VoiceSculptor : 西工大联合语图智能等开源的音色设计模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
VoiceSculptor是由西北工业大学音频语音与语言处理研究组(ASLP@NPU)联合语图智能技术公司、上海玲光乍现科技及WeNet开源社区共同开源的音色设计模型。该模型基于LLaSA-3B基座模型构建,专为解决传统TTS(文本到语音)技术中音色自定义控制能力不足的问题而设计。通过自然语言指令,用户可灵活调整音色、语速、基频、情感等属性,实现高度个性化的语音合成,满足虚拟人声、交互式AI、个性化语音助手等场景需求。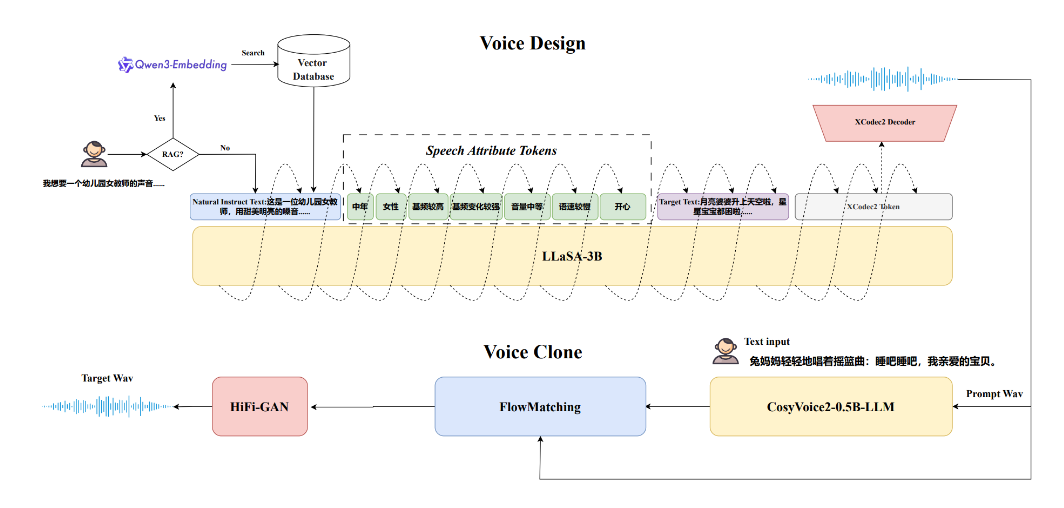
功能特点
- 自然语言指令控制:用户可通过文本描述期望的音色特征(如“年轻女性,语速适中,情感欢快”),模型直接生成对应语音。
- 细粒度属性可控:支持性别、年龄、语速、音调、音量、情感等10余种声学及语义维度的精细调节。
- 检索增强生成(RAG):集成Qwen3-Embedding-0.6B模型与Milvus向量数据库,提升对复杂指令的理解能力与泛化性。
- 级联架构设计:系统分为Voice Design(基于LLaSA-3B生成目标音色音频)与Voice Clone(基于CosyVoice2实现音色迁移)两部分,支持端到端语音合成。
- 多语言支持:训练数据以中文为主,但架构设计支持扩展至其他语言。
优缺点
- 优点:
- 高自由度:突破传统TTS仅能模仿音色的限制,支持通过自然语言定义全新音色。
- 精准控制:细粒度属性Token与联合训练策略显著提升指令遵循能力与韵律控制精度。
- 轻量化部署:仅需3B参数量与9k小时标注数据,即可在APS和RP任务上超越7B参数量的商业模型(如MiMo-Audio)。
- 缺点:
- 数据依赖:复杂情感或小众语言场景下,需额外标注数据优化性能。
- 硬件要求:检索增强生成机制需依赖向量数据库,对存储与计算资源有一定需求。
如何使用
- 访问在线Demo:通过HuggingFace Space体验交互式Demo(链接),输入自然语言指令(如“生成一位老年男性的低沉语音”)并提交。
- 调整参数:在Demo界面中修改语速、音量、情感等滑块,实时预览合成效果。
- 下载音频:满意后导出生成的音频文件,支持WAV或MP3格式。
- 集成到现有系统:若需进一步开发,可参考GitHub仓库中的API文档,通过HTTP请求调用模型服务(需自行部署或使用云服务)。
框架技术原理
- 基座模型:以LLaSA-3B为核心,通过自回归方式生成语音的梅尔频谱特征。
- 联合训练策略:将自然语言指令、细粒度属性Token(如
<gender=female>)与目标文本共同输入模型,计算交叉熵损失以优化上下文理解能力。 - 解码与还原:使用XCodec2 decoder将生成的频谱特征转换为音频波形,支持高保真语音输出。
- 检索增强机制:推理时通过Qwen3-Embedding-0.6B将指令向量化,并在Milvus数据库中检索相似指令,辅助模型生成更符合预期的语音。
创新点
- 自然语言驱动音色设计:首次实现通过文本描述直接定义音色,降低用户使用门槛。
- 属性Token随机丢弃训练:训练中以一定概率丢弃属性Token,迫使模型深度理解自然语言指令,减少对显式标签的依赖。
- 小参数量高性能:在3B参数量下达到SOTA(领域最优)性能,验证了高效架构设计的可行性。
评估标准
- InstructTTS Eval基准测试:在APS(声学参数规范)任务中,模型需精准执行12项低级声学属性(如速度、音高、音量);在RP(韵律预测)任务中,评估情感、停顿等高级韵律特征的生成质量。
- 主观听感测试:通过MOS(平均意见分)评分,由人工评估合成语音的自然度、相似度与指令遵循度。
- 泛化性测试:验证模型对域外指令(如罕见语言或复杂描述)的理解能力与鲁棒性。
应用领域
- 虚拟人声:为数字人、虚拟主播提供多样化语音风格,支持实时交互场景。
- 个性化语音助手:根据用户偏好定制助手音色,提升用户体验。
- 影视配音:快速生成符合角色设定的语音,降低配音成本。
- 辅助技术:为视障或言语障碍人群提供个性化语音合成服务。
- 教育娱乐:生成不同角色(如童话人物、历史名人)的语音,增强内容趣味性。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
