MMSI-Video-Bench : 上海AI Lab推出的空间智能视频基准
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
MMSI-Video-Bench是上海人工智能实验室InternRobotics团队于2026年1月推出的一套空间智能视频评测基准,由上海人工智能实验室、上海交通大学、香港中文大学等多所高校的研究者共同完成。该基准旨在系统性地评估多模态大模型在视频理解中的空间认知、推理与决策能力,揭示模型在真实世界复杂场景中的能力边界与瓶颈。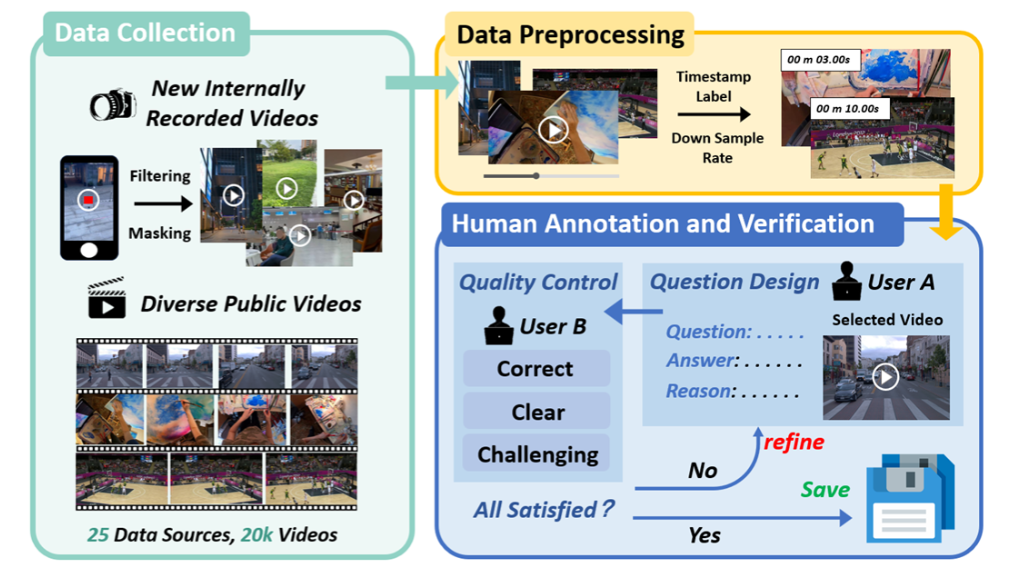
功能特点
- 全面且系统的题型设计:涵盖空间构建、运动理解、规划、预测以及跨视频推理等五大任务类型,共13个子类问题,形成完整的“感知-推理-决策”链条。
- 极具挑战性的问题设计:所有问题由11位经验丰富的3D视觉研究员精心设计,确保问题清晰准确且具有挑战性。表现最优的Gemini 3 Pro模型准确率仅为38%,与人类水平(96.4%)存在约60%的差距。
- 丰富多样的视频数据来源:数据来源于25个公开数据集及1个自建数据集,涵盖机器人操作、室内外场景、自然风光等多种类型,全面反映真实世界的复杂空间场景。
- 特定领域针对性的能力测评:可划分出室内场景感知、机器人和定位三大子基准,便于针对性地评测模型的特定能力。
优缺点
- 优点:
- 全面性:覆盖空间智能的多维度需求,系统评估模型的基础空间感知与高层决策能力。
- 挑战性:问题设计极具挑战性,有效揭示模型在真实场景中的能力短板。
- 多样性:视频数据来源丰富,涵盖多种拍摄类型和空间场景。
- 缺点:
- 高门槛:对模型的空间认知与推理能力要求极高,当前主流模型表现普遍偏低。
- 复杂性:任务设计复杂,对评测环境和数据标注要求较高。
如何使用
- 访问项目主页:通过项目官网或GitHub仓库了解基准的详细介绍、任务类型和数据集信息。
- 下载数据集:从Hugging Face数据集平台下载MMSI-Video-Bench数据集,包含视频样本和标注信息。
- 使用评测工具:参考GitHub仓库中的评测脚本和文档,利用现有工具对模型进行评测,无需编写代码即可生成评测报告。
- 分析结果:根据评测报告中的准确率、错误类型等指标,分析模型在空间智能各方面的表现。
框架技术原理
MMSI-Video-Bench基于视频的时空信息理解,从基础空间感知能力(如空间构建、运动理解)出发,进一步评测模型的高层决策能力(如规划、预测)。通过引入跨时间的记忆更新能力和多视角信息整合能力,扩展任务范畴以更真实地覆盖现实场景中的复杂情形。问题设计由资深3D视觉研究员把关,确保题型覆盖感知、推理与决策全过程。
创新点
- 全面系统的评测体系:构建了覆盖空间智能全链条的评测体系,填补了现有基准在高层决策能力评估方面的空白。
- 极具挑战性的问题设计:问题由专家精心设计,确保难度和准确性,有效揭示模型在真实场景中的能力短板。
- 丰富多样的数据来源:数据集涵盖多种拍摄类型和空间场景,全面反映真实世界的复杂性。
- 针对性的能力测评:通过划分子基准,实现对模型特定能力的精准评估。
评估标准
- 任务准确率:计算模型在五大任务类型、13个子类问题上的准确率,评估模型的整体表现。
- 错误类型分析:将错误归纳为细致定位错误、ID匹配错误、潜在逻辑推断错误、提示输入对齐错误和几何推理错误等五种类型,分析模型在不同错误类型上的表现。
- 人类-AI性能差距:对比模型与人类在专业空间推理评测中的得分,评估模型在空间认知能力上的不足。
应用领域
- 机器人操作:评估机器人在复杂场景中的空间感知与决策能力,提升自主操作水平。
- 自动驾驶:测试自动驾驶系统对道路场景的空间理解能力,增强行驶安全性。
- 虚拟仿真:为虚拟仿真环境提供空间智能评测工具,优化仿真效果。
- 智能监控:提升监控系统对异常事件的空间推理能力,实现更精准的预警。
项目地址
- 项目主页:https://rbler1234.github.io/MMSI-VIdeo-Bench.github.io/
- GitHub仓库:https://github.com/InternRobotics/MMSI-Video-Bench
- Hugging Face数据集:https://huggingface.co/datasets/rbler/MMSI-Video-Bench
- arXiv技术论文:https://arxiv.org/abs/2512.10863
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
