv2的自监督任务,如遮罩图像预测、裁剪变换不变性,迫使模型学习图像本质特征。
- 两阶段训练策略:
- 预训练阶段:联合优化所有目标,但不使用GAN损失,专注于L1损失和感知损失,稳定训练过程。
- 微调阶段:冻结分词器主体,仅训练解码器(Pixel Decoder),并引入GAN目标提升画质。
- 动态采样策略:针对不同任务对Batch Size的差异需求(如CLIP需大Batch,重建需小Batch),设计混合采样策略,在一个大Batch中随机抽取子集用于不同任务训练。
创新点
- 首次打通分词器缩放定律:证明分词器的参数、算力、数据规模扩展可显著提升生成性能,挑战传统“分词器扩展无效”的认知。
- 理解力驱动生成:将分词器从“压缩器”升级为“表征学习模型”,通过语义理解和空间结构感知,生成更符合人类认知的视觉内容。
- 多任务联合训练框架:提出像素重建、语义理解、空间结构感知的联合优化方案,平衡底层细节与高层语义,避免过拟合。
- 工业级可扩展性:提供从Small到Large的完整模型系列,支持不同规模的应用场景,且性能随规模持续提升。
评估标准
- 生成质量:采用gFID(生成图像与真实图像的Fréchet Inception Distance)衡量生成图像的逼真度和多样性。
- 理解能力:通过Linear Probe(线性探测)评估分词器生成的潜在表示在下游任务(如分类)中的表现。
- 重建质量:使用rFID(重建图像与原始图像的Fréchet Inception Distance)衡量分词器的信息保留能力。
- 缩放特性:观察模型在参数、算力、数据规模扩展时,生成性能是否持续提升,验证缩放定律的有效性。
应用领域
- 图像生成:文生图、图生图、超分辨率重建等,生成更高质量、更语义一致的图像。
- 视频生成:视频预测、视频编辑、视频插帧等,提升视频内容的时空连贯性和语义合理性。
- 3D内容生成:从单张图像生成3D模型,或生成3D场景的纹理、光照等,增强3D内容的真实感。
- 设计行业:辅助平面设计、产品设计、UI设计等,快速生成符合语义需求的设计草图或原型。
项目地址
- GitHub仓库:https://github.com/MiniMax-AI/VTP
- 论文链接:arXiv:2512.13687
- Hugging Face集合:https://huggingface.co/collections/MiniMaxAI/vtp
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
