3月12日·周四 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
VAST发布Tripo P1.0:2秒生成游戏级3D模型,打破AI 3D”不可能三角”
国内3D生成领域明星初创公司VAST近日发布重磅产品Tripo P1.0,首次在原生三维空间中实现概率生成,仅需2秒即可输出专业建模师级别的3D资产,效率较现有方案提升百倍以上。用户只需输入一张图片或简单提示语,系统便能生成拓扑规整、布线合理、面数可控(500-20000面)的游戏级模型,且可直接进入实时图形流程,适用于游戏开发、仿真模拟、XR/AR等场景。
这一突破的核心在于VAST对3D生成底层范式的重构。传统AI模型将三维结构强行序列化,导致对称性丧失和误差级联。而P1.0采用”原生空间演化”架构,将顶点位置、边连接关系和面结构统一表示在同一特征空间中,通过全局几何演化实现整体涌现。VAST首席科学家曹炎培表示,P1.0让3D生成从”视觉近似”跨越到”工业资产”阶段,模糊了专业建模师与普通创作者的边界。该技术基于约5000万条高质量3D数据训练,标志着AI 3D正在成为整个AI基础设施的重要一环。
来源:微信公众号【机器之心】
华为openJiuwen开源JiuwenClaw:一键部署的国产”小龙虾”智能体
华为openJiuwen开源社区近日推出基于Python开发的智能AI Agent——JiuwenClaw,支持华为云MaaS服务和小艺开放平台无缝对接。与市面上部署复杂的同类产品相比,JiuwenClaw主打”一键安装”体验,仅需一行命令即可完成部署启动,大幅降低使用门槛。该工具定位为”随叫随到的智能管家”,能够将大语言模型能力延伸至各类通讯应用。
JiuwenClaw的核心特色包括:任务自主管理支持动态打断与追加,用户可随时调整需求;Skills自主演进机制通过执行错误和用户反馈自动优化能力;上下文压缩与卸载功能有效控制token消耗;浏览器操控可继承用户登录状态和浏览习惯。此外,该工具支持自托管部署,数据完全自主可控,并可通过小艺开放平台快速接入鸿蒙终端。openJiuwen社区此前发布的DeepAgent和DeepSearch两款智能体已双双霸榜,此次JiuwenClaw的推出进一步完善了其AI Agent生态布局。
来源:微信公众号【机器之心】
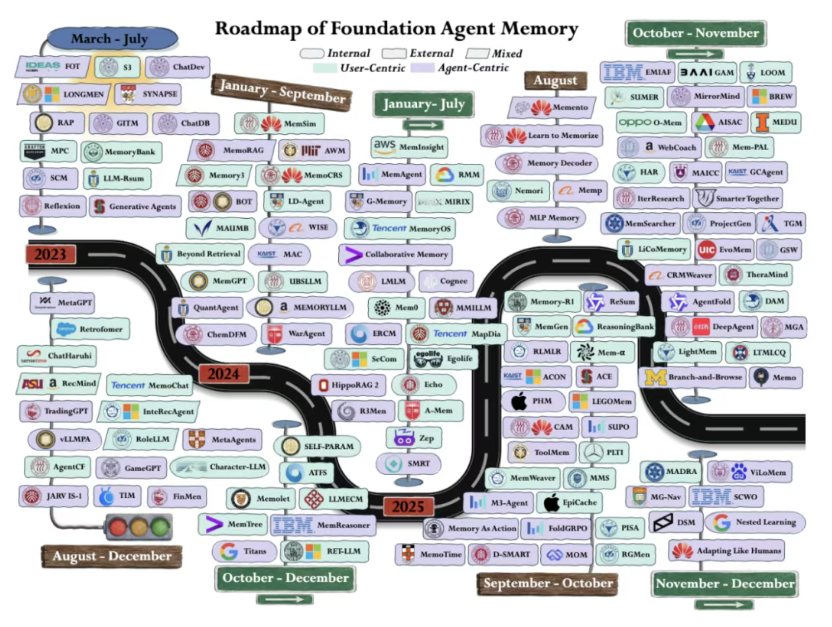
AI下半场竞争焦点转移:Agent记忆体成为新战场
随着OpenClaw(小龙虾)等智能体项目爆火,AI行业正从”参数竞赛”转向”真实应用”阶段。近日,一篇联合20余所全球顶尖高校及Meta、Google、Salesforce等工业界团队的Agent Memory系统性综述指出:当Agent从短对话走向长周期任务,核心需求不再是模型智能,而是处理复杂context和environment的系统级memory能力。
该综述将Agent Memory拆解为三个维度:存储位置(内部参数/外部数据库)、认知功能(感知/工作/事件/语义/程序记忆)和服务主体(用户/任务/Agent自身)。数据显示,2023年至2025年间,memory相关论文数量呈爆炸式增长,其中外部记忆研究增长尤为迅猛。文章指出,单纯扩大context window无法解决真实环境中信息持续累积的复杂性,Agent必须具备存储、抽象、压缩、更新和遗忘信息的真正memory机制。未来benchmark的核心将从”回答是否正确”转向”任务是否真正完成”,真实世界环境的构建将成为区分实验室模型与可部署Agent的分水岭。
来源:微信公众号【机器之心】
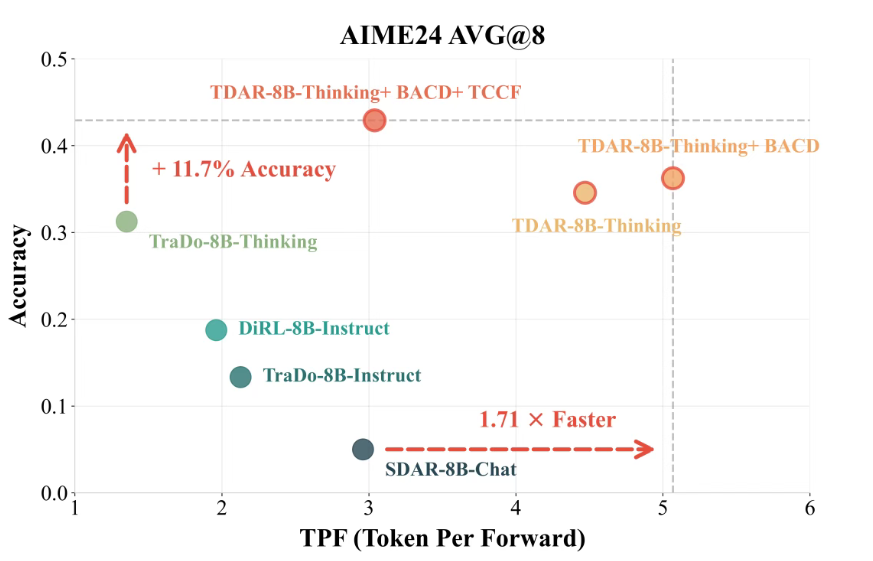
复旦北大联合美团提出TDAR框架:破解Block Diffusion速度精度悖论
复旦大学NLP实验室、北京大学知识计算实验室联合美团LongCat团队近日提出Block Diffusion语言模型测试时扩展新框架TDAR,通过”粗思考,细求证”(TCCF)范式与有界自适应置信度解码(BACD)算法,成功打破速度与精度的零和博弈。该框架使8B规模的Block Diffusion模型在AIME24等6个主流推理基准上取得最佳性能,同时实现3.04 TPF的高解码速度。
TDAR的核心创新在于双重自适应机制:BACD算法利用已生成token的平均置信度动态调整去噪阈值,并设置上下限边界防止错误累积;TCCF范式则根据推理阶段功能分配计算粒度——探索阶段使用大Block Size(16)快速铺开思维路径,验证阶段切换为小Block Size(1)精细纠错。实验显示,TDAR-8B-Thinking在AIME24上准确率较基线提升11.7%,速度提升1.71倍。该研究证明了针对推理阶段动态分配计算粒度的必要性,为并行推理模型设计提供了新思路。
来源:微信公众号【机器之心】
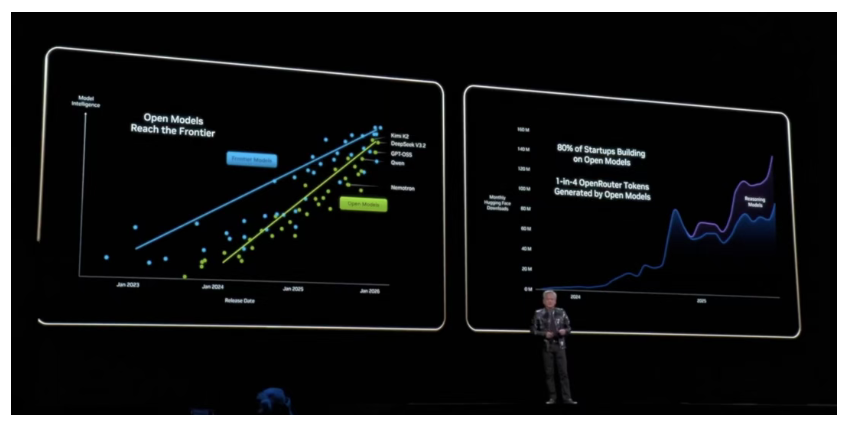
英伟达五年豪掷260亿美元,全力打造最强开源模型挑战DeepSeek
据《WIRED》报道,英伟达将在未来五年投入260亿美元用于构建开源人工智能模型,这一战略投资规模在该公司历史上前所未有。英伟达应用深度学习研究副总裁布莱恩·卡坦扎罗证实,公司正”以更加严肃的态度对待开源模型开发”。本周发布的Nemotron 3 Super拥有1280亿参数,在多项基准测试中表现优于OpenAI的GPT-OSS。
此举标志着英伟达从”卖铲人”向全栈AI巨头的战略转型。英伟达企业级生成式AI软件副总裁卡里·布里斯基表示,构建模型旨在”突破系统极限”,测试计算、存储和网络能力以指导硬件架构路线图。分析人士指出,面对DeepSeek、Qwen等中国开源模型的强势崛起,英伟达需要通过自研开源模型巩固其CUDA生态护城河,并在全球AI基础设施竞争中占据主动。目前80%的初创公司基于开源模型构建产品,开源已成为AI基础设施的关键战场。
来源:微信公众号【量子位】
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
