Ctrl-World:清华联合斯坦福推出的具身世界模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Ctrl-World是由清华大学陈建宇团队与斯坦福大学Chelsea Finn团队联合研发的可控生成世界模型,专为机器人操控任务设计。其核心目标是通过构建一个与真实环境高度对齐的虚拟训练空间,让机器人在“想象”中完成策略预演、评估与迭代,从而降低对真实物理资源的依赖,加速具身智能技术的落地。
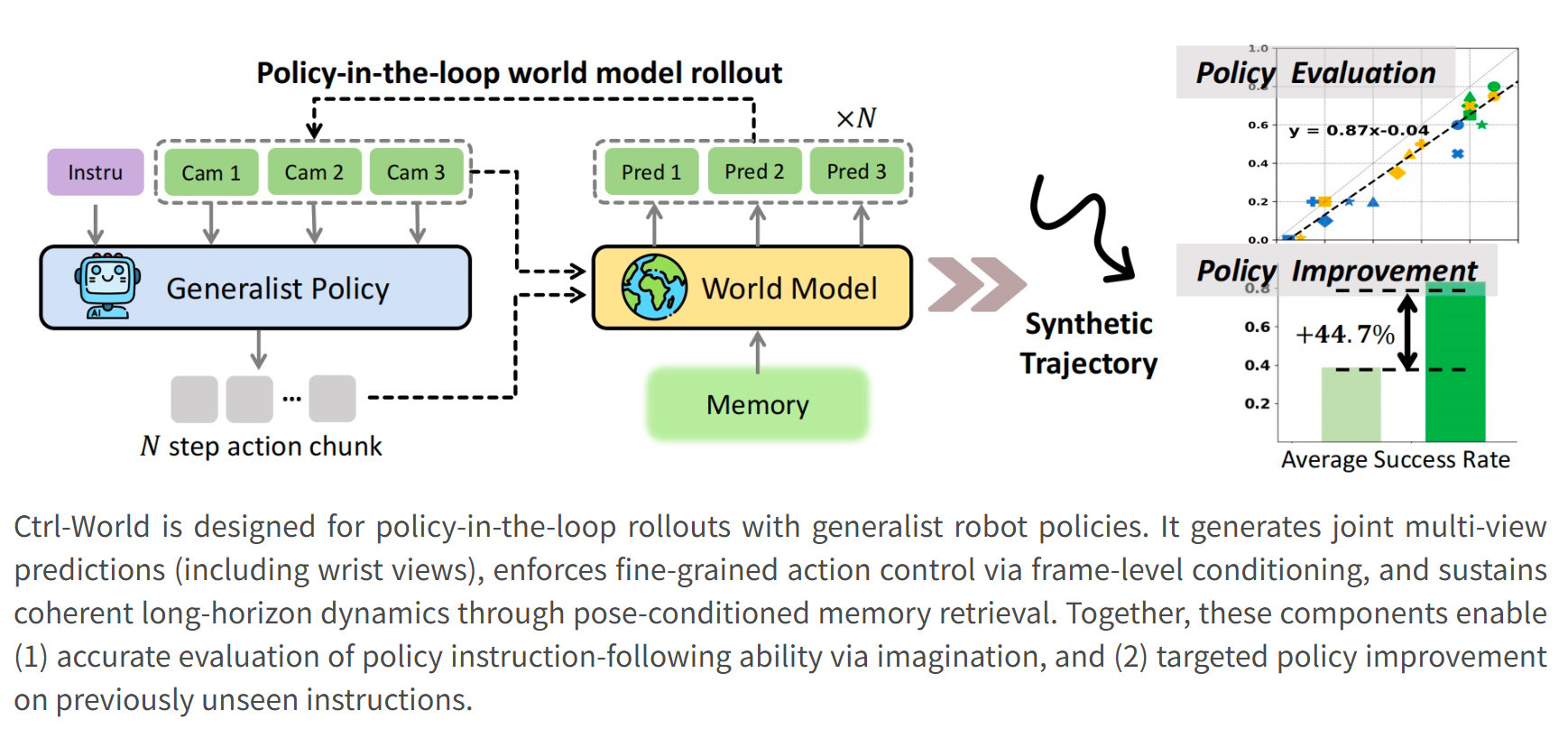
功能特点
- 多视角联合预测:支持第三人称全局视角与腕部局部视角的联合预测,降低视野盲区,提升物体交互的准确性。
- 帧级动作控制:通过绑定动作与视觉因果关系,实现厘米级精准操控,确保动作与生成画面的强一致性。
- 姿态条件记忆检索:引入姿态条件化的记忆检索机制,维持长时程动态连贯性,支持超过20秒的稳定轨迹生成。
- 零真机数据优化:无需真实物理交互,仅通过虚拟数据即可将下游任务的指令跟随成功率从38.7%提升至83.4%。
优缺点
- 优点:
- 显著降低机器人策略评估与迭代的成本,策略优化周期从“周级”缩短至“小时级”。
- 在复杂物理场景(如抓取异形物体、折叠毛巾)中展现出高泛化能力,任务成功率提升44.7%。
- 在WorldArena评测中,具身任务能力排名全球第一,视频生成能力排名第二,兼具视觉真实性与物理合理性。
- 缺点:
- 在液体倾倒、高速碰撞等任务中,虚拟模拟与真实物理规律的偏差仍需优化。
- 对初始观测的敏感性较高,若第一帧画面模糊,后续推演误差会快速累积。
如何使用
- 数据准备:基于DROID数据集(含9.5万条轨迹、564个场景)训练模型,或通过自定义数据集适配特定任务。
- 虚拟预演:在模型中输入机器人策略代码,生成多视角虚拟轨迹,评估策略在虚拟环境中的表现。
- 策略优化:根据虚拟预演结果,筛选高质量合成轨迹用于微调策略,无需真实物理交互。
- 真实部署:将优化后的策略部署至真实机器人,验证其在开放世界场景中的泛化能力。
框架技术原理
Ctrl-World基于预训练视频扩散模型(Stable Video Diffusion)初始化,通过以下技术适配为可控且时间一致的世界模型:
- 多视角输入与联合预测:将不同相机的图像在token维度拼接,联合预测所有视角的未来画面,提升空间一致性。
- 帧级动作条件控制:将动作序列转换为笛卡尔空间中的姿态参数,通过帧级交叉注意力模块绑定动作与视觉因果。
- 姿态条件记忆检索:稀疏采样历史帧,将机械臂姿态信息嵌入记忆库,检索相似姿态以校准当前预测方向。
创新点
- 动作条件化生成机制:将机械臂关节扭矩、夹爪开合度等物理参数直接注入生成过程,构建“动作-状态”的因果物理链。
- 多视图联合预测技术:隐式建模深度图与点云结构,在堆叠任务中实现91.58%的深度预测准确率,较单目模型提升35%。
- 物理引擎约束训练:在训练阶段嵌入牛顿力学定律,确保生成的环境动态与真实物理模拟器的误差极小。
评估标准
Ctrl-World在WorldArena评测中通过以下核心指标验证性能:
- 主体一致性:衡量生成物体在时序上的身份、外观与形态稳定性(得分0.8411,全球第一)。
- 轨迹精度:评估机械臂运动轨迹与真实物理轨迹的对齐度(得分0.4766,全球第一)。
- 深度准确性:测量三维空间结构的感知精度(得分0.9300,全球第一梯队)。
- 策略评估一致性:验证虚拟环境与真实物理模拟器的评估结果相关性(Pearson相关系数0.986,全球第一)。
应用领域
- 工业机器人:在复杂装配、物料搬运等任务中,通过虚拟预演降低硬件损耗与试错成本。
- 家庭服务机器人:在未知场景中(如抓取异形水杯、折叠非标准毛巾),提升策略的泛化能力与任务成功率。
- 自动驾驶:模拟极端天气或复杂路况下的车辆行为,优化决策系统的鲁棒性。
项目地址
- 论文链接:arXiv:2510.10125
- GitHub仓库:Ctrl-World官方代码库
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
