Llama 3.1—— Meta最新发布的最强开源AI模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Llama 3.1的主要介绍
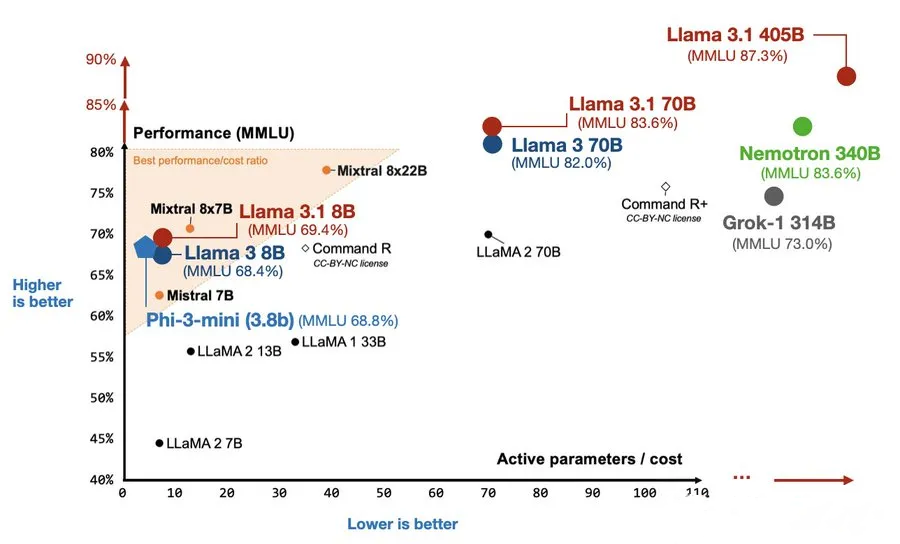
Llama 3.1是Meta公司最新发布的开源AI模型,被誉为史上最强开源LLM模型。该模型包含80亿、700亿和4050亿参数规模的版本,具有显著的上下文长度提升和多语言支持能力。特别地,其405B版本在多项基准测试中展现出与GPT-4等先进模型相媲美的性能,甚至在某些方面超越它们。Llama 3.1的发布被认为是开源AI领域的一个重要里程碑,它将推动多个行业和应用领域的发展。


Llama 3.1的功能特点
- 多尺寸模型:提供8B、70B和405B三种参数规模的模型,满足不同应用场景的需求。
- 长上下文长度:最大上下文长度提升至128K,支持更复杂的任务和更长的文本生成。
- 多语言支持:支持包括英语在内的八种语言,拓宽了其应用场景。
- 编程与数学能力:展现出优秀的编程辅助和数学问题解决能力。
Llama 3.1的优缺点
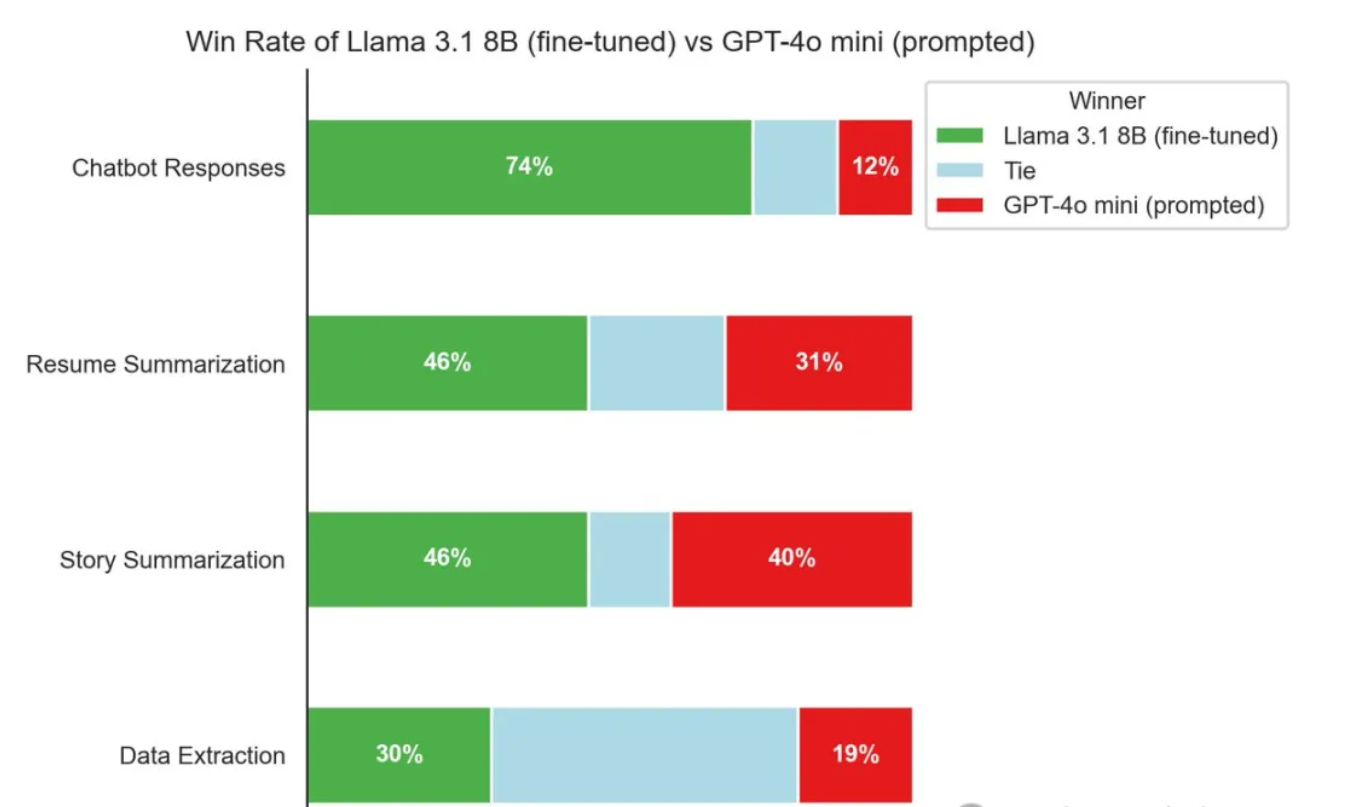
- 优点:强大的学习与推理能力,支持多语言,长文本处理和对话能力强,可应用于多种场景如编程助手、数学问题解决等。
- 缺点:虽然模型表现出色,但仍可能存在对某些特定领域知识理解不足的问题,并且对于非英语语言的支持可能还有待提升。
Llama 3.1的主要应用场景
- 多语言交流:支持八种语言,可用于多语言环境下的交流。
- 智能编程:辅助开发者编写高质量代码,提高编程效率。
- 数学教育:帮助解决复杂的数学问题,提升教育质量。
如何使用Llama3.1
- 下载与安装:用户可以从Meta提供的官方渠道下载Llama 3.1模型,并根据指南进行安装。
- API调用:通过提供的API接口,用户可以轻松调用Llama 3.1进行文本生成、推理等任务。
- 定制与微调:用户可以根据自己的需求对模型进行微调,以适应特定领域或任务。
Llama 3.1的训练方法
- 数据预处理:使用超过15万亿个Token的数据进行预训练,包括多种语言的高质量数据。
- 模型训练:采用Decoder-only的Transformer架构,并引入分组查询注意力(GQA)机制提高效率。在H100-80GB的GPGPU上进行训练,并使用数据并行、模型并行和管道并行等加速技术。
- 微调与优化:通过有监督微调(SFT)、拒绝采样、近端策略优化(PPO)和直接策略优化(DPO)的组合微调算法对模型进行优化。
Llama 3.1的框架结构
- 基于标准的Transformer解码器架构进行改进,包括更高的效率和更好的性能。
- 引入分组查询注意力(GQA)机制以提高Inference速度。
- 使用RoPE(Rotary Position Embedding)位置编码以支持更长的上下文长度。
Llama 3.1的创新点
- 长上下文长度:通过增加上下文长度至128K,提升了模型的表达能力和适用范围。
- 多语言支持:支持八种语言,增强了模型的通用性和灵活性。
- 高效训练技术:采用先进的训练堆栈和并行加速技术提高训练效率。
- 强大的推理能力:在多项基准测试中展现出与先进模型相媲美的推理性能。
Llama 3.1的评估标准
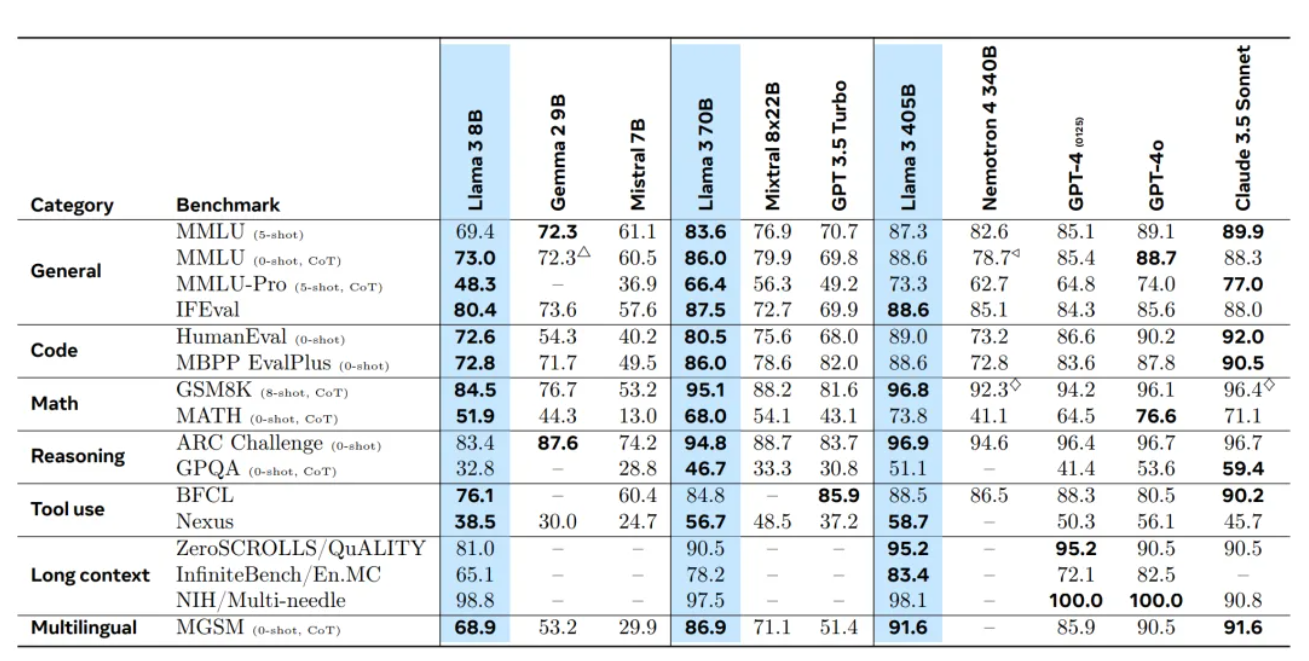
- 通过多个基准测试对Llama 3.1进行评估,包括数学能力、推理能力、长文本处理等方面的测试。结果显示Llama 3.1在多个领域展现出强劲的性能。
Llama 3.1的影响
- 推动开源AI发展:作为开源模型,Llama 3.1的发布将推动开源AI领域的发展,为研究者和开发者提供强大的工具。
- 多领域应用:Llama 3.1有望在多语言交流、智能编程、数学教育等多个领域发挥重要作用。
- 促进创新:通过提供强大的开源工具,鼓励开发者和研究者进行创新应用和开发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
