ArenaRL : 通义与高德开源的开放域对比式强化学习方法
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
ArenaRL 是通义 DeepResearch 团队联合高德开源的开放域智能体对比式强化学习方法,旨在解决开放域任务中因缺乏标准答案导致的判别崩溃问题。该方法通过锦标赛机制将传统绝对打分转化为组内相对排序,结合种子单败淘汰赛拓扑结构,将计算复杂度控制在线性水平(O(N)),同时保持高准确率。其核心目标是为智能体在复杂任务中找到更优解,提升推理与规划能力,并已在学术基准测试和高德地图真实业务场景中完成验证。
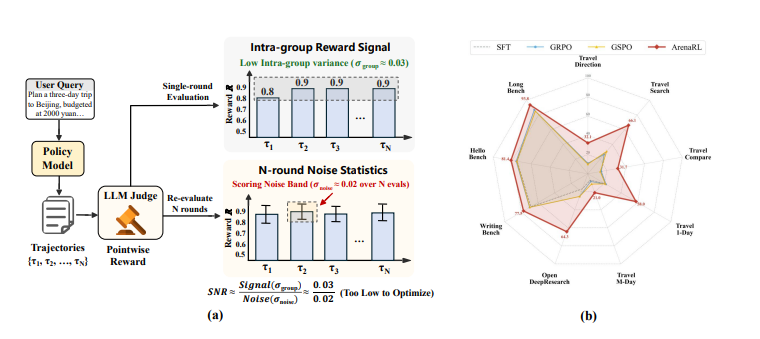
功能特点
- 对比式强化学习:通过成对比较替代绝对打分,解决开放域任务中无标准答案的瓶颈。
- 锦标赛机制与种子单败淘汰赛:构建微型“竞技场”,让智能体生成候选方案,通过高效拓扑结构平衡训练效率与效果。
- 过程感知评估:不仅评估最终结果,还审视思维链逻辑和工具调用精准度,提升推理能力。
- 双向评分协议:交换候选方案顺序评分,消除位置偏见,确保评估公正性。
- 支持多样化场景:覆盖复杂出行规划、深度信息检索、通用写作等多任务。
优缺点
- 优点:
- 高效训练:计算复杂度低,适合大规模任务。
- 强泛化能力:在多场景中表现优异,避免过拟合。
- 公平评估:双向评分协议减少偏差,提升结果可靠性。
- 缺点:
- 依赖高质量候选方案:若智能体生成的方案质量不足,可能影响对比效果。
- 复杂场景适配需调优:部分极端任务需额外调整锦标赛机制参数。
如何使用
- 准备环境:部署支持 CUDA 的 GPU 设备(如 4×H100),安装 Linux 操作系统及 Python 3.10+。
- 下载模型与数据:从项目地址获取训练框架、基准数据集(如 Open-Travel、Open-DeepResearch)及预训练模型。
- 配置任务:根据需求选择场景(如出行规划、信息检索),定义任务指令和评估标准。
- 运行锦标赛:启动锦标赛机制,让智能体生成候选方案并自动进行组内对比排序。
- 输出结果:获取最优解及推理过程分析,支持进一步优化或直接应用。
框架技术原理
ArenaRL 的核心是对比式强化学习框架,包含以下关键模块:
- 锦标赛机制:智能体针对同一指令生成多个候选方案,构建竞争组。
- 种子单败淘汰赛:通过拓扑结构将计算复杂度控制在 O(N),同时逼近全量循环赛的准确率。
- 相对排序奖励模型:将奖励建模转化为组内排序问题,避免绝对打分的局限性。
- 过程感知评估器:分析思维链逻辑和工具调用精准度,提供细粒度反馈。
- 双向评分协议:交换候选方案顺序评分,消除位置偏见。
创新点
- 从绝对打分到相对排序:首次在开放域任务中引入对比式学习,突破传统奖励模型瓶颈。
- 锦标赛机制与线性复杂度:通过种子单败淘汰赛实现高效训练,平衡效率与效果。
- 过程感知评估:深入审视推理过程,提升智能体决策质量。
- 双向评分协议:确保评估公正性,减少人为偏差。
- 全流程开源:提供训练框架、数据集和基准测试,推动社区研究。
评估标准
- 准确率:在基准测试集(如 Humanity’s Last Exam、BrowseComp)中的表现。
- 训练效率:计算复杂度(O(N))与实际训练时间对比。
- 推理能力:思维链逻辑严密性和工具调用精准度。
- 泛化能力:在多场景(出行、检索、写作)中的任务适应性。
- 公正性:双向评分协议下的结果一致性。
应用领域
- 复杂出行规划:生成符合模糊需求(如人少、有遮阴)的最优路线。
- 深度信息检索:提升长文本生成指令遵循能力,避免长度偏差。
- 通用写作:从多个候选方案中筛选出最符合要求的文本。
- 个性化推荐:筛选符合用户个性化需求(如适合约会、有江景露台)的选项。
- 开放域问答:从多个候选答案中选出最合理、有用的回答。
项目地址
- 项目官网:https://tongyi-agent.github.io/zh/blog/arenarl/
- GitHub仓库:https://github.com/Alibaba-NLP/qqr
- HuggingFace模型库:https://huggingface.co/papers/2601.06487
- arXiv技术论文:https://arxiv.org/pdf/2601.06487
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
