GLM-5.1 : 智谱推出的最强开源模型,8小时长程任务执行
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
GLM-5.1是智谱于2026年4月8日正式发布的开源大模型,被誉为全球首个在真实工程任务中验证8小时持续工作能力的开源模型。其突破了传统模型分钟级交互的局限,能够在单次任务中自主规划、执行、修复并交付完整的工程级成果,标志着AI从“回答问题”向“完成项目”的范式转变。该模型在代码能力、长程任务执行和工程化应用上实现质的飞跃,成为国产大模型追平全球顶尖水平的里程碑。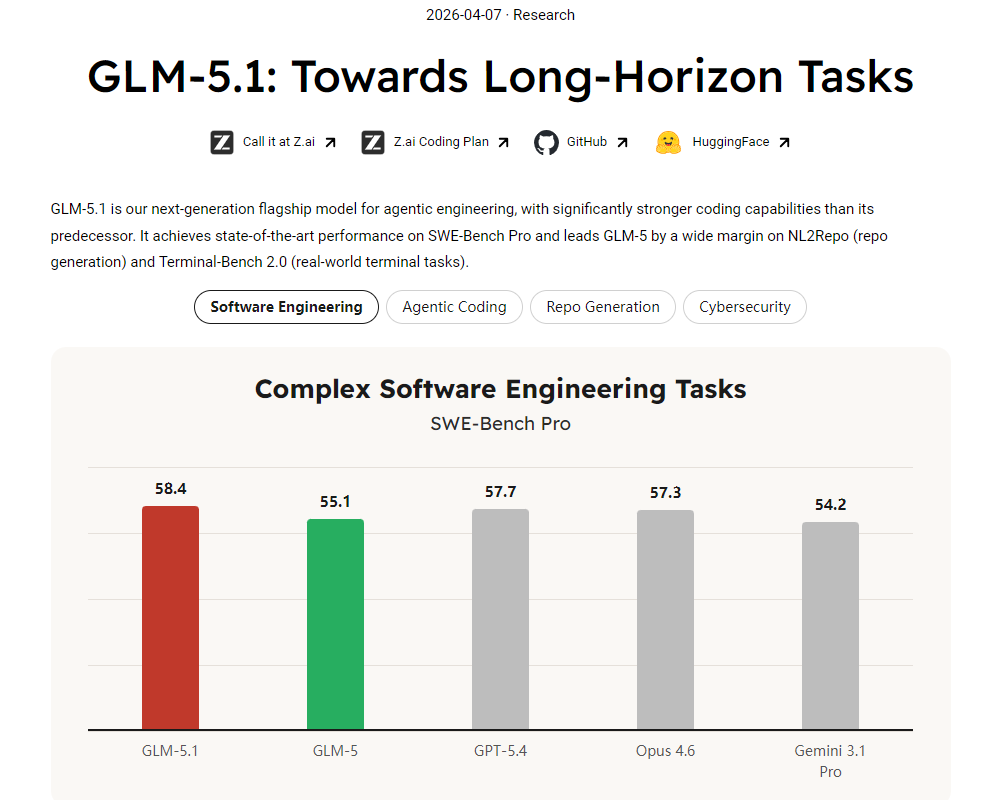
功能特点
- 8小时长程任务能力
GLM-5.1可独立持续工作8小时,期间无需人工干预,自主完成复杂工程任务。例如,在8小时内从零构建完整的Linux桌面系统,包含窗口管理器、状态栏、应用程序等4.8MB代码,并自动生成回归测试用例。 - 代码能力全球领先
在SWE-bench Pro基准测试中,GLM-5.1以58.4分超越Claude Opus 4.6,成为首个在该测试中登顶的国产模型。其代码生成能力接近全球顶尖水平,支持多语言开发、Vibe Coding(语音驱动编程)及代码调试优化。 - 智能体(Agent)优化能力
模型具备“实验→分析→优化”的完整闭环能力,可自主拆解复杂任务、调用工具、修复错误并迭代优化。例如,在GPU内核优化任务中,GLM-5.1通过24小时持续迭代,实现3.6倍几何平均加速比,显著高于传统方法。 - 长上下文与多工具协同
支持202K上下文窗口,可稳定追踪长时间跨度的任务状态。在多工具调用场景中,模型能无缝衔接代码编写、环境调试、API对接等环节,减少断链风险。
优缺点
优点
- 工程化能力突出:首次将AI交付单位从“回答”升级为“项目”,可替代初级工程师完成重复性工作。
- 性价比高:输入成本仅为Claude Opus的1/5,输出成本为1/7.8,价格对齐海外头部厂商。
- 开源生态友好:采用MIT许可证,参数规模最大且限制最少,支持企业与开发者自由商用。
缺点
- 推理与上下文长度待提升:在复杂逻辑推理和超长文本处理上,仍落后于Gemini 3.1 Pro等模型。
- 硬件依赖较强:需结合昇腾算力实现Layer级MoE均衡,普通GPU部署可能面临性能瓶颈。
如何使用
- 在线交互
登录智谱开放平台,进入GLM-5.1专属页面,选择“在线交互”模式,输入自然语言指令即可获取生成结果。例如,要求模型“构建一个包含用户登录功能的Web应用”,它可自主完成代码生成、测试用例编写及部署脚本。 - 本地部署
通过Docker容器或本地环境安装GLM-5.1,结合OpenClaw等工具链实现自动化任务执行。用户仅需配置任务目标(如“优化数据库查询性能”),模型即可自动规划步骤并执行。 - 第三方工具集成
在Claude Code、OpenClaw等平台中,通过修改配置文件将默认模型切换为GLM-5.1。例如,在Claude Code的settings.json中,将ANTHROPIC_DEFAULT_OPUS_MODEL和ANTHROPIC_DEFAULT_SONNET_MODEL均设置为glm-5.1。
框架技术原理
GLM-5.1采用混合专家架构(MoE),参数总量达744B,但每次推理仅激活40B参数(约5%)。其核心创新包括:
- Layer级MoE均衡:通过框架层辅助均衡损失和Token级负载优化,解决传统MoE在GPU上的专家过热/过冷问题,推理吞吐量提升30%。
- Slime异步强化学习框架:自研的RL训练框架,支持模型在长程任务中动态调整策略,减少局部最优陷阱。
- DeepSeek Sparse Attention:优化长上下文处理效率,在保持202K窗口的同时降低部署成本。
创新点
- 长程任务范式突破
首次定义“有效工作时长”为AI能力核心指标,推动模型从“对话陪聊”向“任务型Agent”转型。 - 自主优化闭环
模型可像人类工程师一样,通过“实验→分析→优化”循环持续改进成果,例如在向量数据库优化中主动切换算法策略。 - 开源生态领导力
以MIT许可证发布全球最大参数开源模型,打破海外闭源模型的技术垄断,推动AI平民化。
评估标准
GLM-5.1的性能通过以下基准测试验证:
- SWE-bench Pro:衡量模型修复真实GitHub仓库Bug的能力,得分58.4(超越Claude Opus 4.6)。
- Terminal-Bench 2.0:测试模型操作命令行解决问题的能力。
- NL2Repo:评估从零构建完整代码仓库的能力。
- KernelBench Level 3:验证模型在GPU内核优化中的持续迭代能力,实现3.6倍加速比。
应用领域
- 软件开发:自动化构建Web应用、数据库、桌面系统等,显著缩短开发周期。
- 高性能计算:优化GPU内核、机器学习模型训练等计算密集型任务。
- 企业服务:搭建自动化智能体,实现数据采集、文档整理等7×24小时无人值守任务。
- 科研领域:快速生成行业手册、实验报告等结构化文档,例如将研究资料转化为灵巧手行业手册,耗时从1周缩短至2小时。
项目地址
- 官方平台:智谱开放平台(https://www.zhipu-ai.cn)
- GitHub仓库:未直接提供模型代码,但开源了Slime强化学习框架及相关工具链(https://github.com/ZhipuAI)。
- 模型聚合平台:OpenRouter(https://www.openrouter.ai)支持GLM-5.1的API调用与价格对比。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
