LTX-2.3 : Lightricks 开源的最新一代视频生成模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
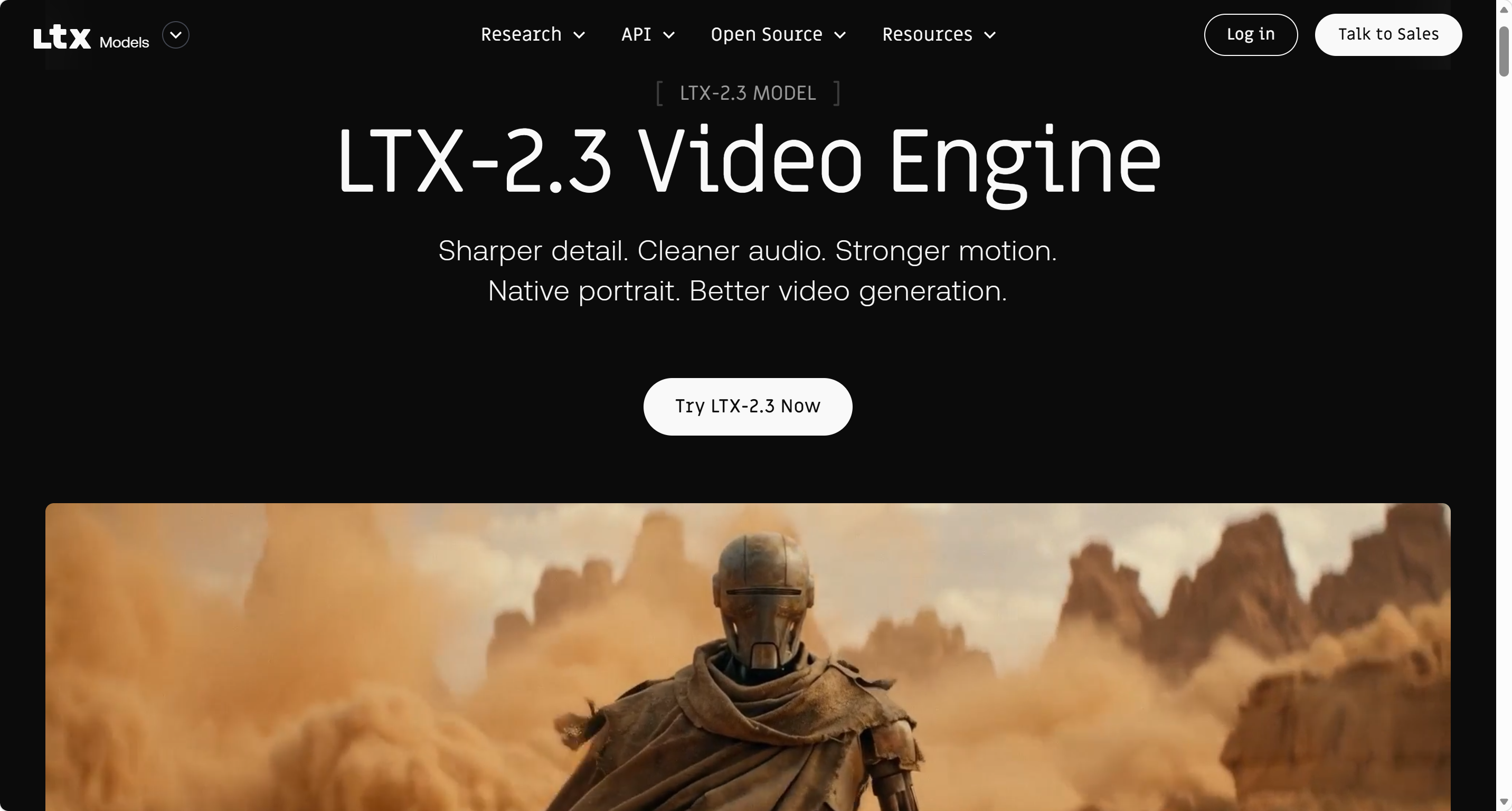
LTX-2.3 是 Lightricks 于 2026 年 3 月发布的开源视频生成模型,基于 Diffusion Transformer (DiT) 架构,拥有约 220 亿参数。作为业界首批能够在单一统一架构中同时生成同步音频和视频的开源模型之一,LTX-2.3 支持文本、图像、音频三种输入方式生成视频,最高可输出 4K 分辨率,并原生支持 9:16 竖屏格式和 24/48FPS 帧率选择。其核心目标是为创作者提供高效、灵活且高质量的视频生成工具,满足从社交媒体内容到专业影视制作的多场景需求。
功能特点
- 多模态生成:支持文本生视频(Text-to-Video)、图像生视频(Image-to-Video)、音频驱动视频(Audio-to-Video)三种核心生成方式。
- 音视频同步:原生支持环境音、音效和对话的同步生成,确保声画完美匹配。
- 高分辨率输出:最高支持 4K 分辨率,帧率可达 24/48FPS,画面细节锐利,运动自然。
- 原生竖屏支持:新增 9:16 竖屏格式,适配短视频平台和社交媒体内容创作。
- 灵活帧率选择:支持 24FPS 电影感和 48FPS 流畅运动两种帧率模式。
- 视频延展与重拍:提供视频延长(extend-video)和片段重生成(retake-video)功能,单次最长生成 20 秒视频。
- 快速生成模式:针对效率场景提供加速版本,如 text-to-video fast 和 image-to-video fast。
- LoRA 微调支持:允许用户在本地进行 LoRA 适配器训练,实现定制化模型微调。
- 配套超分工具:提供 2x/1.5x 空间超分和 2x 帧率提升的后期处理模型。
- 本地桌面编辑器:同步推出 LTX Desktop 开源视频编辑器,基于 LTX-2.3 引擎,完全本地运行无需云端。
优缺点
- 优点:
- 质量接近闭源付费模型:画面细节锐利,运动自然,音频同步体验领先。
- 开源免费:模型权重完全开放,支持商业使用,降低创作成本。
- 硬件优化好:通过 FP8 + GGUF 量化,低配设备(如 8G 显存)也能运行。
- LoRA 微调快:1 小时内即可完成风格或动作的定制化训练。
- 缺点:
- 原生版显存需求较高:推荐 12GB+ 显存设备,低配设备需依赖量化版本。
- 复杂多主体场景提示词仍需优化:在处理多个主体或复杂空间关系时,提示词需更精确。
- 音频在非人声部分偶尔有小瑕疵:如环境音的细节表现仍有提升空间。
- 绝对画质一致性上:与顶级闭源模型(如 Kling、Veo 3)仍有微弱差距。
如何使用
- 在线使用:
- 访问 LTX Studio 官方在线平台,支持文本生成视频和图像生成视频功能。
- 通过简单的网页界面输入提示词或上传参考图,选择视频参数(如分辨率、帧率、时长),点击生成即可获得视频。
- 本地使用:
- 下载 LTX Desktop 开源视频编辑器,基于 LTX-2.3 引擎,完全本地运行,无需云端依赖。
- 在编辑器中直接生成、编辑和导出视频,支持非线性视频编辑与设备端 AI 生成结合。
- ComfyUI 支持:
- 对于习惯使用 ComfyUI 的用户,LTX-2.3 提供了完整的自定义节点支持,包含文生视频、图生视频和多阶段生成的参考工作流。
- 通过 ComfyUI Manager 直接安装内置的 LTXVideo 节点,快速搭建自己的生成流程。
框架技术原理
- DiT 扩散 Transformer 架构:
- 将扩散模型与 Transformer 结合,通过迭代去噪过程生成高质量视频。
- 扩散组件负责从噪声中逐步生成帧序列,确保细节的保真度。
- Transformer 组件使用多头注意力机制,捕捉长序列中的模式,如人物动作的连续性或背景的稳定。
- 全新 VAE 变分自编码器:
- 重新训练的 Variational Autoencoder 大幅改善编码-解码质量,显著提升画面锐度、纹理细节和面部特征清晰度。
- 解决前代高分辨率下细节模糊的问题,使生成的视频在特写和高分辨率渲染中表现出色。
- 原生音频生成模块:
- 集成音频生成子网络,实现音视频端到端同步生成。
- 支持从音频输入驱动视觉内容生成,确保声画同步。
- 多模态条件注入:
- 通过不同的条件编码器将文本、图像、音频三种模态输入统一映射到潜在空间,实现灵活的多模态控制。
- 蒸馏加速版本:
- 提供 distilled 蒸馏版模型,通过知识蒸馏技术压缩模型规模,在保持质量的同时提升推理速度。
- LoRA 低秩适配:
- 支持 Low-Rank Adaptation 技术,允许用户在预训练模型基础上快速注入特定风格或概念,实现低成本定制化。
- 超分辨率后处理:
- 配套独立的超分模型,采用空间上采样(2x/1.5x)和帧率插值(2x)技术,对生成视频进行二次优化。
创新点
- 音视频同步生成:
- 首次在开源模型中实现音视频端到端同步生成,无需后期拼接,确保声画完美匹配。
- 原生竖屏支持:
- 新增 9:16 竖屏格式,直接适配短视频平台和社交媒体内容创作需求。
- 4 倍扩容文本连接器:
- 文本编码器容量扩大 4 倍,显著提升提示词理解能力,尤其擅长处理复杂的多主体场景和空间关系描述。
- 改进版图生视频:
- 重新训练图生视频模块,减少“Ken Burns 效应”(静态缩放平移),消除静止视频,提高从输入帧到输出的视觉一致性。
- 升级版音频声码器:
- 更换为改进版 HiFi-GAN 声码器,支持 24kHz 立体声,音画对齐更紧,随机噪声和意外静音更少。
- LoRA 微调支持:
- 提供完整的 LoRA 微调工具链,允许用户训练自己的风格或动作适配器,实现个性化定制。
评估标准
- 生成质量:
- 采用 FID(Fréchet Inception Distance)指标衡量视频画面逼真度。
- 通过主观评价测试音频同步效果和整体视听体验。
- 任务准确率:
- 在复杂提示词理解、多主体场景生成、音频驱动视频生成等任务上评估模型准确性。
- 推理效率:
- 测试不同硬件环境下的推理速度,包括单卡和多卡并行性能。
- 资源占用:
- 评估模型在不同分辨率和帧率下的显存占用和内存消耗。
- 用户反馈:
- 收集社区和实际应用中的用户反馈,评估模型易用性和实用性。
应用领域
- 内容创作:
- 快速生成短视频素材,大幅缩短从创意到成品的时间。
- 教育:
- 将抽象概念可视化,生成带有准确视觉演示的讲解视频。
- 营销:
- 批量生成产品展示视频,在保持电影级质量的同时将制作效率提升 10 倍。
- 游戏开发:
- 为游戏生成动态背景和过场动画,支持实时渲染需求。
- 影视制作:
- 辅助生成分镜脚本、特效预览等,降低前期制作成本。
- 独立开发:
- 为应用或网站生成动态背景和交互元素,提升用户体验。
项目地址
- 项目官网:https://ltx.io/model/ltx-2-3
- Hugging Face:https://huggingface.co/Lightricks/LTX-2.3
- GitHub:https://github.com/Lightricks/LTX-2
- arXiv 技术论文:https://arxiv.org/abs/2601.03233
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
